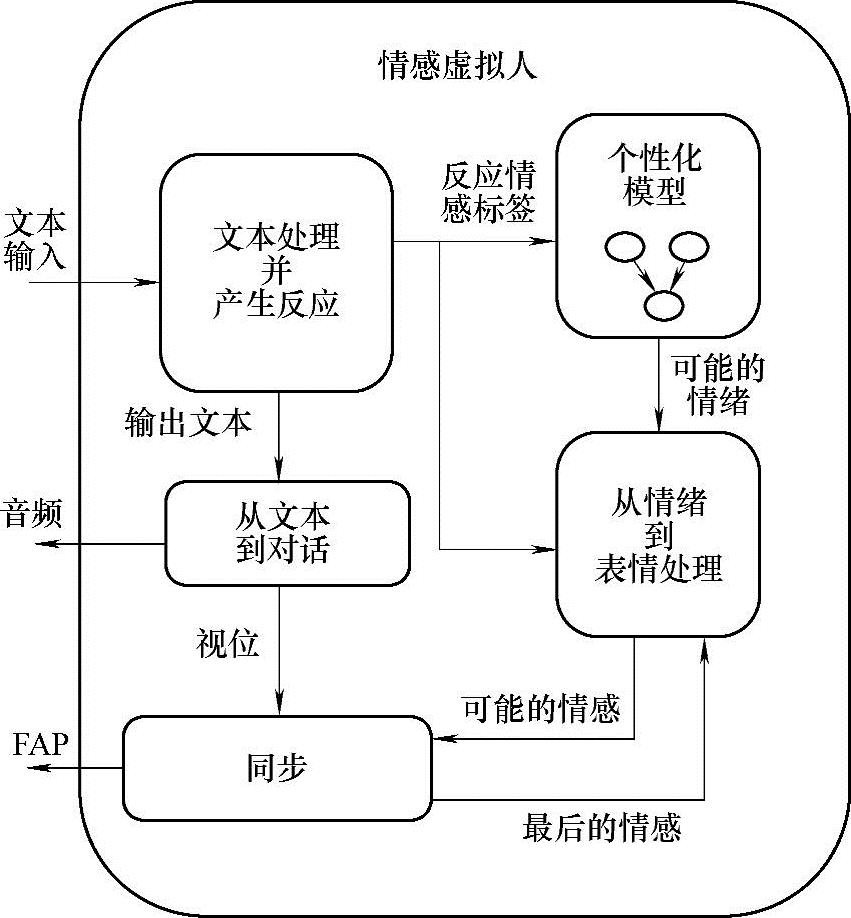
在本节中,将介绍情感虚拟人的结构。图7-17显示了系统中的各部分,以及它们之间的交互关系。对于表情的个性化体现,使用MPEG-4和应用人脸动画参数(FAP)的实时人脸动画系统。
对于未来的人机交互系统,可以考虑采用会话机器人的形式,例如Chat-robot ALICE(聊天机器人ALICE)。ALICE使用人工智能标记语言(AIML),这是一种基于XML的语言,可以定义一个对话数据库。如果首先定义了AIML数据库,以后就可以尝试将情感标签(Tag)植入到回答中。每一个情感标签都被赋予一个概率值。这些情感的标签被传送到BBN的个性化模型上。而此个性化模型,依赖于现有的情绪和输入的情感标签来更新情绪。因为情绪随着时间的转移是相对稳定的,这种情绪的转换不是一个频繁的任务。根据个性化模型的输出,对情绪进行处理后决定下一个情感状态。这种处理过程决定了可能出现的情感状态的概率。虽然系统在对话中使用了情感标签来改变基于情绪和个性化的情感,但是仍旧可以将模型与情感推理机(Emotion Reasoner)联系起来。此情感推理机可以对情感的评估提供类似的标签。个性化模型和情绪模型可以脱离于得到它们的过程来处理情感标签。同步模块(Synchronization Mod-ule)分析了前一个可视的人脸表情和情绪处理过程的输出概率。这决定了表情将以合适的时间包络(Time Envelopes)来渲染。同样,就可以得到来自于视位的唇部运动,而唇部的运动是由从文本到语音引擎(Text to Speech Engine,TTS engine)产生的。最后,系统将各函数功能进行组合,从而输出脸部动画参数,来描述“带有表情的对话”。我们使用参考文献[22]中描述的技术来进行研究。一个独立的脸部动画模块可以将语音翻译成同步中的FAP。
 (https://www.daowen.com)
(https://www.daowen.com)
图7-17 虚拟人情感系统框图
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。





