一个完整的基于特征迁移经典方法在设计过程中主要包含以下几个操作[12]。
1.分布差异度量(distribution difference metric)
减少源域和目标域样本的分布差异是特征转换的一个主要目的。因此,如何有效地度量域之间的分布差异或分布相似性是一个非常重要的问题。为解决该问题,最大平均差异[13]的测量方法被广泛应用于各个迁移学习领域,其公式如下:
通过该方法我们可以很容易地计算出MMD,MMD通过计算RKHS样本平均值的距离来量化分布差异。值得注意的是,上述KMM实际上是通过最小化域之间的MMD距离来生成样本的权重。
2.特征增广
特征增广(feature augmentation)操作广泛应用于特征变换中,尤其是在基于对称特征的方法中。有多种方法能够实现特征增广,例如特征复制和特征叠加。为了更好地理解,我们从基于特征复制的简单迁移学习方法开始介绍。
Daum[14]提出了一种简单的域适应方法,即特征增广方法(feature augmentation method,FAM)。该方法通过简单的特征复制来对原始特征进行转换。具体来说就是在单源迁移学习场景中,特征空间被扩充到其原始大小的3倍。新的特征表示包括一般特征、源特定特征和目标特定特征。需要注意的是,对于转换后的源域样本,它们的目标特定特征被设置为零。同样地,对于转换后的目标域样本,它们的源特定特征也被设置成零。FAM的新特征表示如下:
其中,ΦS和ΦT分别为从源域和目标域到新特征空间的映射。最终的分类器是在转换的有标签样本上训练的。这种扩增方法其实是多余的,换句话说,以其他方式(用更少的维度)扩充特征空间可能会产生具有竞争力的效果。FAM的优势在于其特征扩展具有简洁的形式,从而带来了一些优秀的特性,例如对多源迁移学习场景的泛化。Daum等人[15]提出了FAM的扩展,即利用没有标签的样本来进一步促进知识从源域到目标域的转移。
FAM在以下数据集上的序列执行标记任务(命名实体识别、浅解析或词性标记)。
(1)ACE-NER。使用来自2005自动内容提取任务的数据,将自己限制在命名实体识别任务。2005年ACE数据来自6个域:广播新闻(bn)、广播对话(bc)、新闻专线(nw)、网络日志(wl)、Usenet新闻(un)和转换电话语音(cts)。
(2)CoNLL-NE。与ACE-NER类似,这是一个命名实体识别任务。区别在于:使用2006ACE数据作为源域,使用CoNLL 2003 NER数据作为目标域。
(3)PubMed-POS。词性标注问题,源域是Penn Treebank的华尔街日报部分,目标域是PubMed。
(4)CNN-Recap。其源域是新闻专线,目标域是ASR系统的输出。
(5)Treebank-Chunk。这是一个基于来自Penn Treebank的数据的浅解析任务。这些数据来自各种各样的域:标准的WSJ域、TIS交换机域和Brown语料库。
(6)Treebank-Brown。这与Treebank-Chunk任务相同,只是将所有Brown语料库视为一个单一域。在所有情况下(除了CNN-重述)都使用了大致相同的特征集,在某种程度上进行了标准化:词汇信息(单词、词干、大小写、前缀和后缀),地名词典的成员资格等。
如表3.4所示,前两列指定了任务和域。对于只有一个源域和目标域的任务只在目标域中报告结果。对于多域适应任务报告目标域的每个设置的结果。可以发现,在暂时不考虑Treebank-Chunk任务中的“br-∗”域,Daum采用的算法总是表现最好。在排除“br-∗”的情况下,排名第二的显然是先验模型,这一发现与之前的研究一致。当重复Treebank-Chunk任务,但将所有“br-∗”数据集中到一个“brown”域时,可以发现Daum采用的算法取得了最好的执行效果。
表3.4 FAM在不同数据集上的序列执行标记任务的结果[13]
3.特征映射
在传统机器学习领域,有很多可行的基于映射的特征提取方法,如主成分分析(principal component analysis,PCA)[16]和核化-PCA(kernelized-PCA,KPCA)[17]。然而,这些方法主要关注数据方差而非分布差异。为了解决分布差异,人们提出了一些用于迁移学习的特征提取方法。假定在一个简单的场景中,域的条件分布几乎没有差异。在这种情况下,可以使用以下简单的目标函数来找到用于特征提取的映射:
其中,Φ表示低维映射函数;DIST(·)表示分布差度量;Ω(Φ)表示控制Φ复杂度的正则化矩阵;VAR(·)表示样本的方差。该目标函数旨在找到一个映射函数Φ使得域之间的边界分布差异达到最小,同时使样本的方差尽可能大。分母对应的目标可以通过多种方式进行优化。一种可能的方法是用方差约束来优化分子的目标。例如,映射样本的散布矩阵可以限定为单位矩阵。另一种方法是首先在高维特征空间中优化分子目标,然后执行诸如PCA或KPCA的降维算法来实现分母的目标。
此外,准确找到Φ(·)的数学表现形式并不容易。为了解决这一问题,一些方法采用了线性映射技术或转向核方法。一般来说,处理上述优化问题有三种主要思路。
(1)映射学习+特征提取:通过习得一个核矩阵或寻找变换矩阵的方式找到目标所在的高维空间,压缩高维特征以低维特征的形式表示。比如学习了核矩阵之后,就能够提取出隐含的高维特征的主要成分来构建基于PCA的新特征表示。
(2)映射构造+映射学习:将原始特征映射(feature mapping)到构造的高维特征空间,学习低维映射以满足目标函数。例如可以基于选定的核函数来构造核矩阵,然后学习变换矩阵,将高维特征投影到一个共同的潜在子空间中。
(3)直接低维映射学习:一般来说,直接找到所需的低维映射是比较困难的。但是,如果假定这个映射满足某些条件,即可计算出映射关系。例如,如果低维映射被确定为线性映射,优化问题则能够轻易解决。(https://www.daowen.com)
4.特征选择
特征选择是特征降维的另一种操作,用于提取轴特征。轴特征是在不同域中以相同方式表现的特征。由于这些特征的稳定性,可以将其作为传递知识的桥梁。Blitzer等人[18]提出了一种叫作结构化对应学习的方法,SCL通过执行以下步骤来构造新的特征表示。
(1)特征选择:SCL首先执行特征选择操作来获得轴特征。
(2)映射学习:通过使用结构学习技术,利用轴特征寻找低维的公共潜在特征空间[19]。
(3)特征叠加:通过特征增广构建新的特征表示,即将原始特征与获得的低维特征进行叠加。
以词性标注问题为例,选定的轴特征应经常出现在源域和目标域中。因此,限定词能够被包含在轴特征中。一旦定义和选择了所有的轴特征,就构建了若干二元线性分类器,这些分类器的功能是预测每个轴特征的出现。被用于预测第i个轴特征的第i个分类器的决策函数,能够被公式化为fi(X)=sign(θi·X),其中X被假设成二进制特征输入,并且第i个分类器在除了从第i个轴特征导出的特征之外的所有样本上训练。以下公式可用于估计第i个分类器的各个参数:
其中,Rowi(Xj)为使用第i个轴特征表示的没有标签样本Xj的真实值。通过将获得的参数向量堆叠为列元素来获得矩阵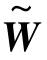 ,然后基于奇异值分解,取前k个奇异向量,即矩阵
,然后基于奇异值分解,取前k个奇异向量,即矩阵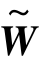 的主要成分,来构造变换矩阵W。最后在增广特征空间中的有标签样本上训练最终的分类器,即
的主要成分,来构造变换矩阵W。最后在增广特征空间中的有标签样本上训练最终的分类器,即![]() 。
。
Blitzer等[18]给出了对应的实验结果,图3.5(a)用不同数量的华尔街日报培训数据绘制了三种模型的准确性。在100个句子的训练数据中,SCL在监督基线上的误差相对减少了19.1%,并且始终优于另外两种基线模型。图3.5(b)为在40 000个句子上进行训练的实验结果,其中第二列给出了生物医学数据上未知单词的准确性。在13 000个测试样本中,大约有3 000个是未知的。对于未知单词,即使在40 000个源域训练数据中,SCL的误差也比Ratnaparkhi(1996)模型相对减少了19.5%。图3.5(c)为对应的显著性检验,p<0.05为显著性。实验使用McNemar成对测验来标记不同意见。即使使用了所有华尔街日报提供的训练数据,SCL模型也显著提高了监督基线和ASO基线的准确性。
图3.5 没有目标标签训练数据的PoS标记结果[18]
(a)561 MEDLINE测试句的结果;(b)561 MEDLINE测试集的准确率;(c)显著性检验
5.特征编码
除了特征提取和特征选择,特征编码(feature encoding)也是一个有效的工具。例如,深度学习领域经常采用的自动编码器可以用于特征编码。自动编码器由编码器和解码器组成。编码器尝试产生更抽象的输入表示,解码器旨在逆映射该表示,并最小化重建误差,自动编码器可以堆叠起来构建一个深度学习架构。一旦一个自动编码器完成了这个训练过程,另一个自动编码器可以堆叠在它的顶部,然后通过使用上层编码器的编码输出作为其输入来训练新添加的自动编码器。通过这种方式,构建了深度学习架构。
基于自动编码器开发了一些迁移学习方法。例如,Glorot等人[20]提出了一种称为多层降噪自动编码器(stacked denoising autoencoder,SDA)的方法。这种降噪自动编码器可以提高鲁棒性,是基本编码器[21]的一种扩展。这种降噪自动编码器包含一种随机损坏机制,在映射前向输入添加噪声。例如,通过添加掩蔽噪声或高斯噪声,可以损坏或部分破坏输入。然后训练去噪自动编码器来最小化原始输入和输出之间的去噪重建误差。本书提出的SDA算法主要包括以下步骤。
(1)自动编码器训练:源域和目标域样本被用来训练去噪自动编码器的每一层。
(2)特征编码与叠加:通过叠加中间层的编码输出构建一个新的特征表示,并将样本的特征转化为获得的新表示。
(3)模型训练:目标分类器在转换过的有标签样本上训练。
6.特征对齐
特征增广和特征降维主要关注特征空间中的明确的特征。相反地,除了明确的特征之外,特征对齐(feature alignment)还关注一些不明确的特征,例如统计特征和光谱特征。因此,特征对齐在特征转换过程中可以发挥各种作用。例如,可以对齐明确的特征以生成新的特征表示,或对齐不明确的特征以构建满意的特征变换。
可以对齐的特征包括子空间特征、光谱特征和统计特征。以子空间特征对齐为例,一种较为典型的方法主要包含以下步骤。
(1)子空间生成:在这个步骤中,样本被用来为源域和目标域生成各自的子空间,然后获得源域和目标域子空间的正交基,分别用MS和MT表示。这些正交基用于学习子空间之间的转换。
(2)子空间对齐:在这个步骤中,学习将MS与MT子空间对齐的映射规则,样本的特征被投影到对齐的子空间以生成新的特征表示。
(3)模型训练:最后,目标函数在转换后的样本上进行模型训练。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。





