数字人文时代的关系型数据库:中国历代人物传记资料库(CBDB )的应用
数字人文时代的关系型数据库:中国历代人物传记资料库(CBDB )的应用
徐力恒(1)
一、引言
1.什么是“数字人文”
今天我报告的题目是“数字人文时代的关系型数据库”,首先要讲的当然是为什么要取这个题目。最近几年很多人文社科的领域都在关注这个概念,大家对此大概有一些了解,也有着自己的诠释。究竟什么是数字人文时代?我的理解是:用数字化的资源,用数字化的工具和研究方法去研究文科的课题。同时,文科怎么去回应数字时代、信息化时代,也是数字人文的一部分。此外,这个时代涌现出了如此多的新科技,如何将其与文科素养结合处理新课题,亦是数字人文研究的内涵。所幸,我们看到这个领域里不少学者都在思考这个概念,而且不少人在努力,不仅建立了数据库,还对一些具体的问题进行了研究。
其实早在2012年就有一本很有趣的书出版,叫做《数字人文的辩论》(Debates in the Digital Humanities),其中有一章就是关于怎么来定义“数字人文”这个问题。这一章的编辑方式很有趣,有点像众筹,旨在集思广益,将各个学者对数字人文的定义搜集起来,把其中一些比较有代表性的说法记录下来。在这本书里面,我当时冒昧地提出了我自己的定义:“数字人文是提出、重新定义和回答学术问题的一种更智能的方式。”这个定义貌似有点宽泛,因为任何一个新的学术概念或者学术领域其实都是在做这些事,但我的重点在于,这种研究角度用的是“一种更智能的方式”。说到“更智能”,大家可能会想到计算机技术——我利用了某个数据库,我处理的资料是海量的,比以前多得多;或者是我查找史料比以前方便得多,这的确是更智能的研究方式。但我的这个说法还隐含了另一层意思,就是并非所有情况下都是计算机更智能,有时候人脑更胜一筹,而我们在提出、重新界定、回答学术问题的时候,应该采用更智能的那一种办法。如何更好地发挥人脑和电脑的功能并使之互补,促进学术研究,这大概就是我们建立接下来我要介绍的这个数据库的学术背景。
2.什么是关系型数据库(relational database)
我们的“中国历代人物传记资料库”(CBDB)是一个关系型数据库。学术数据库大家应该不陌生,比如说《四库全书》的全文数据库或“中国基本古籍库”。这类全文数据库是比较直观的,它把一部部典籍变成电子文本,然后使用者可以在其中抓取需要的文本,其使用方法一目了然,不需要什么培训就可以上手。不过,我们的CBDB是一个关系型数据库,或者叫关联性数据库,它跟全文数据库的思路是不一样的。CBDB没有把史料的文本都收进来,而是把各种资料变成数据,然后让数据关联起来。此外,这些数据还可以输出到各种工具进行分析。
在这里我要给大家介绍的是这个数据库的基本情况。它的目标是什么?它是怎么把人物数据做进数据库的?用CBDB究竟能做什么样的分析?可以用其中的数据问什么问题?对我们的研究有什么用?等等。必须先强调的是,我们数据库是一个免费开放、供学术研究使用的数据库,无论在哪里,不管是在大学图书馆还是在其他地方,都可以检索和下载我们的数据,不需要订阅。
二、“中国历代人物传记资料库”(CBDB)项目
这个项目是哈佛大学费正清中国研究中心、北京大学中国古代史研究中心以及台湾“中研院”历史语言研究所联合开发的,有关说明和介绍都可以在其主页(2)上找到。
1.CBDB的发展历程
首先给大家介绍一下CBDB是怎么建立的。它源于美国宾夕法尼亚大学的郝若贝(Robert M.Hartwell)教授收集的一些研究资料。郝教授是唐宋史专家,对经济史和社会史也有颇多关注。1982年,他发表了一篇唐宋史学界相当重要的论文——《750—1550年间中国的人口、政治及社会转型》(Demographic,Political,and Social Transformations of China,750-1550),讨论了从唐中期到宋元乃至明代的社会变迁,考察了很多人物及其家族究竟如何兴起以及官员的入仕升迁等情况,其中包括大量数据。后来他发现,比较便利的做法是把这些资料放到一个数据库里面,方便批量分析。在80年代末90年代初的时候,这确实是蛮新的做法。到了90年代,他已经有了一些初步的成果,例如论文《以计算机为主对中古中国社会和经济史进行的整体分析》(A Computer-Based Comprehensive Analysis of Medieval Chinese Social and Economic History)。不过,他在1996年去世了。去世之前,他把这些数据捐给了哈佛大学燕京学社,后来哈佛费正清中心接手,并开始跟北大、“中研院”合作,在处理这些数据的同时还进行扩充。哈佛项目组当时请到了加州大学尔湾分校的傅君劢(Michael Fuller)教授帮忙编写数据库结构和程序,同时他也是研究宋代诗歌的专家,所以很适合处理这项工作。
在后来的共同开发过程中,CBDB的北大成员开始对郝若贝教授的25 000个历史人物的数据进行修订,并开始录入更多资料。一开始还是沿着郝教授关注的历史时段去做,尤其是宋代,所以首先做了昌彼得等人所编的《宋人传记资料索引》的录入工作。后来这个项目越做越大,不只是宋代的资料,其他各个朝代的也开始囊括进来。而且,在一番探索之后,CBDB项目组也不再只是利用人工录入史籍资料,还试图去做一些文本挖掘,在史料的文本里提取人物传记的数据。
此外,我们也跟一些数据库合作,比如麦吉尔大学的“明清妇女著作”数字计划。近几年CBDB也开始处理一些地方志数据,现在正处理2 000部地方志中的官员记录。从2015年开始,我们集中不少精力处理唐代资料,希望用3年时间能够把唐代主要的历史人物资料做完。从2016年起,这个数据库受到了更多数字人文领域的同行注意,而且把它放在数字人文研究的框架去理解。所以,这两年我们也在国内做一些推广和介绍的工作,希望能跟国内的同行多交流,毕竟中国史的主要研究队伍有不少在国内。
2.CBDB搜集哪些人物数据
我们的人物传记数据库,其大类分为:人名、时间、地址、职官、入仕途径、著作、社会区分、亲属关系、社会关系、财产、事件。最基本的当然是人名,包括别名、字、号等。年代对于历史研究非常重要,只要这些人文数据能够找到确切年代,我们都会准确地录进去。对于那些没有准确年代的历史人物,我们制定了一种算法,算出一个“指数年”(index year)。所谓指数年,就是根据与人物有关的资料指定一个年份,使其数据在统计学上有一定意义。比如,一个人的父亲的年代如果是确切的,我们就可以为这个人估算一个大致的年代,如此类推。地名是跟历史人物有关的,包括郡望、籍贯、居住地、任官所在地等。说到任官所在地,当然也包括他的职官资料,究竟是怎么入仕的,做过什么官;是考科举的还是荫补,等等。另外,也会有他著作的著录。但并不意味着把他的作品的全文放进来,因为CBDB不是一个全文数据库。关于著作的资料,更多是一个人究竟写过些什么、什么时候写的之类的信息。还记载了历史人物的一些特定身份,比如说是财臣还是书法家、画家等,会给他归类。家族的因素对中国历史的研究是非常重要的,所以亲属关系也是这个数据库的一个重要内容,有很丰富的资料。家族以外的各种社会关系,我们也会尽量放进来便于大家利用,尤其是进行社会网络分析的研究。最后两个是财产和事件,我们这方面的数据仍然比较少。
3.海量数据的优势
这样一个包含海量资料的数据库,在使用上跟我们平常查阅的人物辞典是很不一样的。当然,CBDB也可以被用作一部人物辞典,但是它的长处并非作为单个人物的参考,而在于提供海量的数据,让研究者进行批量分析,看到比较宏观的图景。而且,在使用一部历史人物辞典时,我们必须知道自己想查什么人物,数据库中则可以找到一大批人物,做大规模的分析。此外,我们还会要求人物辞典里面的记载必须是权威的、准确的、相对简练的,这个跟我们对数据库的要求是不一样的。有的人看到CBDB中的某些记载与其设想的不一致,就认为整个数据库都没有参考价值,其实这是没有透彻了解CBDB这类数据库所能发挥的优势。数据库中的数据成千上万,总会有一点小错误,我们当然一直努力把这个错误率减到最低,但是如果我们对大批数据作分析,微小的错误并不会一下子大幅扭曲我们的观察,这些观察对研究还是非常有参考价值的。
给大家看一下CBDB现在中国历史人物的数量情况,主要集中在唐代到清代。
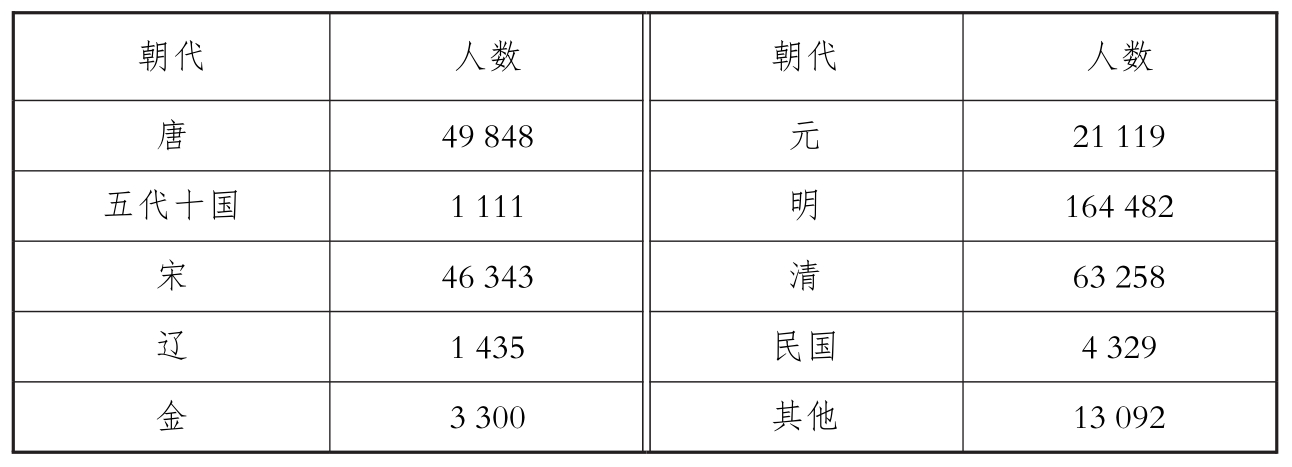
不难看出,该数据库的人物数据在时代上分布得不太平均。考虑到这是一个进行之中的项目,所以不能直接认定这就是数据库的最终面貌。例如,目前清代人物数据相对还挺少的,但这部分会在以后大大增加。
4.CBDB的人物数据从何而来
从事历史研究的人当然会很重视史料来源,那么CBDB的人物数据是从何而来呢?下面给大家简单地介绍一下。CBDB的人物数据出自这样一些文献,除了刚才提到的《宋人传记资料索引》,还有《元人传记资料索引》和《明人传记资料索引》以及唐宋元明清的各种登科录记载。另外,也收入了其他一些传统史料中的人物生平记载,如正史列传、墓志、墓表、地方志中列传等。一些著名人物的文集可以为我们提供很多社会关系资料,比如谁跟谁之间有诗歌唱和,谁跟谁之间有书信往来。职官资料当然也很重要,所以职官信息的参考书我们也会尽量收录。近年来,我们也跟许多数据库进行合作,比如数据互换,像京都大学的“唐代人物知识库”、麦吉尔大学的“明清妇女著作”计划、“中研院”史语所的明清“人名权威人物传记资料查询”等,未来我们也会跟香港科技大学李中清—康文林研究团队的缙绅录数据库进行连接。
我们的一些重点包括以下文献,大多是跟唐代历史有关的,如《唐九卿考》《唐刺史考全编》《唐五代人物传记资料综合索引》《唐方镇年表》《唐代墓志汇编》《唐代墓志汇编续集》《唐五代人交往诗索引》等。这是我们获得唐研究基金会资助的一个研究项目,打算在3年内处理完唐代的主要人物资料。此外,我们还会整理唐代的职官表。这是CBDB里的众多编码表(code tables)之一。简单来说,就是官名的一个列表和各层级职官的分类资料。不仅是唐代,我们还会继续处理一些宋代的资料,包括《宋登科记考》,也会从《宋会要辑稿》里的职官信息中挖掘。刚才有同学问到清代的情况,清代的朱卷我们快处理完了,另有2 000种地方志正在进行数据挖掘,会从里面提取历代官员信息。与前述唐代职官表类似的还有明代和清代的职官表——其中清代部分已经全部做完,正在修订。我们现在处理的文献状况大致就是这样子。
三、用CBDB能做些什么
1.CBDB的三种打开方式
如果大家手边现在有电脑,不妨试一下。我们这个数据库有三种打开方式,对应三个系统,都可以免费用于学术研究,在任何地方只要可以上网就能用。
第一个是CBDB的线上录入系统(见图1),这个录入系统主要是给我们的团队和我们的合作者使用的,它可以进行编辑、增加数据的工作,同时也可以让使用者熟悉我们资料的结构,包括查找数据的文献出处。我们也很乐意给专家提供账号(3),让大家可以帮忙录入他们正在处理的学术数据,然后我们也会请专人对新录入的数据进行复查、考订。
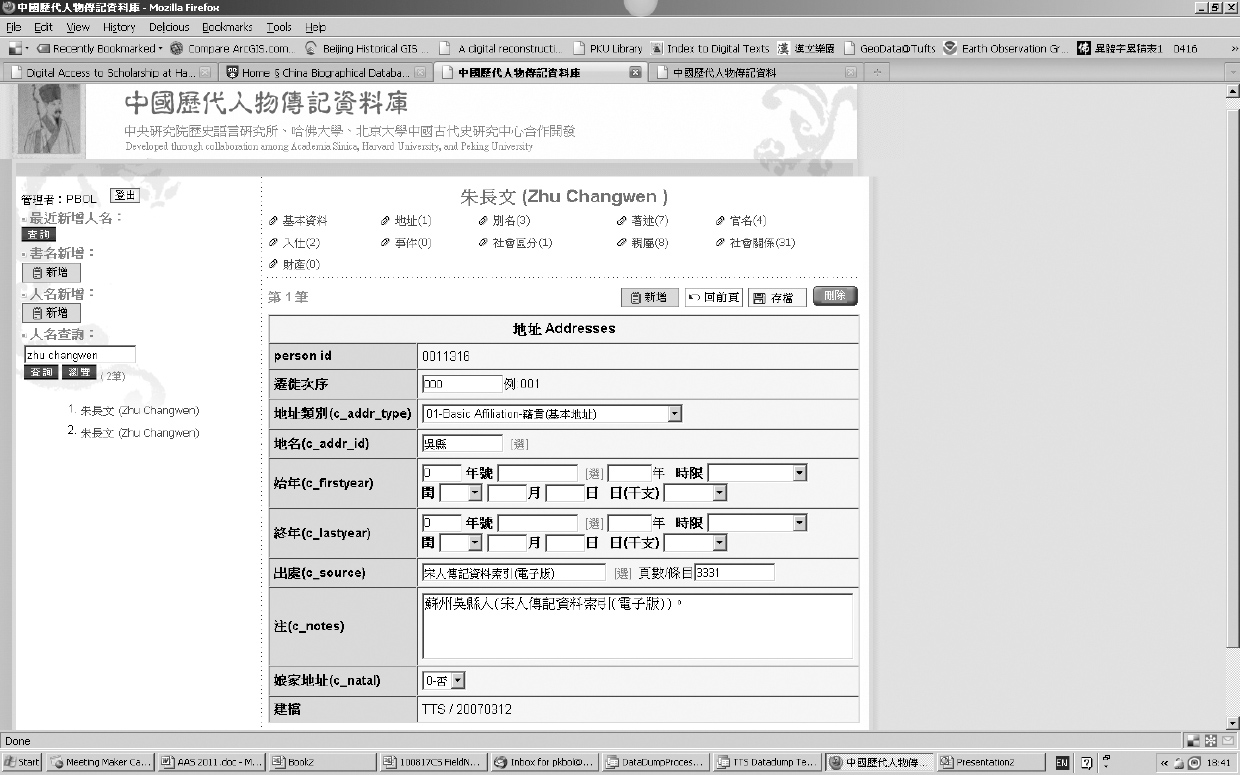
图1 CBDB线上录入系统
第二个是线上查询系统(见图2),是通过接入互联网就可以直接查询我们人物资料的一个系统,这是它的网址(4)。它的用法很简单,不过和我们的单机版相比,它的功能也相对有限。
第三个就是单机版(见图3),需要安装微软的ACCESS软件使用。这个版本的CBDB数据是最全的,功能也是最强大的。安装方法在我们的“用户指南”里有说明,这是下载地址(5)。我们也给用户设计了各种查询功能,用户可以使用预设好的查询选项。

图2 CBDB线上查询系统

图3 CBDB单机版
这个数据库其实是各个数据表的连接,每个数据表是对某类资料的记录,我们对这些记载一一加以编码,比如把人物的姓名信息还有年代、职官信息、社会关系种类、社会关系人等都抽取出来,分别编排成不同的表。每个表都是以其中一种数据实体(entity)为主的,而整个数据库就是各种实体之间的交互关系,也就是所谓关系型数据库。
为什么要对数据进行编码,而不是按照原文的样子来记录呢?首先,如果信息有任何错误的话,我们就不用在每一处都进行修正,只要在编码指向的记录进行纠正就好,这样可以减少数据库录入和订正时改来改去导致的错误记录。这样的结构意味着每种数据实体都可以搜索到,如地名、官职等,不会只搜到人名。如果不同称谓指向同一历史人物,使用者只要搜一次就可以找到所有相关的称谓。而且这些检索条件是可以叠加上去的,可以进行相对复杂的查询。
下面给大家介绍CBDB数据在运用中的几种分析方法:一是地理空间分析,二是社会网络分析,三是群体分析或者叫群体传记学。因为涉及的不只一两个人,而是一批人,所以也需要用到一些简单的统计功能。
2.地理空间分析
我们先来看一下地理信息分析,它是利用地理信息系统(GIS)技术实现的。CBDB项目跟哈佛大学的地理分析中心与复旦大学的历史地理研究所共同完成的CHGIS项目有很多合作,后者提供了不少关于地名的历史信息和GIS数据,比如说一个地名的地理范围是怎么演变的,它的名称什么时候改过,等等。这个网站(6)上的地理信息数据和图层都是开放的,可免费下载。
比如说,我们可以先把所有数据导入,画出CBDB中所有历史人物的籍贯分布情况,总共是19万余条记录(见图4):

图4 包弼德教授制作的约19万名CBDB人物的籍贯分布图
图中的圆点越大,就表示人数越多,这个很直观。为什么是19万人,而不是把数据库里所有人物的籍贯都画出来?因为历史记载是不完整的,我们目前尚无法得知其他人的籍贯,所以只能画这么多。当然,这样的地理分布可以揭示的内容不是特别多,这就意味着我们应该问更具体的问题,再做地理上的呈现。
怎么画这些图呢?我们用了一款叫做QGIS的GIS软件。它是免费的,操作也比一些收费的GIS软件简单,所以我个人比较推荐。不管是CBDB的线上查询系统还是单机版,都有一个导出GIS文件的选项,使用者在查询之后就可以输出这些人物地理信息的GIS数据,在QGIS上选择用什么呈现方式,加入什么底图。关于QGIS的具体使用方法可以在“优酷”上观看视频(7),包括怎么导入数据,怎么在QGIS里面处理投影,选择怎样的多边形表达数据等操作。
3.社会网络分析
接下来我们谈一下社会网络分析(social network analysis)。CBDB里面有很多社会关系数据,所以很适合进行社会网络分析。为什么要做这样的分析呢?其实有一些社会学家提到过,从短时段的角度来讲,个人特点对社会关系的塑造是比较大的;但从长时段来讲,社会关系从整体上对每个个体的塑造就明显得多了。所以社会科学往往会去观察社会关系的具体形态。这个放在具体的中国历史问题上也很好理解,人脉、人与人之间的关系起着非常大的社会作用,比如说同乡、同年的各种人际网络,都是我们考察历史问题时必须考虑的。当然,社会网络分析是从社会学研究衍生出来的一种分析方法,历史学者在运用中是会面对一些挑战的,因为研究历史时我们的材料比较有限,不像观察当代问题那样可以搜集到相对完整的数据。所以,历史研究运用社会网络分析方法时,往往集中在一些具体问题的分析上,比如书信往来的网络、社会运动、亲属关系、经济史之类的话题。
做这样的社会网络分析,“网络”不只是象征性的,而是一个具体的呈现,甚至可以用各种计算方法来衡量和分析。从历史学的角度看,这当然不是唯一可供使用的分析角度,我们的责任是为这些网络关系赋予我们的诠释。由于我们只能根据特定的、有限的资料绘制这些图,而且是历史上的时代截面,不太容易搜集到动态的数据,所以这种社会网络无法代表历史现象的全部。那么,我们进行解读的时候就要去具体看,究竟某个历史人物跟其他人的关系要如何放在社会网络里理解——不能只是追求一种直观,而是必须探求网络呈现背后的历史线索。
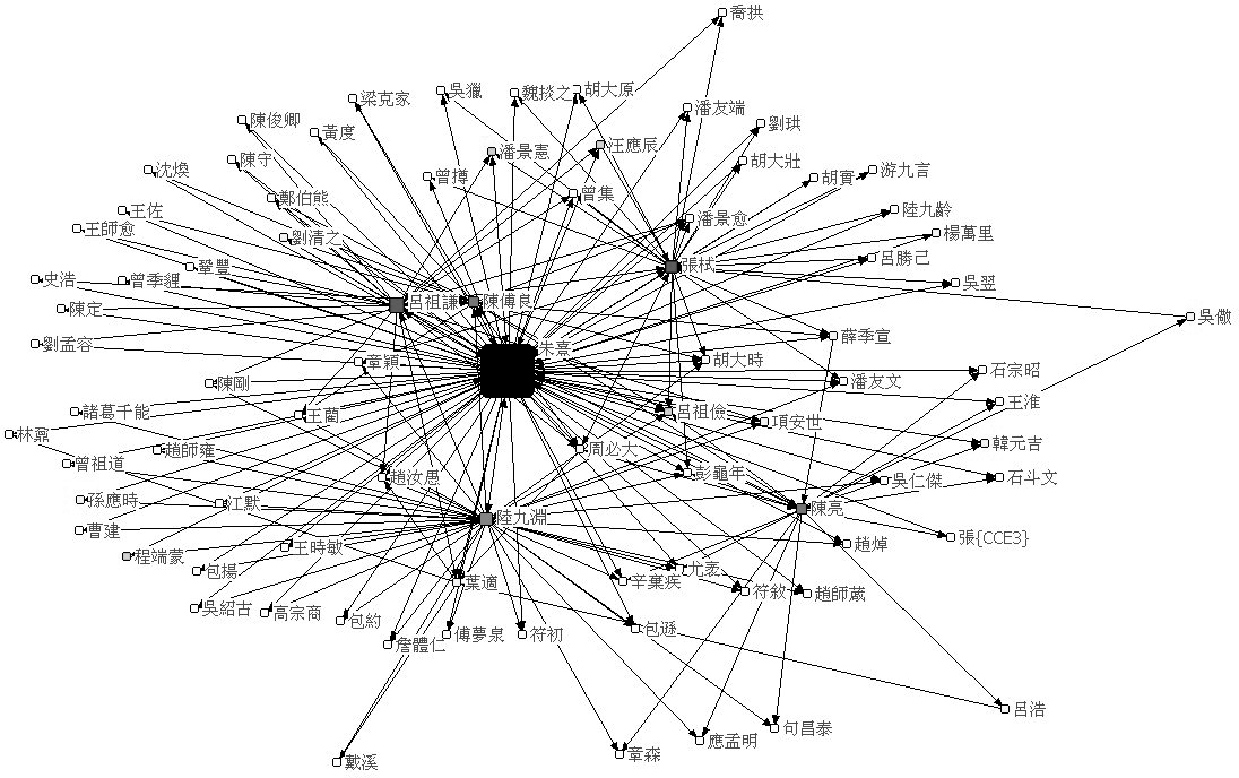
图5 朱熹的书信交往网络
上图中的“朱熹的书信交往网络”就是一个极好的例子。它也是从CBDB导出数据,然后在专门的社会网络呈现软件里呈现、调校的。在此我推荐两个软件:一个是Pajek,另一个是Gephi。这两个都可以在网上免费下载,我们的数据库在查询结果之后,有导出这两个软件格式的选项。
4.群体分析和统计分析
群体分析中也涉及一些统计分析。需要提到一种分析角度,就是群体传记学(prosopography)。它是通过对一个群体的某些共同特点进行分析,把这些有共同背景的人的各种变量看作可以调整的参数,从而进行考察和分析。也就是说,如果有一组相同背景的人,假设在座的都是上海大学历史系的同学,这个群体的一些参数,比如毕业去向、生源地、毕业的中学,等等,会影响我们的行为,我们可以去观察哪一个会影响我们的行为模式,影响幅度有多大。
让我们来看一些例子。在统计了CBDB里面所有有具体生卒年份、死亡年龄之后,我们算出平均寿命是61岁。这可能比想象中要稍高一些,部分原因是我们的数据都来自社会地位比较高的人。如果再把女性单列出来,就会看到这样的一幅图,大致有两个或多个高峰,如下图7所示。为什么?因为前近代社会的生育风险导致其中的死亡高峰。我们甚至可以按此考察当时的高龄产妇大致是多少岁。
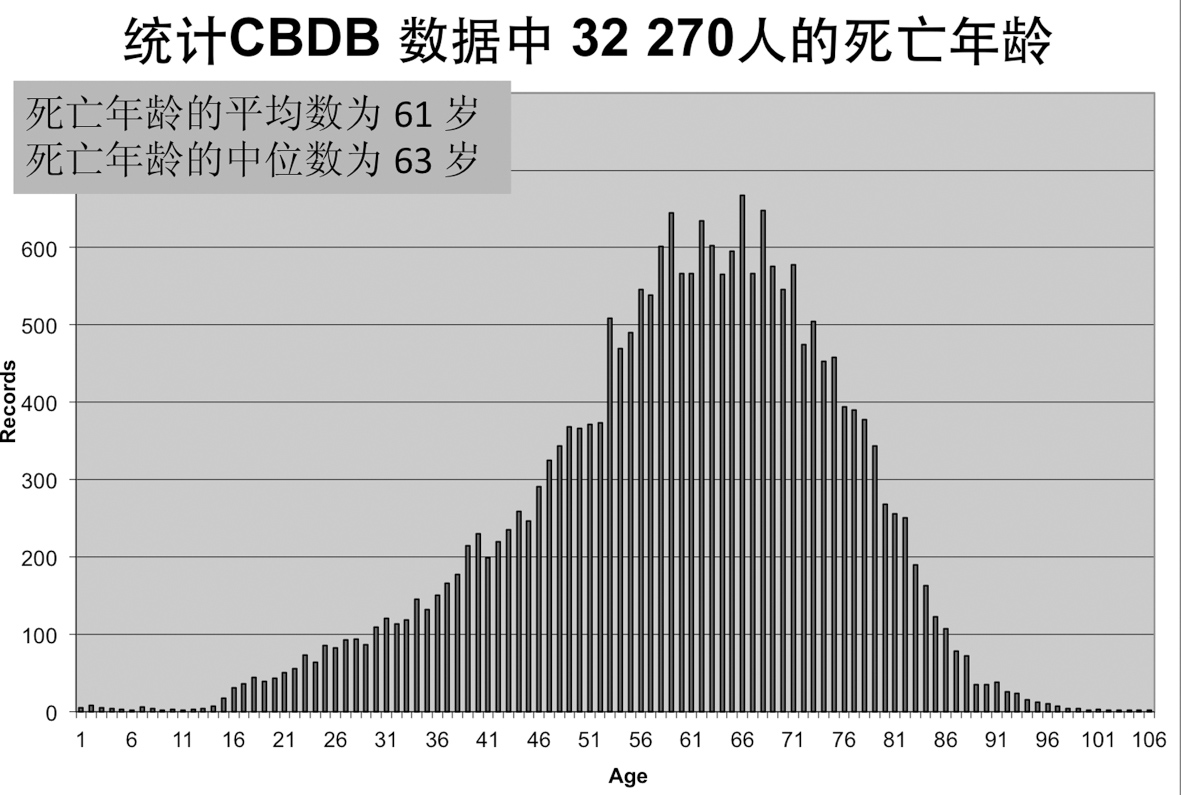
图6 CBDB人物的死亡年龄分布
有一些问题,如果我们要手动计算就会产生非常大的工作量。但有了CBDB的数据,我们就不难算出初步结果,让我们继续检验我们的观察。例如,因为我们录入了所有有记录的唐代九卿和刺史人物的数据,所以我们就可以找出他们所有人出任这些官职的年龄分布,做一个宏观分析。这样的考察思路并不复杂,但如果不用数据库的话,真的很不好做。有了数据,除了可以很有效率地处理外,我们还可以不断作比对,得出的结果可以再引领我们去问更多的问题,然后我们用不同的手段,包括数字人文的手段和人文学科惯用的研究方法去解决。
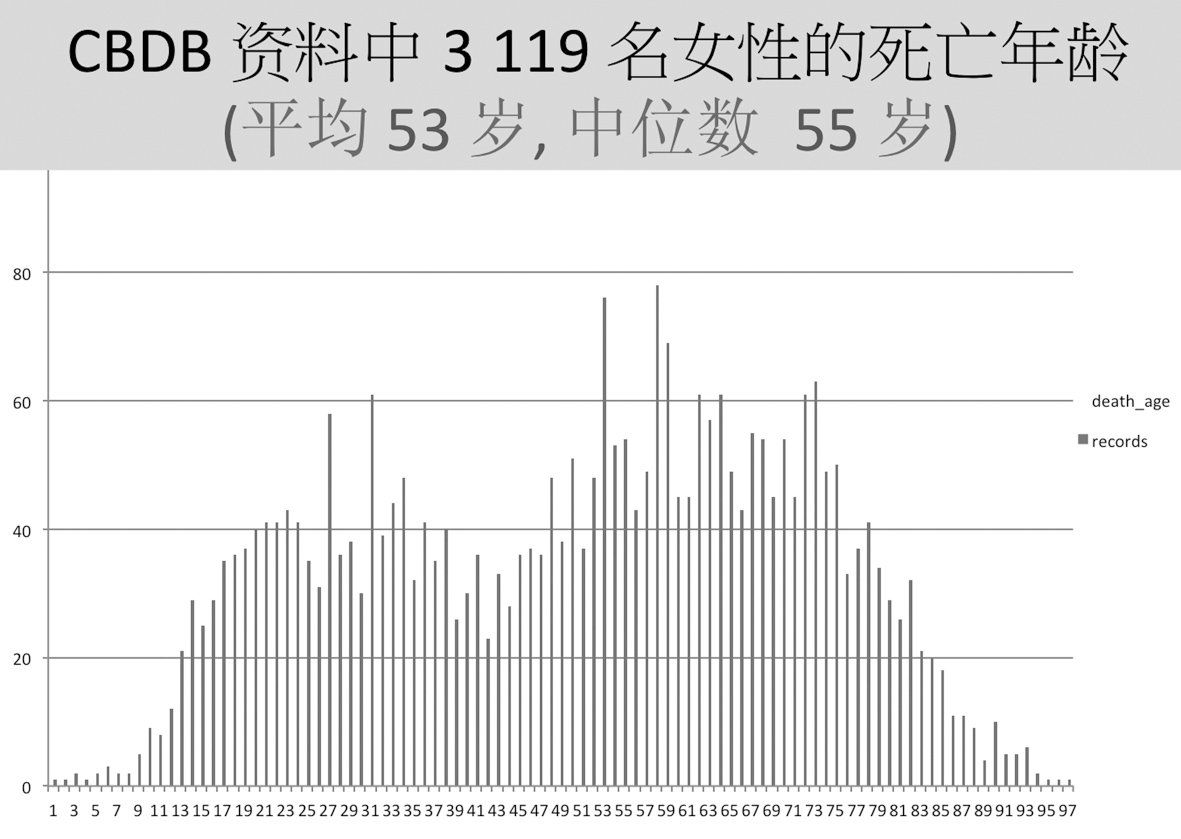
图7 CBDB女性人物的死亡年龄分布
四、结语
我们的台湾合作者开发了一套视频教程(8),我们的数据也是有延展性的,欢迎大家把我们的数据拷出来,拿到比如像Excel这样的软件上去处理、计算和补充,甚至可以跟其他数据对接。我们还有文字版的用户指南,里面包括对我们数据结构的详尽介绍,还有单机版各种用法的介绍。
我建议,使用这个数据库的时候要不断摸索、不断重复并调整查询条件。如果结果不够理想,有几种主要的可能性:一是CBDB里没有这些资料,或者我们还没处理完;二是这些史料本身就不存在,三是没有用对查询方法。
这个数据库的价值可以概括为以下三方面:第一是中国古代人物数据。研究这个方向的学者,人物数据肯定是要涉及的,那么CBDB会非常有用;第二是跟CBDB相关的研究方法。前面我介绍了三种分析方法,这些不一定要拿CBDB的数据来做,它们更多是一种研究思路;第三是CBDB里的编码表,包括各种地名、官名、入仕方式、亲属的类别等。这些对大家研究各个话题都是有用的,比如说研究家族史,自然需要对一个家族里完整的亲属类别进行整理,这就可以利用CBDB中的亲属编码表,甚至是把表格导出来,方便使用和分析。总之,CBDB项目并不限定用户拿数据来做哪方面的学术研究,它既然是一个基础性的数字化研究工具,又是开放的,当然希望能够运用得越广泛越好。
最后,我想说一说CBDB和历史文献(或我们惯常说的史料)的关系,它绝不是一种取代的关系。不是说我们有了CBDB或其他数据库,就可以丢掉历史文献。CBDB只是一种“打开”文献的方式,一种新的、更智能的打开方式,而且计算机只是我们能用的工具之一,还有很多研究方法是需要继续练习和使用的。我们要做的是既发挥我们作为人文学者的长处,又发挥计算机的长处,两方面同时去做。
(1) 作者为哈佛大学博士后研究员,马克斯-普朗克科学史研究所访问学者。本文根据作者2016年5月6日在上海大学“中国史高原学科学术沙龙”的讲稿整理而成,讲稿记录在上海大学历史系陈健赛同学的帮助下完成,特此致谢。
(2) https://projects.iq.harvard.edu/chinesecbdb.
(3) 直接输入用户名“guest”,密码也是“guest”。
(4) http://db1.ihp.sinica.edu.tw/cbdbc/ttsweb?@0:0:1:cbdbkm.
(5) https://projects.iq.harvard.edu/chinesecbdb/%E4%B8%8B%E8%BC%89%E6%95%99%E5%AD%B8%E8%88%87%E8%BC%94%E5%8A%A9%E6%96%87%E4%BB%B6.
(6) https://www.fas.harvard.edu/chgis/.
(7) http://i.youku.com/i/UMzI3NDY1MDYzMg==/videos.
(8) 详见https://www.youku.com/playlist_show/id_26353417.html。