一提到大数据技术,大家首先就会想到Hadoop,就会想到那只可爱的黄色小象,其实大数据技术还是不能与Hadoop画等号,它的体系非常复杂,且处于快速发展和创新期,远未到成熟和稳定阶段,除了Hadoop之外,还有很多的技术流派。但Hadoop确实是大数据技术的中流砥柱,因此,要了解大数据技术,首先要清楚到底什么是Hadoop?Hadoop包含哪些内容?
1.Hadoop系统生态圈分析
Hadoop体系其实并不是原创的,而是Google技术的开源化。Google创造了几项革命性的技术:GFS、MapReduce和BigTable,即所谓的Google“三宝”。但Google虽然没有公布这几项技术的实现代码,此后业界纷纷根据Google“三宝”的原理进行了开源实现,Hadoop就是其中的一个。
Hadoop是由Apache基金会开发的一个大数据分布式系统基础架构,最早版本是2003年原Yahoo!Doug Cutting根据Google发布的学术论文研究而来。Hadoop这个名称并不代表任何英文词汇或者缩写代号,而是来自于Doug Cut-ting儿子的一个黄色大象填充玩具,主要原因是开发过程中他需要为这套软体提供一个代号方便沟通,而Hadoop这个名字发音简单,拼写容易,而且毫无意义、也没有在任何地方使用过,因此中选,黄色小象也因而成为Hadoop的标志。经过近10年的发展,Hadoop已经成为一个庞大的家族,其生态系统如图6-9所示。
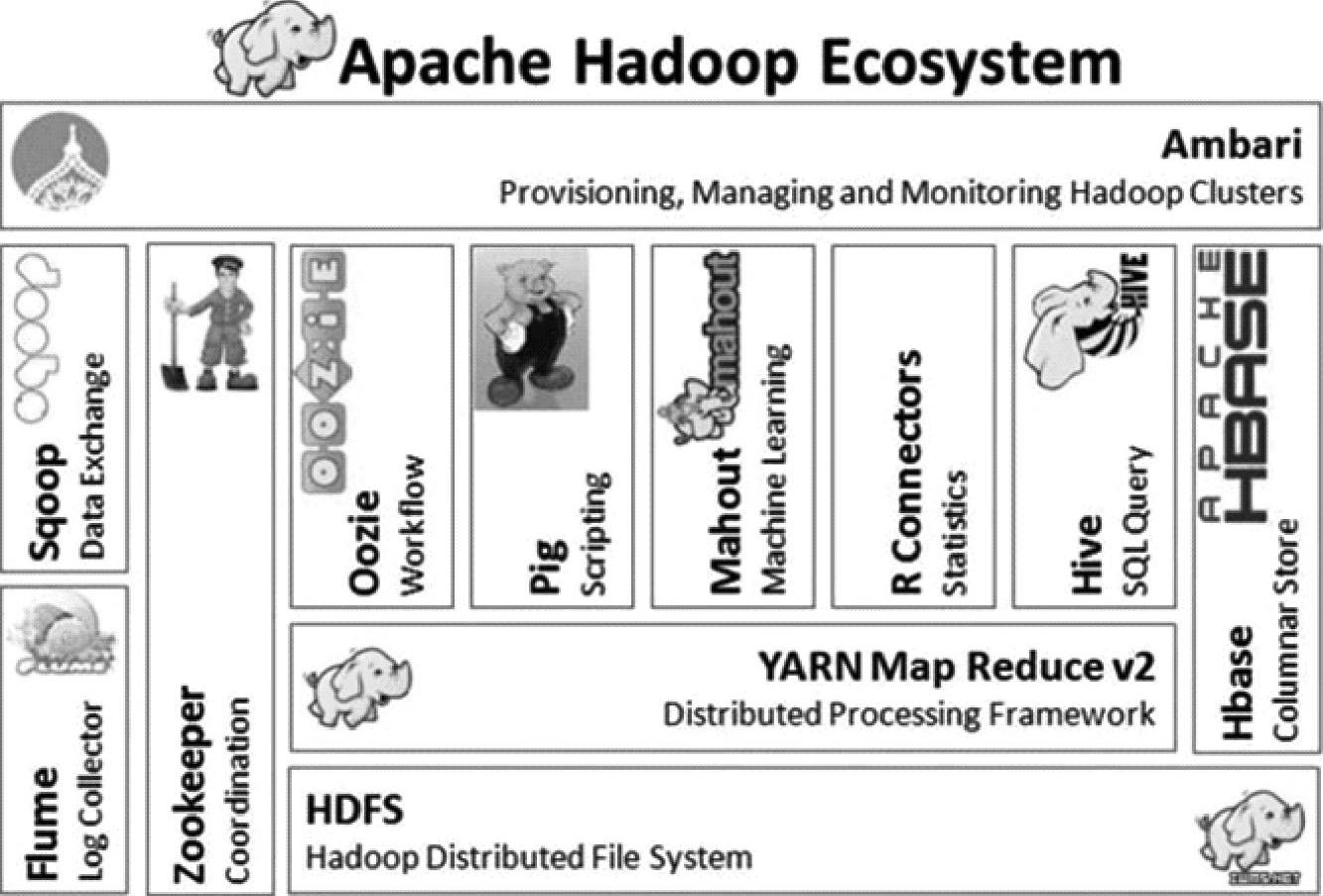
图6-9 Hadoop技术生态圈
Hadoop大数据技术体系庞大而复杂,其中最核心的是HDFS和MapRe-duce,除此之外,还有Hbase、Hive和Mahout等,下面就分别简要介绍一下生态圈中的各个成员,详细的技术原理将在下一节进行介绍。
1)HDFS:HDFS是Hadoop分布式文件系统,它源自于Google发表于2003年10月关于GFS的论文,是GFS的开源版本。Hadoop是一个分布式系统,也就是由单一伺服器扩充到数以千计的机器,整合应用起来像是一台超级计算机。而资料存放在这个系统中的方式则是采用HDFS(Hadoop Distributed File System,分散式档案系统)。通过HDFS,Hadoop能够储存上万TB甚至PB等级的巨量资料,不用担心单一档案的大小超过一个磁碟区的大小,而且也不用担心某个机器损坏导致资料遗失。
2)MapReduce:MapReduce是Hadoop的分布式计算框架,它源自于Google的MapReduce论文,Hadoop MapReduce是Google MapReduce的开源实现版。MapReduce是一种计算模型,用以进行大数据量的计算。其中Map对数据集上的独立元素进行指定的操作,生成键—值对形式的中间结果。Reduce则对中间结果中相同“键”的所有“值”进行规约,以得到最终结果。Ma-pReduce这样的功能划分,非常适合在大量计算机组成的分布式并行环境里进行数据处理。
3)Hive:Hive是基于Hadoop的数据仓库,由Facebook开源,最初用于解决海量结构化的日志数据统计问题。Hive定义了一种类似SQL的查询语言(HQL),将SQL转化为MapReduce任务在Hadoop上执行,通常用于离线分析。
4)Hbase:Hbase是一个分布式列存数据库,源自Google的Bigtable论文,HBase是Google Bigtable的开源实现版。HBase是一个针对结构化数据的可伸缩、高可靠、高性能、分布式和面向列的动态模式数据库。和传统关系数据库不同,HBase采用了BigTable的数据模型。HBase提供了对大规模数据的随机、实时读写访问,同时,HBase中保存的数据可以使用MapReduce来处理,它将数据存储和并行计算完美地结合在一起。
5)Zookeeper:Zookeeper是Hadoop的分布式协作服务,源自Google的Chubby论文,Zookeeper是Chubby的开源版,主要解决分布式环境下的数据管理问题,包括统一命名、状态同步、集群管理和配置同步等。
6)Sqoop:Sqoop是SQL-to-Hadoop的缩写,主要用于传统数据库和Hadoop之前传输数据,是一款大数据系统和传统数据库之间的数据同步工具。
7)Pig:Pig是基于Hadoop的数据流系统,由Yahoo!开源,设计动机是提供一种基于MapReduce的ad-hoc(计算在query时发生)数据分析工具,定义了一种数据流语言Pig Latin,将脚本转换为MapReduce任务在Hadoop上执行,通常用于进行离线分析。
8)Oozie:Oozie是一个工作流引擎服务器,用于运行Hadoop Map/Reduce和Pig任务工作流。同时Oozie还是一个Java Web程序,运行在Java Servlet容器中,如Tomcat。
9)Mahout:Mahout起源于2008年,最初是Apache Lucent的子项目,它在极短的时间内取得了长足的发展,现在是Apache的顶级项目。它是一个数据挖掘算法库,主要目标是创建一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。Mahout现在已经包含了聚类、分类、推荐引擎(协同过滤)和频繁集挖掘等广泛使用的数据挖掘方法。除了算法,Mahout还包含数据的输入/输出工具、与其他存储系统(如数据库、MongoDB或Cassandra)集成等数据挖掘支持架构。(https://www.daowen.com)
10)Flume:是Cloudera开源的日志收集系统,具有分布式、高可靠、高容错、易于定制和扩展的特点。它将数据从产生、传输、处理并最终写入目标的过程抽象为数据流,是一个可扩展、适合复杂环境的海量日志收集系统。
11)Ambari:Ambari是一个供应、管理和监视Apache Hadoop集群的开源框架,它提供一个直观的操作工具和一个健壮的Hadoop API,可以隐藏复杂的Hadoop操作,使集群操作大大简化。这个工具提供集群管理仪表盘,可以跟踪集群运行状态,帮助诊断系统性能问题。
2.大数据总体技术架构
上面简单罗列了Hadoop生态系统的主要成员,但大数据并不仅仅限于Hadoop,还有一些“编外”技术。一个完整的大数据系统总体架构如图6-10所示。
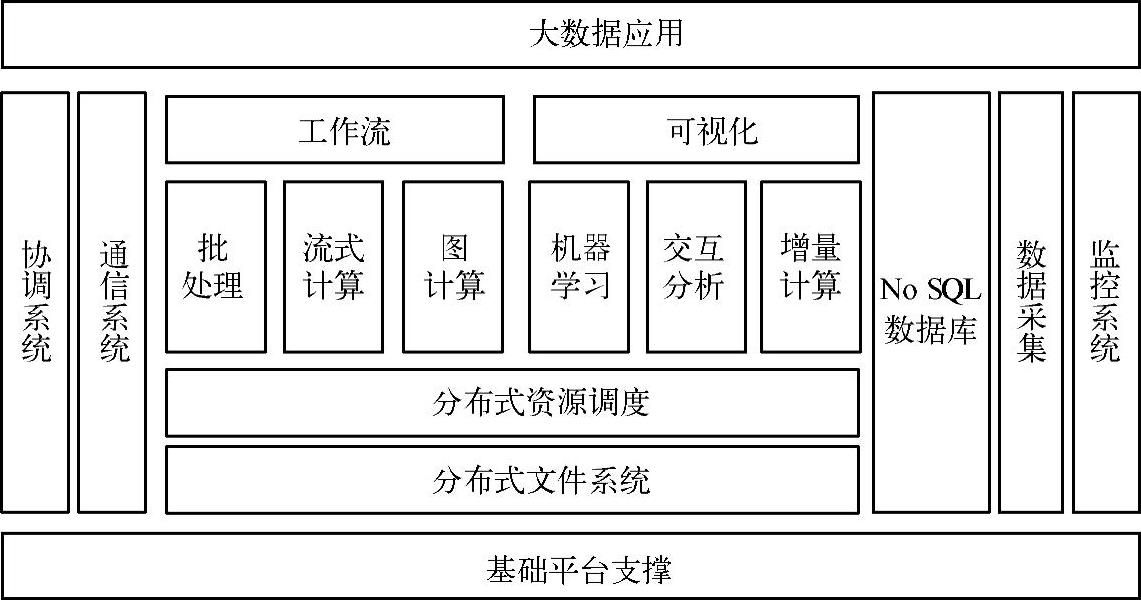
图6-10 大数据管理系统总体架构
上述大数据技术框架包含以下几部分内容。
1)基础平台支撑:主要包括为支撑大数据处理的基础架构级数据中心管理、云计算平台、云存储设备及技术、网络技术、资源监控等技术。大数据处理需要拥有大规模物理资源的云数据中心和具备高效的调度管理功能的云计算平台的支撑。云计算管理平台能为大型数据中心及企业提供灵活高效的部署、运行和管理环境,通过虚拟化技术支持异构的底层硬件及操作系统,为应用提供安全、高性能、高可扩展、高可靠和高伸缩性的云资源管理解决方案,降低应用系统开发、部署、运行和维护的成本,提高资源使用效率。
2)数据采集技术:数据采集技术是数据处理的必备条件,首先需要有数据采集的手段,把信息收集上来,才能应用上层的数据处理技术。数据采集除了各类传感设备等硬件软件设施外,主要涉及的是数据的ETL(采集、转换、加载)过程,能对数据进行清洗、过滤、校验和转换等各种预处理,将有效的数据转换成适合的格式和类型。
3)数据存储技术:数据经过采集和转换之后,需要存储归档。针对海量的大数据,一般可以采用分布式文件系统和分布式数据库的存储方式,把数据分布到多个存储节点上,同时还需提供备份、安全、访问接口及协议等机制。另一个数据存储技术是NoSQL数据库,是存储非结构化数据的数据库管理系统,主要包含键值(Key-Value)存储数据库、列存储数据库、文档型数据库和图形(Graph)数据库等几种类型。
4)数据计算:这里把与数据查询、统计、分析、预测、挖掘、图谱处理和BI商业智能等各项相关的技术统称为数据计算技术。数据计算技术涵盖数据处理的方方面面,也是大数据技术的核心。Hadoop最核心的是批处理计算(MapReduce)和交互式计算(Hive),而对流式计算、图计算、机器学习和增量计算等支持不够,这也是非Hadoop系产品创新的主要战场。
5)数据展现与交互:数据展现与交互在大数据技术中也至关重要,因为数据最终需要被人们所使用,为生产、运营和规划提供决策支持。选择恰当的、生动直观的展示方式能够帮助人们更好地理解数据及其内涵和关联关系,也能够更有效地解释和运用数据,发挥其价值。在展现方式上,除了传统的报表和图形之外,还可以结合现代化的可视化工具及人机交互手段,甚至是基于最新的如Google眼镜等增强现实手段,来实现数据与现实的无缝接口。
6)分布式协调技术:在分布式应用中,由于工程师不能很好地使用锁机制,以及基于消息的协调机制不适合在某些应用中使用,因此需要有一种可靠的、可扩展的、分布式的、可配置的协调机制来统一系统的状态。Chubby、Zookeeper等分布式协调技术的目的就在于此。
7)大数据管理、安全与备份恢复工具:大数据的管理、安全控制、数据备份与恢复工具帮助大数据系统能够稳定、安全地运行。可以提供系统的实时监控、安全模式运行、日志审计、文件系统检查、性能监控、数据备份和文件系统均衡等功能,为大数据系统安全运行保驾护航。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。






