本节提出了基于逐点搜索的算法来实现这一目标。
逐点搜索算法:在整个二值化图像中,从左到右、从上到下依次搜索每一个像素点,若是白色肤色点,则进行局部搜索将与之连通的整个肤色区域都找出来,并将搜索过的区域标记为访问过,避免重复访问。然后记录这一连通区域的信息,并对还未搜索过的区域进行搜索。这样,就能在只对图像进行一次访问的情况下,将所有的肤色区域都标记出来,保证了整个算法的时间性。
下面介绍整个识别系统的流程。
1.图像采集
硬件方面,通过市面上销售的普通CMOS摄像头来采集图像,没有使用其他任何特殊硬件。软件方面,考虑到目前大部分系统都是建立在Windows9x/WindowsNT/Windows2000平台上的,Windows良好的人机交互界面很适合于图像处理与识别系统的应用,所以本系统采用的软件编程环境是基于Windows2000的Visual C++6.0,它是基于Windows平台的一个集成的、优秀的开发工具。而且由于Windows把位图(BMP)作为其图像的标准格式,内含了一套支持BMP图像操作的应用程序接口(API)函数,BMP图像格式越来越多地被各种应用软件所支持,各种流行的图像格式都能和BMP相互转换,所以本系统的输入图像也采用了BMP格式图像。
在这一环境下,图像采集的实现步骤如下:
1)调用函数capCreateCaptureWindow(NULL,WS_CHILD|WS_VISIBLE,0,0,320,240,GetSafeHwnd(),1)来创建一个大小为320像素×240像素的捕获窗口。
2)调用函数capDriverConnect(hCapt,i)来连接摄像头驱动程序。
3)调用函数capDriverGetCaps(hCapt,&Drivercaps,sizeof(CAPDRIVERCAPS))来返回摄像头的性能。
4)调用函数capDlgVideoFormat(hCapt)来设置视频格式。
5)调用函数capGetVideoFormatSize(hCapt)来查看视频窗口大小。
6)调用函数capPreviewRate(hCapt,41)来设置每秒的显示帧数。
7)调用函数capPreview(hCapt,true)将显示模式设置为Preview模式,这样图像数据从摄像头采集进来后,将经过内存再到图像显示设备显示。这样,就可以在图像数据通过内存时,对图像信息进行处理,实现想达到的目标。
2.人脸检测算法的实现
首先介绍如何将肤色点和非肤色点区分开来。
1)在程序中,设置一个全局的回调函数LRESULTCALLBACK OnFrame(HWNDhWnd,LPVIDEOHDRlpVHdr),算法的程序就在这个函数中实现。
2)通过函数capSetCallbackOnFrame(hCapt,OnFrame),调用该回调函数,整个系统的运行框架就搭好了,剩下的就是在函数OnFrame中实现人脸检测了。
3)在该函数中,先将图像每个像素点的RGB分量依次读到temp_r、temp_g、temp_b三个变量中。再按式(4-6)将其转变到YCrCb色度空间中。
4)调用肤色模型函数skincolor(unsigned char∗ptr,int width,int height),将肤色像素点赋值为1,非像素点赋值为0。
在将肤色点与非肤色点分开以后,下面介绍如何将人脸图像标记出来。
在得到二值化的图像后,因为人脸区域的像素点赋值为1,所以只要把这些像素点所在区域用矩形框标记出来就行了。
在这里,本节基于逐点搜索的算法来实现这一功能。
定义了一个数据结构myPoint:

该数据结构中包含4个点:pointx1、pointy1分别返回矩形框的左上角的x、y坐标,pointx2、pointy2分别返回矩形框右下角的x、y坐标。定义了返回值为myPoint类型的函数FillRect:
myPoint FillRect(int currentx,int currenty,int left,int right,int top,int bottom)
在该函数中,将逐点搜索到每一个标记为1的像素点,并记下它们的最小及最大横纵坐标值,作为返回值。一般的逐点搜索算法是利用数据栈结构来存储像素点,利用入栈出栈操作来逐点搜索像素点。但这一方法消耗了太多的系统资源,很难满足对于实时检测的要求。作者改进了这一算法,在入栈操作时,以一行像素点为基础,将每行的信息入栈,极大地提高了搜索的效率,达到了实时的要求。
当场景中有多个人脸时,就不能只标记出一个,而是要把所有的人脸都标记出来。本节定义了一个模板类型的队列:
template<class Type>class Queue;
在程序中,生成了一个myPoint类型的队列:Queue<myPoint>queue;这样通过多次调用FillRect函数rectsize=FillRect(i,j,1,ISIZEX-1,1,ISIZEY-1),将每一个人脸的位置信息都存入该队列queue.EnQueue(rectsize)中,在位置信息出队时,根据位置信息,将每一个人脸用矩形框标记出来。这样就完成了人脸检测。二值化图像及标记出的人脸位置如图4-14所示。

图4-14 二值化图像及标记出人脸位置
3.面部器官检测
(1)面部器官特征点定位 面部特征点定位有很多方法,但很多都是依靠手工在图片上定位,或利用特殊的硬件,比如红外线照射、用发光二极管贴在脸部,或用高分辨率的摄像机等方法。这些方法要么对于实时性的要求不能满足,要么不能满足一般用户的要求。而我们要设计一个能被普通用户接受的系统,所以采用的是市场上最一般的USB(通用串行总线)接口摄像头,而且在较低的分辨率上实现了我们的系统。
在本节所提出的特征检测算法中,眼睛的定位是其他器官定位的基础,因为眼睛是人脸上最为突出而且稳定的特征。在准确定位眼睛的基础上,又对嘴巴、眉毛和鼻孔进行了定位。因为在检测面部器官时,对于光线均匀分布的要求比较高,所以在定位之前,需要先对人脸图像进行一些处理,以平衡光线差异和消除阴影,使光线在人脸上的分布较为均匀。
本节所采用的方法是直方图均衡化、照度梯度修正(Illumination Gradient Correlation)和方均差标准化来实现光线的平衡化。
1)直方图均衡化:直方图均衡化(Histogram Equalization)就是把给定图像的直方图分布改为均匀分布。
设图像有L级灰度(0,1,2,…,L-1),n为图像像素数,ni为第i级灰度的像素数,则直方图均衡化将第k级的灰度变换为Ik,即

式(4-13)中的括号内的数要四舍五入取整。直方图均衡化可以起到增强图像的作用。
2)照度梯度修正:为了减少非正面光照对人脸的影响,要对样本图像进行照度梯度修正,即用图像的灰度值拟合出一个校正平面,然后减去这个平面。
令待处理的图像包含n个像素,灰度为I(xi,yi)(I=1,2,…,n),需要拟合的平面为z=a1x+a2y+a3,此平面应使I(xi,yi)与z的均方差最小:
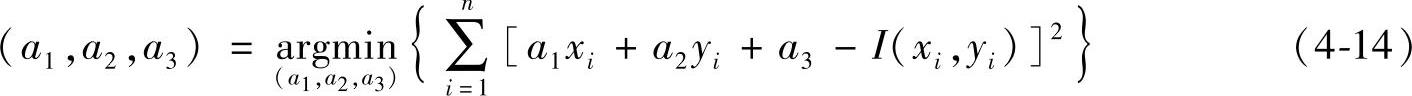
由最小二乘法解得
X=(ATA)-1ATB (4-15)
式中,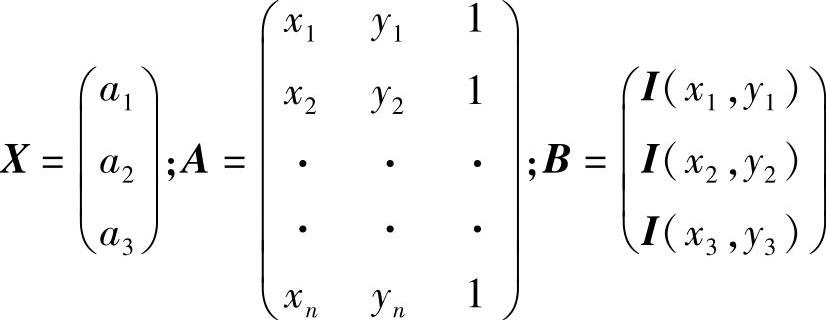
对于式(4-15)可以分解为(ATA)-1AT与B的乘积。由于(ATA)-1AT仅与图像的尺度有关,将人脸归一化到同一尺度,就可以首先计算(ATA)-1AT的值。求得平面后,将图像中的各个像素与其相应位置z值相减:
I′(xi,yi)=I(xi,yi)-z=I(xi,yi)-(a1xi+a2yi+a3) (4-16)
照度梯度修正消除了图像的一阶变化量,很大程度上减少了脸部的阴影。
3)方均差标准化:为了进一步增强人脸模式的紧致性,对图像的统计特性也进行了标准化,将统计学中两个很重要的指标——灰度的均值和方差调整到给定的值,具体做法如下:
令大小为W×H像素的图像的灰度矩阵为I(x,y)(0≤x<W,0≤y<H),则有该图像的灰度均值和方差分别为
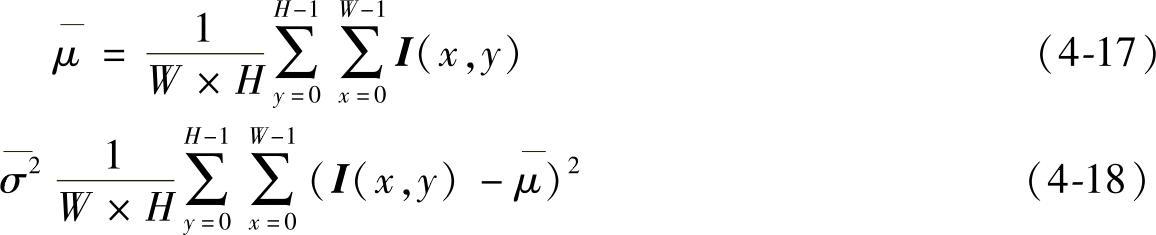
为了将图像的灰度均值和方差调整到给定的值μ0和σ0,对每个像素值作如下变换:
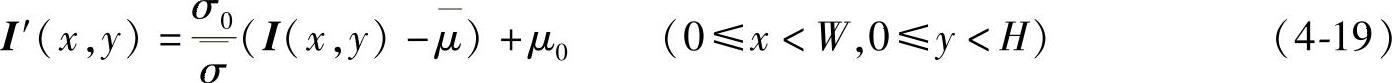
在程序实现中,设置了一个函数:Histogramqual(unsigned char∗ptr,int width,int height)。在该函数中,实现了上面的算法。在主程序中,调用此函数来改进人脸图像的光照效果。
经过了上面的算法处理后,就得到了光线分布较为均匀、图像质量较好的人脸图像了。下面的工作就是要定位人脸的面部器官特征,将依次介绍眼睛、眉毛、嘴和鼻孔的定位方法。
(2)眼睛特征点的定位 眼睛的定位是基于人脸定位的基础上实现的。人眼特征点定位如图4-15所示。利用肤色模型实现了人脸检测,将得到的人脸区域转化为灰度图,并用合适的阈值对其进行二值化后,在得到的二值化图中,用下面的规则来搜索眼睛对。
1)左右眼块的大小R1和R2相差不大。
2)左右单眼宽W1和W2与双眼中心距离D之比在一定范围之内。
3)左右眼的重心高度H1和H2相差不大。
4)左右眼宽高之比在一定范围内。
实验表明,通过上述四条规则的限制,总可以找到一对满足条件的连通区域,而这对连通区域恰好就是由两个眼睛所形成的区域。

图4-15 人眼特征点定位
在找到了两个眼睛后,本节采用了局部搜索的方法定位两个眼角点,即在眼睛所对应的局部区域中,搜索最左和最右的两个点作为左右眼角点,搜索最上和最下的两个点作为上眼皮顶点和下眼皮顶点。对于虹膜中心点的定位,采用了传统的积分投影的方法。
在程序的实现中,本节定义了一个数据结构EyePoint:

然后定义了一个以EyePoint为返回值的函数FillEye(int currentx,int currenty,int left,int right,int top,int bottom)。通过这个函数来返回眼睛的位置坐标。
(3)眉毛特征点的定位 按类似于眼睛定位的方法,利用一定的规则可在眼睛区域的上方搜索到眉毛区域,并定位出眉毛的角点,如图4-16所示。
在程序的实现中,定义了一个数据结构BrowPoint:

然后定义了一个以BrowPoint为返回值的函数FillBrow(int currentx,int currenty,int left,int right,int top,int bottom)。通过这个函数来返回眉毛的位置坐标。

图4-16 眉毛特征点定位
(4)嘴部特征点的定位 在唇色模型的基础上,利用类似于眼睛特征点定位的方法,可定位出两个嘴角点和上唇最高点及下唇最低点,如图4-17所示。
在程序中定义了一个数据结构MouthPoint:

然后定义了一个以MouthPoint为返回值的函数FillMouth(int currentx,int currenty,int left,int right,int top,int bottom)。通过这个函数来返回嘴巴的位置坐标。
 (https://www.daowen.com)
(https://www.daowen.com)
图4-17 嘴部特征点定位
(5)鼻孔的定位 在眼睛和嘴巴之间用一定的规则可搜索到一对小的连通区域,位于脸部中线的两侧,很靠近中线。实验证明,这一对连通区域恰好就是由两个鼻孔形成的区域。
在程序中定义了一个数据结构NostrilPoint:

然后定义了一个以NostrilPoint为返回值的函数FillNostril(int currentx,int currenty,int left,int right,int top,int bottom)。通过这个函数来返回鼻孔的位置坐标。图4-18给出鼻孔特征点定位程序实现的效果图。

图4-18 鼻孔特征点定位
4.面部器官特征形状提取
(1)眼睛模板 眼睛使用一个圆和4段抛物线来拟合描述。眼睛拟合效果如图4-19所示。
上眼皮拟合:以上眼皮最高点为顶点和分界点,在其两边各画一段抛物线。对应抛物线方程是
y=-ki(x-x1)2+y1 (i=1,2) (4-20)
式中,(x1,y1)是上眼皮最高点;k1、k2分别是左、右抛物线段的系数,ki>0。
下眼皮拟合:以下眼皮的最低点为顶点和分界点,在其两边各画一段抛物线。对应的抛物线方程是:
y=ki(x-x2)2+y2 (i=3,4)
式中,(x2,y2)是下眼皮最低点;k3、k4分别为左、右抛物线段的系数,ki>0。
虹膜边缘对应的圆为

式中,(xc,yc)是虹膜中心坐标;r为圆的半径。
(2)眉毛的拟合 眉毛的拟合与眼睛类似,这里就不再详细介绍了。
(3)嘴部外唇拟合 因为嘴部外唇边缘线一般较长,所以如果只用4段抛物线插值来拟合嘴部边缘线,并不能得到很好的效果。所以,嘴部边缘线的拟合需要定位更多的特征点,采用逼近的方法来达到较好的拟合效果。根据两个嘴角点位置,将整个嘴部在横坐标方向上分为20个小段、21个端点。在每一个的端点上,用一条垂直线与嘴唇边缘求交点,得到在该端点位置上的上下外唇纵轴坐标,共有42个坐标。受二值化图像效果的影响,这些坐标中可能会有几个与实际边缘线位置相差较大,根据嘴部边缘线的连贯性,剔除掉这几个坐标,用相邻值的插值来代替。根据曲线拟合的数学知识,当型值点较多时,构造插值函数通过所有的型值点是相当困难的。这时,一种较好的解决办法是,选择一个次数较低的函数,使其在某种意义上最为接近于给定的数据点,称之为对这些数据点的逼近。使用最小二乘法来生成逼近曲线。
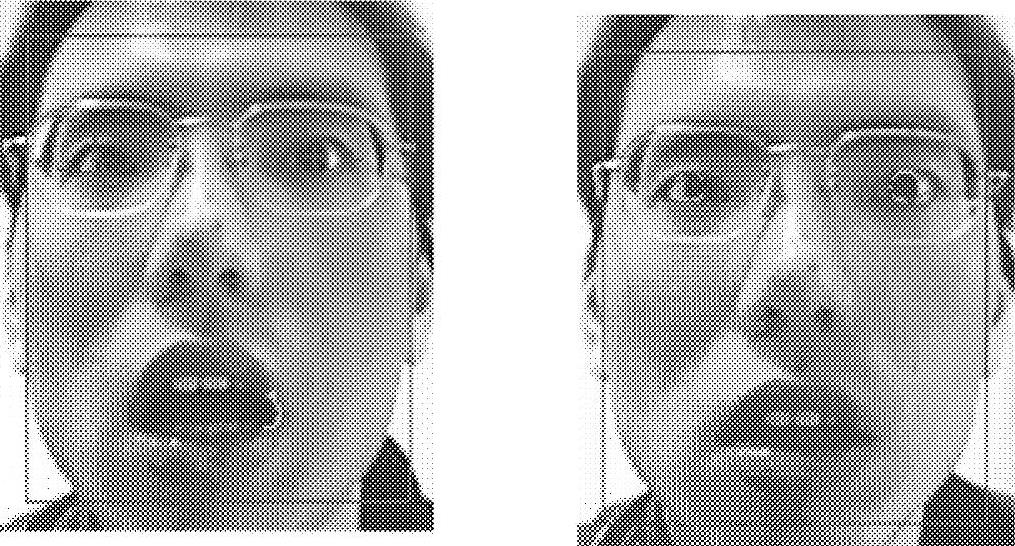
图4-19 眼睛拟合效果
构造逼近函数y=f(x)。令f(x)为m次多项式,则有

逼近的程度可通过使各点的偏差的二次方和来度量。求解以下函数极值来得到各系数αj:

将求出的系数αj代入多项式函数f(x),即可得到所求的逼近函数。
利用该方法,得到外嘴唇轮廓的较好的拟合。
(4)鼻孔的拟合 鼻孔对应的圆方程为
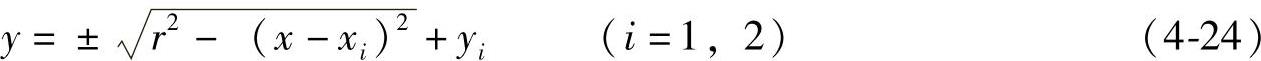
式中,(x1,y1)、(x2,y2)分别为左右鼻孔的中心坐标;r为圆的半径。
嘴巴和鼻孔拟合效果如图4-20所示。

图4-20 嘴巴和鼻孔拟合效果
5.表情识别
在成功地提取出了人脸面部器官轮廓以后,就需要在此基础上对表情进行建模,以实现表情识别。所谓人脸表情识别(Facial Expression Recognition),实际上就是对人脸的表情信息进行特征提取分析,按照人的认识和思维方式加以归类和理解,利用人类所具有的情感信息先验知识使计算机进行联想、思考及推理,进而从人脸信息中分析理解人的情绪,如快乐、惊奇、愤怒、恐惧、厌恶和悲伤等。
用计算机来自动识别人脸表情是一个非常复杂的问题,这是因为:
1)表情具有多样性及多变性的特点,不同国家、不同民族人的表情是不尽相同的,而且即使是同一种族的人,由于表情的多样性及个人的个性、习惯所致,表情也不尽相同。如何定义通用的表情分类,这是一个心理学家和生物学家研究了多年的问题,但至今也没有一个统一的标准。
2)实时表情识别要求计算机对人脸及五官的模式识别有较高的能力,但由于计算机本身没有知识和经验,这就对算法提出了很高的要求,而且计算机图片的质量受到环境、光照等很多条件的影响,这又进一步加大了识别的难度。因此很多基于静态人脸库的表情识别方法被提了出来,但如何进行准确、实时的表情识别,到目前为止还没有一个非常好的办法。
本节在上面精确地提取了人脸面部特征的基础上,分析了面部器官的运动方向,使用HMM设计并实现了实时的表情识别系统,达到较好的识别效果。系统设计框图如图4-21所示。
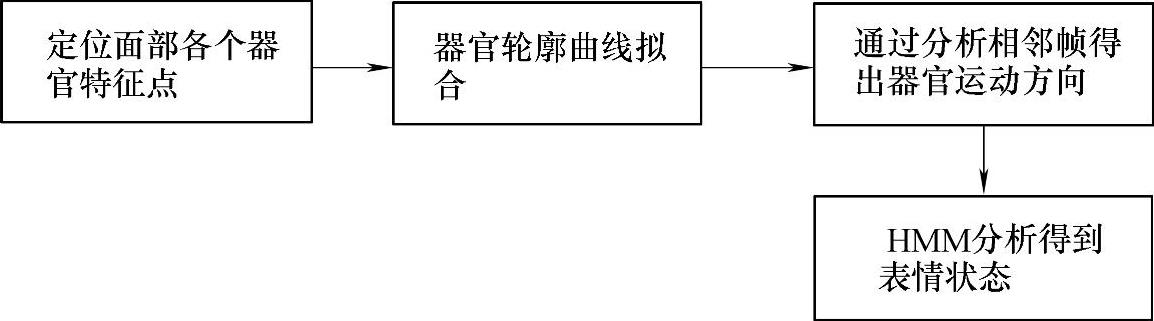
图4-21 系统设计框图
6.表情的分类设计
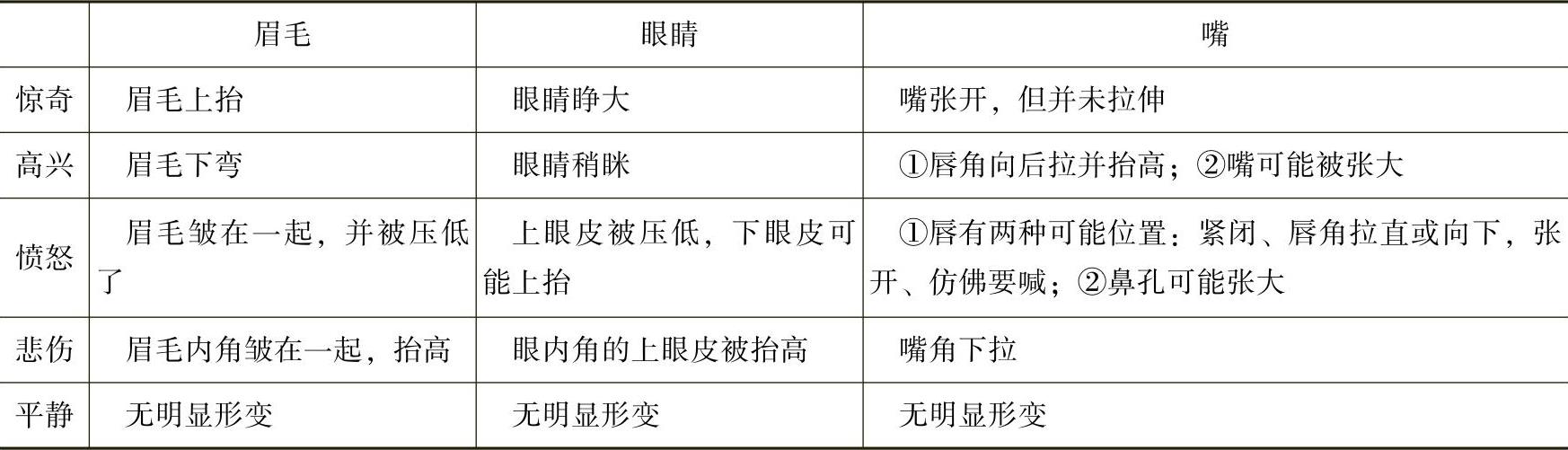
上面提到了表情的分类是一个复杂的问题,到目前为止,还没有一个统一的表情分类标准。但它又是一个热门话题,有不少人在对其进行研究,并提出了一些表情分类方法。其中,Ekman(埃克曼)依据心理学和解剖学的原理,对表情进行了分类。他的分类方法是目前用得最广的。本节参照了Ekman的表情分类方法,定义了5种表情:平静、惊奇、高兴、愤怒、悲伤。表情及相应面部器官动作见表4-1。
表4-1 表情分类表
7.表情建模
在检测出各个面部器官后,并有了分类依据以后,下面的任务就是要分析出表情来。一种方法是基于单帧的方法,设定几个阈值来判定表情。但基于单帧的方法由于对不同的人使用了固定的相同阈值,而每个人的表情姿态各不相同,一般得不到好的结果。另一种方法是利用面部器官的运动信息来识别表情,因为即使是不同的人,对于同一种表情也会有相似的面部运动趋势,而这种方法正好利用了面部运动信息,所以能达到较好的识别效果。
本节采用第二种思路,希望能通过分析面部器官的运动特征来得出表情状态,以达到较好的识别效果。
为了能够较精确地识别表情,必须对表情进行建模。在建模时,考虑到即使是不同的表情,某些面部器官的运动状态却往往有相似的地方,所以必须采用一种能够有效描述状态与观察态之间关系的方法来建模。HMM方法就是一种很好地描述状态与观察态之间对应关系的方法。
因此,本节提出了基于HMM的表情建模方法。对每一种器官的动作建立一个HMM。先观察连续几帧间的同一种器官的运动状态,根据HMM可以得出最佳的表情状态序列,然后统计出这一表情序列中各个表情状态的百分比,再根据各个器官的统计结果进行加权(一般而言,嘴部的运动最明显,对情感的表示也较为准确,所以赋予的权值较大,眼睛和眉毛的权值相对较小),得出综合的表情状态百分比,取比率最高的作为识别结果。实验证明,我们的模型可以达到很高的表情识别率。下面对于一种器官先来确定出HMM的参数。HMM可以通过以下参数来描述:
1)元素N:它表示模型中的状态个数。令状态空间为S={S1,S2,…,SN},每一个状态对应一种表情状态。
2)元素M:表示出每一个状态可观察到的不同符号数。各个符号表示为V={V1,V2,…,VM},每一种符号对应该器官的一种运动状态。
3)状态转移概率分布A={aij},其中,aij=P[qt+1=Sj|qt=Si](1≤i,j≤N),描述了各种表情之间的转移概率,状态转移概率分布由经验值预先设定。
4)状态j中可见符号的概率分布B={bj(k)},其中,bj(k)=P[在t时刻出现符号为V|qt=Sj],1≤j≤N,1≤k≤M,描述了一种表情状态中,一种器官各个运动状态的概率分布。
5)初始状态分布π={πj},其中,πj=P[q1=Sj],1≤j≤N。初始状态分布也由经验值预先确定。
利用前向-后向算法解出最佳状态,定义:
(1)前向变量:
αt(i)=P(O1O2…Ot,qt=Si|λ)
1)初始条件:α1(i)=πibi(O1) (1≤i≤N)
2)归纳:
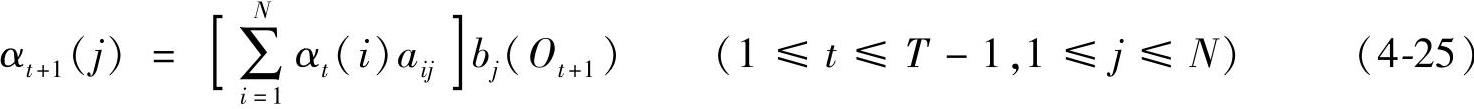
3)结果: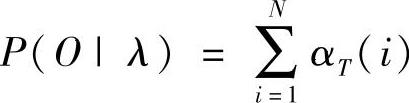
(2)后向变量:
βt(i)=P(Ot+1Ot+2…OT|qt=Si,λ)
1)初始条件:βT(i)=1 (1≤i≤N)
2)归纳:
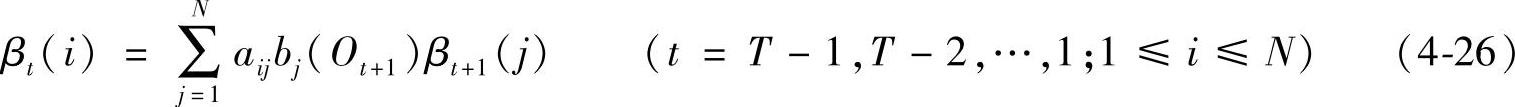
(3)变量:
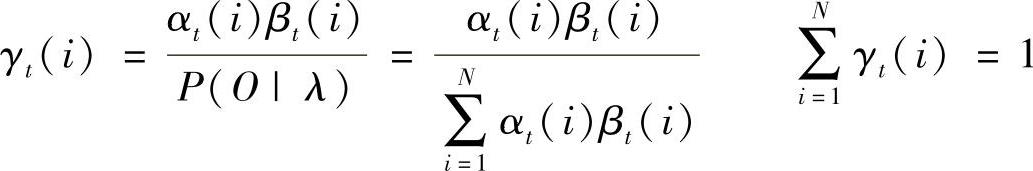
问题的解即表情状态qt为
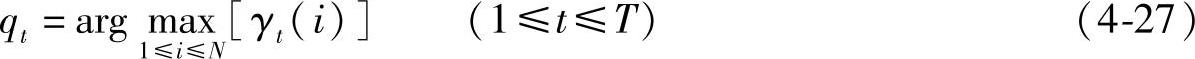
在得到状态序列qt后,就可按照上面提到的方法,对各个状态序列中的统计结果进行加权综合,选出综合比率最高的表情作为识别结果。
在图4-22中,给出了几种表情的识别结果。用曲线拟合出眼睛、嘴和鼻孔的轮廓边缘,用圆标记出瞳孔。

图4-22 实时表情识别结果:惊奇,高兴,悲伤和愤怒
8.实验结果
本节设计的系统用这最基本的4种表情做实验,以每秒15帧的速率,在Pentium Ⅳ、1.70GHz、CPU又没有任何特殊硬件的PC上,对于20个人的不同表情统计识别结果,识别的正确率达到75%以上。下一步的工作是进一步完善本节中所讨论的系统,即从识别技术及表情模型两方面入手,争取做出一套对于人物表情识别实用性更强、效果更好的系统。我们相信随着模式识别、情感计算、心理学等研究的进一步发展,实时的表情识别技术一定会取得更大的突破,将来一定能够很好地为人们的生活服务。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。






