1.Fermi架构
Fermi架构是NVIDIA发布的第三代流多处理器(Streaming Multiprocessor,SM)架构。为能够更适合通用计算的需求,Fermi架构从底层计算单元、内存系统到芯片整体架构都进行了全新的设计。Fermi共集成了将近30亿个晶体管,最多可拥有512个CUDA核,它们分属于不同的SM,每个SM单元拥有32个CUDA核。这样,Fermi架构可最多拥有16个SM。图3-2显示了NVIDIA Fermi的整体架构。
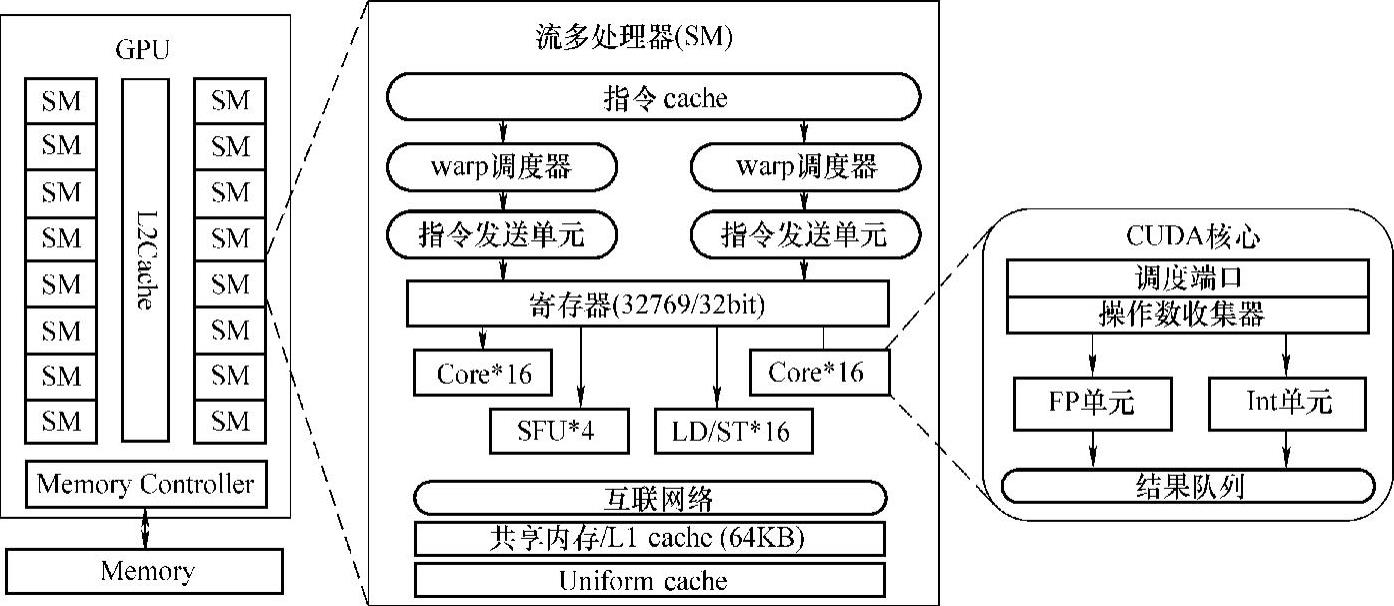
图3-2 NVIDIA Fermi架构
如图3-2所示,NVIDA Fermi采用了三层的体系架构。第一层由若干共享L2cache的可扩展流阵列SM组成。不同型号的GPU,SM的数量可能会不相同。如NVIDIA Tesla C2050 GPU拥有14个SM。不同SM的执行是相互独立的。第二层为流多处理器(SM)。SM是一个高度并行处理器,最多支持48个warp的并发执行。每个SM上由两个warp调度器、32个CUDA核心、4个SFU(Special Function Units,特殊函数处理单元)和16个LD/ST(Load/Store Unit,存取单元)构成。第三层为CUDA核心。CUDA核心是GPU最基本的指令执行单元,每个时钟周期可执行一条逻辑运算指令、单精度浮点数或者32位整数运算指令。每个CUDA核心由一个FP(Float Point,浮点)计算单元和一个Int(整型)计算单元组成。这里要强调的是,CUDA核心中并没有指令部件,其执行的操作由SM的指令发送单元控制。在Fermi架构中,Int计算单元已经可以进行32bit的整型数运算,而不像GT200架构中仅仅支持24bit的整型数运算。
在Fermi架构中,需要关注以下三点:
(1)可配置的缓存结构
Fermi架构的每一个SM中拥有64KB的片上缓存,可作为共享存储器(SharedMemory)或者L1 cache,用户可自行指定其大小。如可以设置为48KB的共享存储器和16KB的L1 cache,或者是16KB的共享存储器和48KB的L1 cache。共享存储器作为对程序员可见的片上存储资源,具有较高的访存带宽和访存效率,可减少对片外资源的访存次数,实现数据共享和位于同一线程块内的线程间的通信。L1 cache可用于处理寄存器溢出、堆栈等操作。使用L1 cache可缓解由于寄存器溢出而导致的程序性能的急剧降低。图3-3显示了Fermi架构可配置的缓存结构。
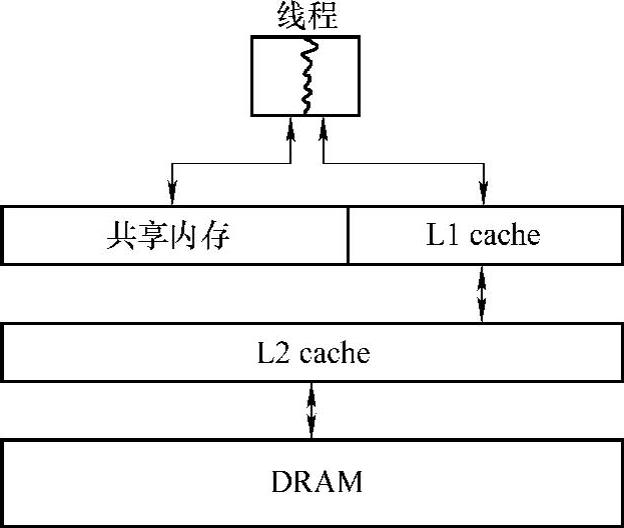
图3-3 可配置的缓存结构
(2)硬件资源的限制
在GPU编程中,要注意硬件资源的限制。如在Fermi架构中,每个SM只有32KB的寄存器和64KB的共享存储器/L1 cache。这是有限的硬件资源,如果每个线程使用过多的寄存器或者共享存储器,就会影响SM中并发执行的线程数量,可能会导致由于并发线程数目过少而不能隐藏访存延迟,从而导致性能的降低。而许多优化方法,如循环展开、向量化操作等。一方面会提升程序的性能;另一方面也会增加每个线程的寄存器使用数目,从而导致性能的降低。因此,GPU这种硬件资源的限制,导致了优化空间的不连续性。GPU程序的优化很大程度上是许多优化方法相互平衡、相互折中的过程。
(3)SM单元的双warp调度能力
在CUDA编程模型中,采用多线程调度机制。执行和调度单元为由32个线程组成的warp。在Fermi架构中,每个流多处理有两个warp调度单元和两个指令发送单元。这就允许两个warp可以同时调度执行,每个warp由SM内的其中一组16个CUDA核心调度执行。由于warp执行的相互独立性,调度器没有必要检查指令流的依赖性,两个warp可并行执行。因此,在GPU程序优化中,要保证每个SM至少分配两个warp,才能充分利用硬件资源。在实际应用中,我们需要在每个SM上部署足够的warp,通过warp的相互切换执行来隐藏访存延迟。
此外,Fermi架构的存储系统提供了纠错码技术(Error Correcting Code,ECC)。一方面,提高了大规模并行应用的可靠性;而在另一方面,也增加了访存延迟,降低了访存带宽的利用率。
2.Kepler架构
为了提高GPU的性能/功率比,NVIDIA在Fermi架构的基础上研发Kepler架构。相比于Fermi架构,Kepler主要在以下几个方面进行了改进。
(1)缓存结构的改进
Kepler架构支持统一内存加载和存储请求,每个多处理器有一个L1 cache、共享内存、L2cache和动态随机存储器(Dy-namic Random Access Memory,DRAM)内存。此外,Kepler还为编译器指示为只读的数据增设一个新的只读数据缓存,如图3-4所示。
在Kepler架构中,每个SM有64KB的片上存储器,可配置为48KB的共享内存和16KB的L1缓存,或配置为16KB的共享内存和48KB的L1 cache,此外还支持共享内存和L1 cache各以32KB划分,如图3-5所示。
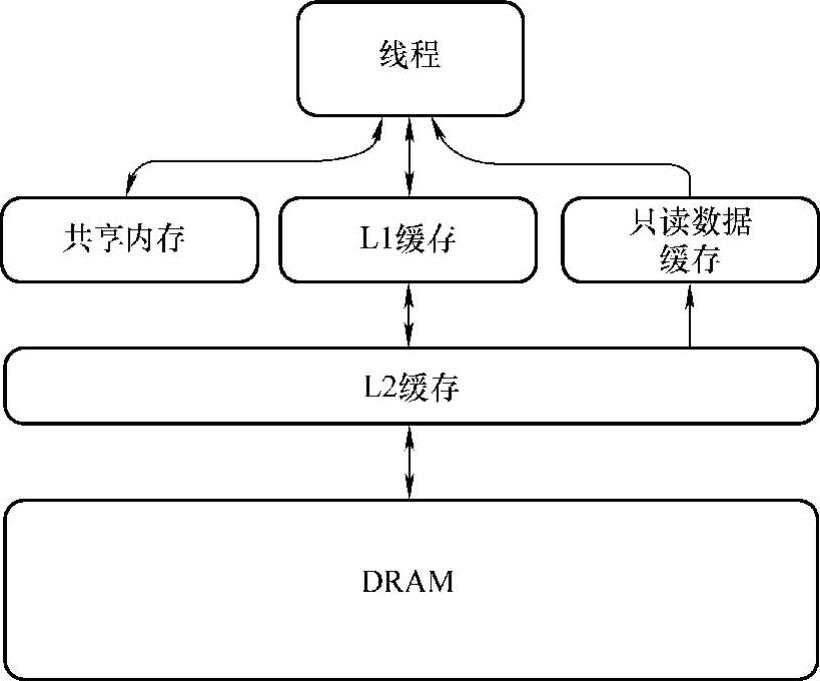
图3-4 Kepler缓存结构
除L1 cache之外,Kepler为只读数据引入48KB cache。在Fermi架构中,该cache只能由纹理单元访问。使用只读数据cache可有效提升程序性能,因为它可以减少对共享内存/L1 cache的使用。此外,只读数据cache以更高的带宽支持全速非对齐内存访问模式。该cache的使用是由编译器自动管理(通过参数C99访问任何变量或称为常量的数据结构):使用关键字“const_restrict”可“通知”编译器该部分数据使用只读数据cache加载。
Kepler GPU具有1536KB的专用L2 cache,是Fermi架构中L2 cache的2倍。L2 cache是主要数据统一点,处理所有加载、存储和纹理请求并提供跨GPU之间有效、高速的数据共享。Kepler上的L2 cache提供的每时钟带宽是Fermi中的2倍。
 (https://www.daowen.com)
(https://www.daowen.com)
图3-5 Kepler SM架构
(2)warp调度机制的改进
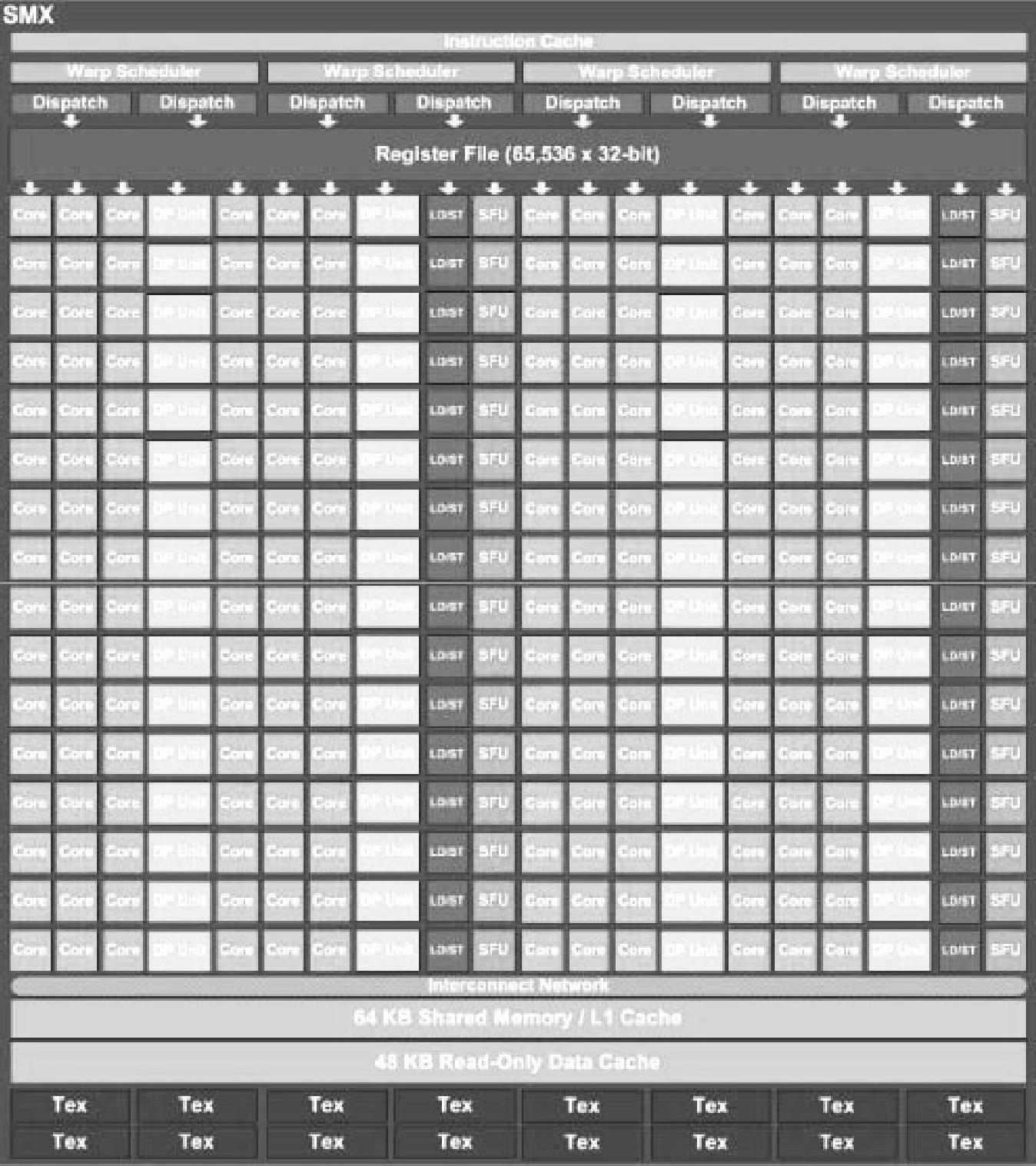
如图3-6所示,每个SM单元包含192个单精度CUDA Core、64个双精度单元(DP Unit)、32个特殊功能单元(SFU)和32个加载/存储单元(LD/ST),4个warp调度单元,8个指令分发单元。在SM上,4个warp可同时调度执行。Kepler的Quad warp Scheduler选择4个warp,并且每个warp可并行执行两条独立的指令。Fermi不允许双精度指令和其他指令配对,而Kepler允许双精度指令和其他指令配对,例如加载/存储指令、纹理指令以及一些整数型指令。
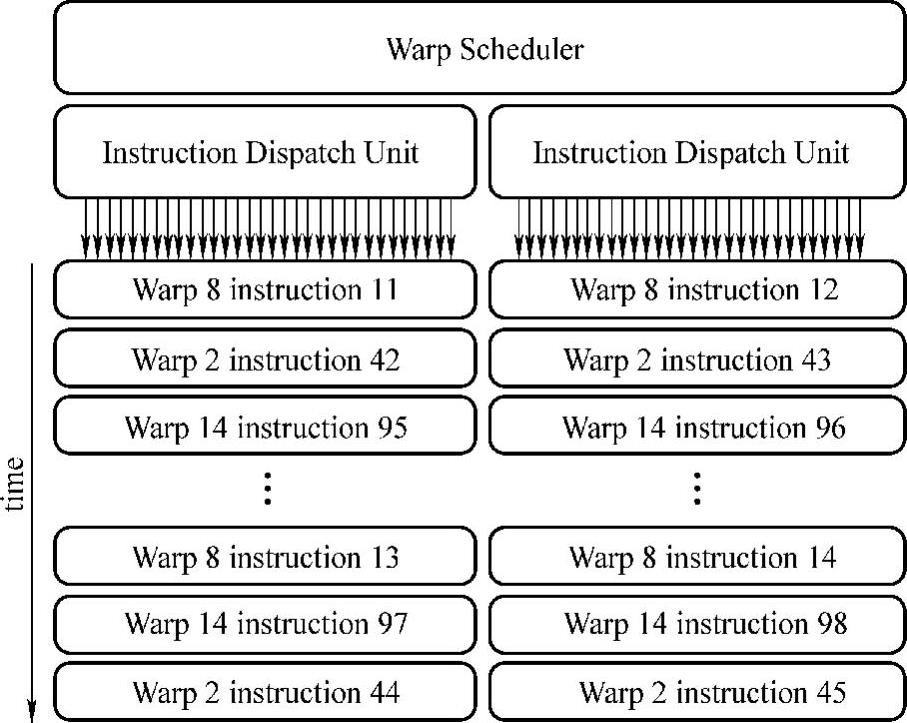
图3-6 Kepler Warp调度机制
(3)硬件资源的增多
在Kepler上,可由线程访问的寄存器数量最多是255个,Fermi架构只有63个,这大大提高了在Fermi架构中存在较大寄存器压力或寄存器泄露行为的代码的性能。
(4)原子运算的改进
原子内存运算允许并发线程对共享数据结构执行正确的读-修改-写运算。Kepler全局内存原子运算的吞吐量较Fermi有大幅度提高。普通全局内存原子运算的吞吐量相对于每频率一个运算来说提高了9倍。独立全局内存原子运算的吞吐量也明显加快,而且处理地址冲突的逻辑更加有效。原子运算通常可以按照类似全局负载运算的速度进行处理。该性能的提高使得原子运算可以在kernel内部的循环中使用,这消除了之前一些算法在对不同block(线程块)的计算结果进行规约计算时所需要的额外传递操作。
此外,为了进一步提高性能,Kepler架构引入了Shuffle指令,允许同一warp内的线程可不通过共享内存进行通信和数据共享,如图3-7所示。此前,warp内线程之间的数据共享需要通过共享内存实现。使用Shuffle指令,线程可以读取同一warp内其他线程的任意变量的值。Shuffle支持任意索引引用(即任何线程读取同一warp内的任何其他线程)。Shuffle性能优于共享内存,因此数据存储和加载操作能够一步完成。Shuffle也可以减少每个block所需的共享内存的数量,因为数据在warp内的交换不需要通过共享内存。
3.Maxwell架构
Maxwell架构是Kepler架构的升级。相比于Kepler架构的GPU,Maxwell的SM有着很大的不同。每个SM有4个warp调度器,每个warp调度器每个时钟周期能调度两个相互独立的指令。Maxwell SM分为4个独立的处理块,每个处理块具备自己的指令缓冲区、调度器以及32个CUDA核心,如图3-8所示。新的划分方法简化了设计与调度逻辑,节省了晶体管与能耗,降低了计算延迟。
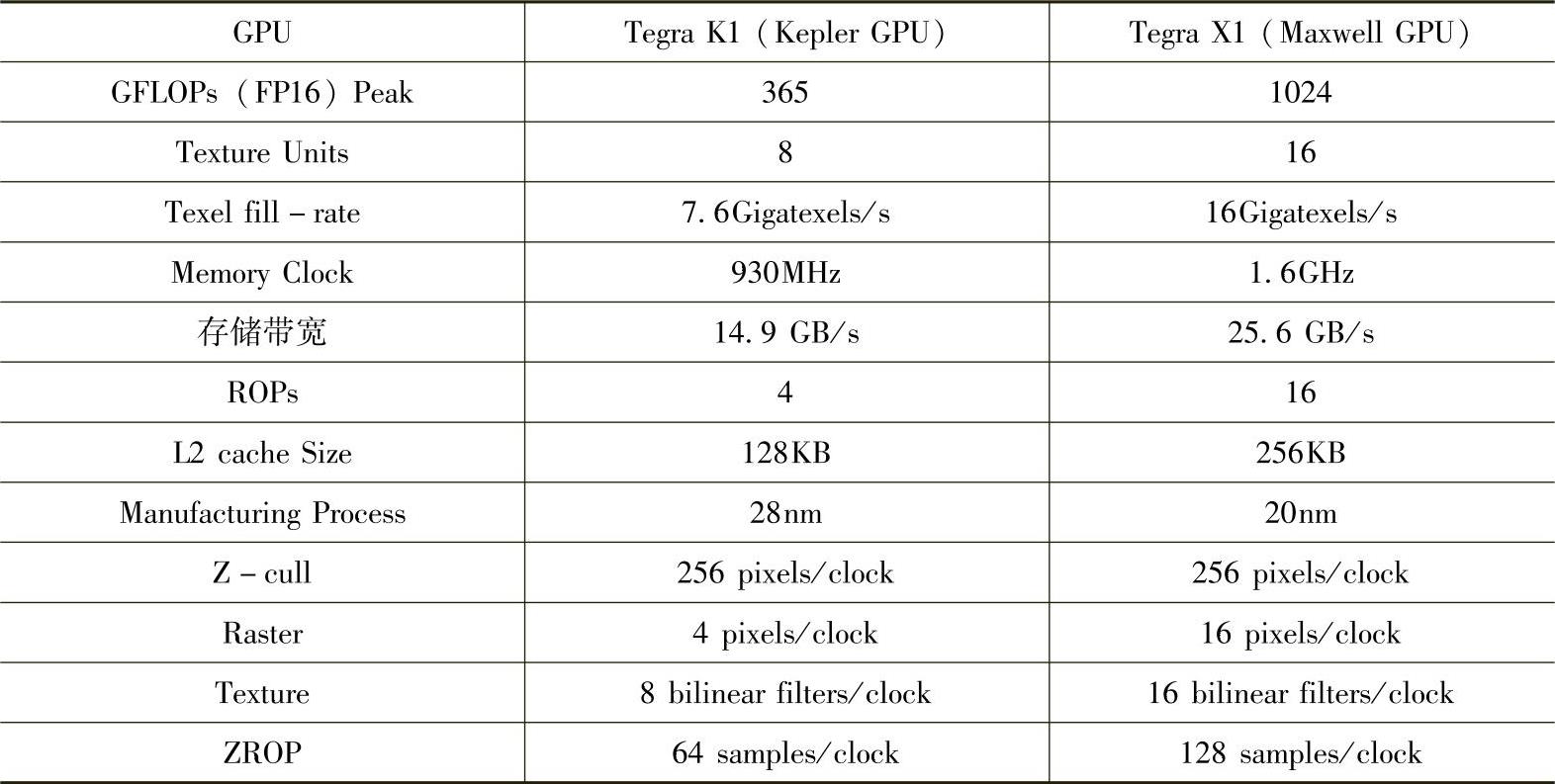
与Kepler架构相比,Maxwell架构的SM的内存层次结构也发生了变化。在Kepler架构中,一共有64KB的空间大小,供共享内存和L1cache分配。在Maxwell架构中共享内存和L1cache分开了,共享内存大小是96KB。此外,Maxwell采用了容量大增的二级高速缓存设计,Maxwell核心架构中二级高速缓存容量为2048KB,而Kepler中的容量仅为256KB。由于片上高速缓存容量更大,因此需要向显卡DRAM发送的请求更少,从而降低了整体显卡能耗,提升了性能。如表3-1所示,是Kepler GPU与Maxwell GPU的差异。
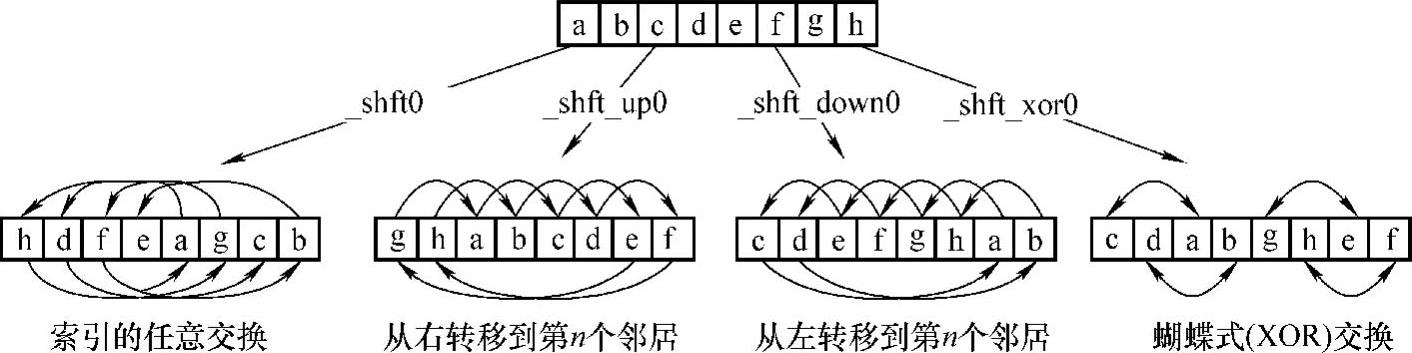
图3-7 Shuffle指令

图3-8 Maxwell架构
表3-1 Kepler GPU与Maxwell GPU具体参数

(续)
4.Pascal架构
Pascal架构是最近NVIDIA公司推出的一款针对高性能并行计算的GPU架构。与Maxwell和Kepler相比,虽然每个Pascal SM只有64个单精度CUDA核,是Maxwell SM中CUDA核数的一半,但总的SM数目增加了,每个SM保持与上一代相同的寄存器组,则总的寄存器数目增加了。这意味着Pascal上的线程可以使用更多寄存器,也意味着Pascal相比旧的架构支持更多线程、warp和线程块数目。从Pascal SM架构图中可以看到,一个Pascal SM分成两个处理块,每块有32768个32位寄存器、32个单精度CUDA核和一个warp调度器。与此同时,Pascal总共享内存量也随SM数目增加而增加了,带宽显著提升。此外,Pascal SM还拥有32个DP Unit,即双精度计算单元,支持64位双精度浮点计算。相比Kepler架构,Pas-calSM架构简化了数据通路,占用面积更小,能耗更低。Pascal SM架构提供更高级的调度和重叠载入/存储指令来提高浮点利用率。相比Maxwell,Pascal SM调度器架构更智能,具备高性能、低能耗特性。1个warp调度器(每个处理块共享一个)在一个时钟周期内可以分发两个warp指令,如图3-9所示。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。





