本节将会以双线性插值方式为例,以Naive_gpuResize_Linear基本实现为起点,通过线程与数据一对多的对应关系,频繁对global memory的不规则访问操作尽量转化为对share memory的访问等优化策略,以最大限度地提升算法性能。
1.向量化
Naivegpu_Resize_Linear基本实现的线程数与图像像素点为一一对应关系,如图5-23所示,处理16个像素点,需要开启16个线程。此处为了使线程的利用率提升,使用向量化操作。值得注意的是,此处的向量化并非像素点的向量化操作,而是线程-像素点之间的一对多的映射关系,以本小节为例,此处的向量化的线程-数据映射关系为1∶4,即一个线程负责4个像素点的resize操作,如图5-25所示。
由图5-25可得,处理16个像素点只需调度4个线程,即线程0负责处理像素点0、4、8、12,线程1处理像素点1、5、9、13,如此类推。由于resize的计算操作最主要为公式(5.2)的运算,十分简单,一个线程处理一个像素点导致线程的工作量过低、利用率不高等现象,通过向量化优化,适当调整线程与像素点的映射,线程可以在其生命周期内负责更多的工作,提高其工作效率。
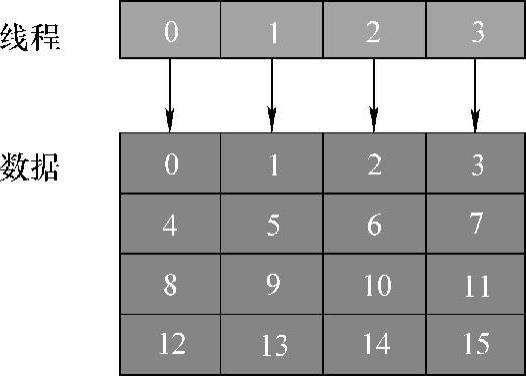
图5-25 线程-数据的1∶4映射
此版本的resize算法,由于适当地为线程分配工作量,在通道1和通道3时,运行时间分别为0.0879ms和0.3228ms。
2.global memory写入优化
在通道数为3时,相邻线程每一次对global memory的写入都相隔两个单元数据,设通道3的一个像素点包含3个单元数据,因此相邻线程的每一次写入,都是不连续的,线程访存方式如图5-26所示。线程0负责0号像素点的写入,而每个像素点包含RGB三种单位数据,因此需要三次写入操作,才能完成一个像素的写入,因为连续线程并非写入连续的存储数据,因此可能带来性能的下降。
依据第3章和第4章对global memory的优化经验,连续线程访问连续单元数据的访问方式将会带来较大的性能提升,因此,此处利用share memory作为中转内存空间,通过把源图像的像素点数据读入并进行resize计算,写入share memory中转空间,然后通过适当的线程映射关系再把share memory数据拷贝至目标图像的global memory空间,从而实现相邻线程对单元数据的合并访问。如图5-27所示,当线程0、1、2一次性写入0号像素点的3个单元数据时,其对global memory的访问方式是连续的,同样,经过三次相同操作,完成对三个像素点的合并写入,此过程需要运用share memory暂存resize后的结果数据,而从暂存区写回global memory为图5-27的合并访问操作。(https://www.daowen.com)
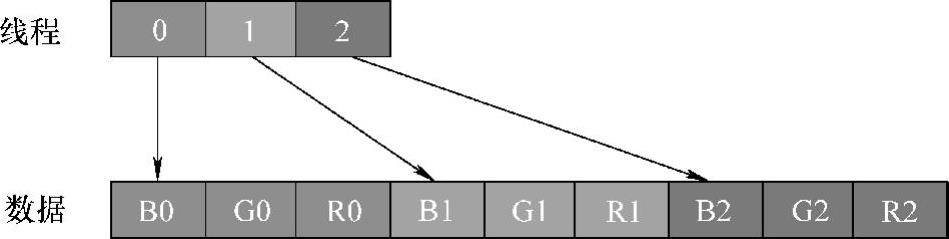
图5-26 通道数为3时线程访问数据映射关系
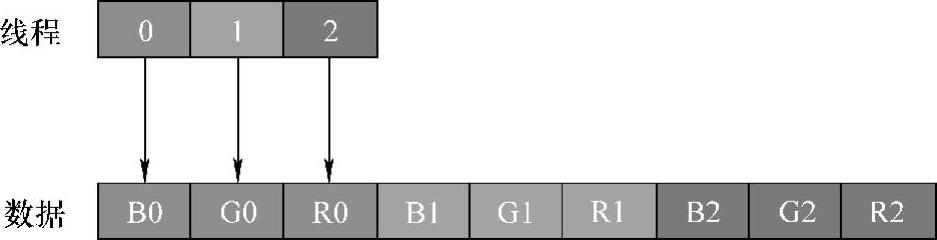
图5-27 通道数为3时线程合并访问数据映射关系
此版本在通道1和通道3的运行时间为0.1127ms和0.3613ms。
3.数据读取方式优化
由图5-24和公式(5.2)可知,当需要计算目标矩阵像素点时,需要取出该像素点在源图像中对应的虚拟坐标周边四个角的实际像素点,在取出四个点时,需要跨越源图像的两行进行取数,这种对global memory非合并的访问方式严重影响了算法性能,当通道数越大时,则带来的性能下降越严重。
除此以外,可以发现,resize算法在进行放大的情况下,其比例意味着映射至源图像的规模越小,其规模与源图像/目标图像的X、Y方向的比例呈线性关系,即同等规模的线程块block内,所需要的源图像数据越少,即存在的重复存取情况越多。此时将可预测大小的源图像块拷贝至share memory内,进行resize计算时,block内线程通过适当的坐标映射,在share memory进行数据的读取即可,此过程可以将多次的对global memory的非合并访问操作简化为一次globalmemory的合并访问操作和多次的share memory的访问操作,由第5.3节并行矩阵转置算法利用local memory进行对global memory合并访问分析可知,相对于CUDA的share memo-ry访问,合并访问与否对性能的影响是很小的。此版本在通道1和通道3的运行时间为0.115ms和0.2199ms。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。





