该功能在未来的0.9.∗版本才展现,这里基于Wiki社区的文档进行一些介绍,通过High Level Consumer Rebalance分析可以知道,Rebalance成功的结果是,订阅的所有Topic的每一个Partition将会被Consumer Group内的一个(有且仅有一个)Consumer拥有。每一个Broker将被选举为某些Consumer Group的Coordinator。某个Cosnumer Group的Coordinator负责在该Consumer Group的成员变化或者所订阅的Topic的Partititon变化时协调Rebalance操作。
(1)Consumer执行机制
1)Consumer启动时,先向Broker列表中的任意一个Broker发送ConsumerMetadataRe⁃quest,并通过ConsumerMetadataResponse获取它所在Group的Coordinator信息。
2)Consumer连接到Coordinator并发送HeartbeatRequest,如果返回的HeartbeatResponse没有任何错误码,Consumer继续fetch数据。若其中包含IllegalGeneration错误码,即说明Coordinator已经发起了Rebalance操作,此时Consumer停止fetch数据,commit offset,并发送JoinGroupRequest给它的Coordinator,并在JoinGroupResponse中获得它应该拥有的所有Partition列表和它所属的Group的新的Generation ID。此时Rebalance完成,Consumer开始fetch数据。
Consumer状态机图如图14-4所示,下面对这些参数进行详细解析。Down:Consumer停止工作。
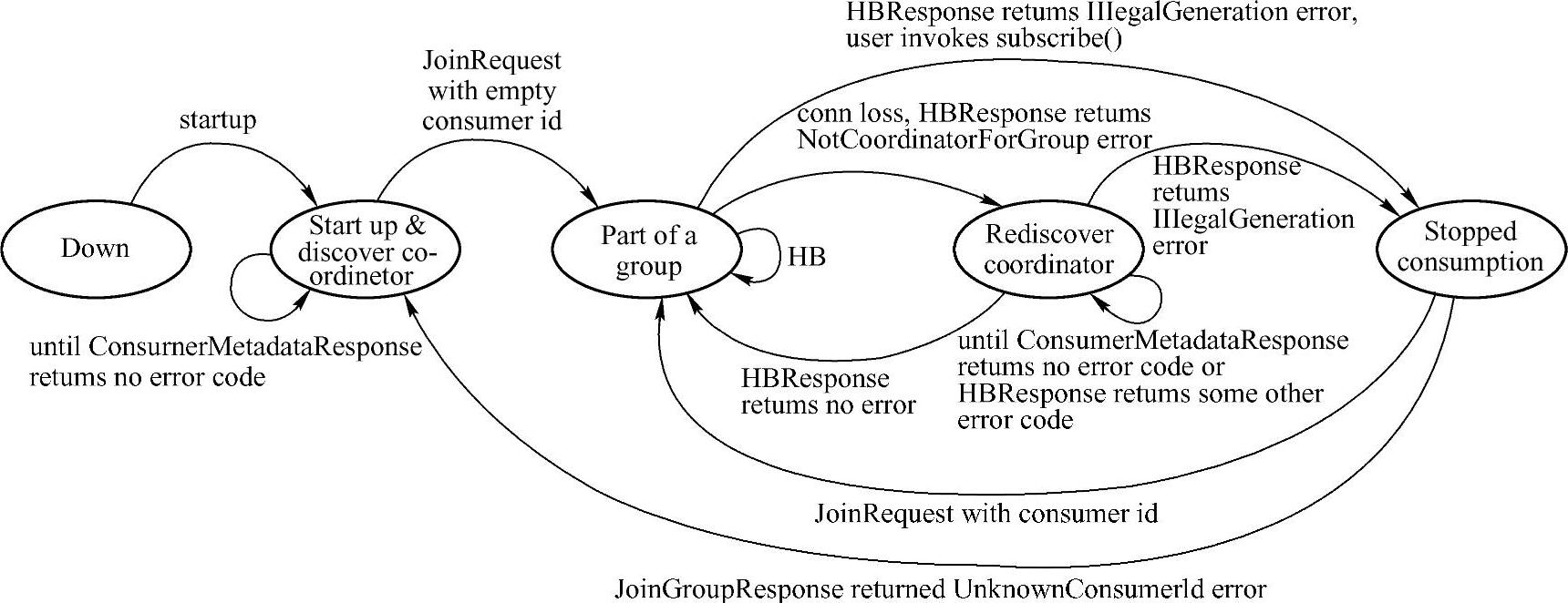
图14-4 Consumer状态机工作流程图
Start up&discover coordinator:Consumer检测其所在Group的Coordinator。一旦它检测到Coordinator,即向其发送JoinGroupRequest。
Partof a group:在该状态下,Consumer已经是该Group的成员,并周期性地发送Heart⁃beatRequest。如HeartbeatResponse包含IllegalGeneration错误码,则转换到Stopped Consump⁃tion状态。若连接丢失,HeartbeatResponse包含NotCoordinatorForGroup错误码,则转换到Rediscover coordinator状态。
Rediscover coordinator:在该状态下,Consumer不停止消费,而是尝试通过发送Consum⁃erMetadataRequest来探测新的Coordinator,并且等待直到获得无错误码的响应。
Stopped consumption:在该状态下,Consumer停止消费并提交offset,直到它再次加入Group。
(2)Consumer故障检测机制
Consumer成功加入Group后,Consumer和相应的Coordinator同时开始故障探测程序。Consumer向Coordinator发起周期性的Heartbeat(HeartbeatRequest)并等待响应,该周期为session.timeout.ms/heartbeat.frequency。若Consumer在session.timeout.ms内未收到Heart⁃beatResponse,或者发现相应的Socket channel断开,它即认为Coordinator已宕机并启动Co⁃ordinator探测程序。若Coordinator在session.timeout.ms内没有收到一次HeartbeatRequest,则它将该Consumer标记为宕机状态并为其所在Group触发一次Rebalance操作。Coordinator Failover过程中,Consumer可能会在新的Coordinator完成Failover过程之前或之后发现新的Coordinator,并向其发送HeatbeatRequest。对于后者,新的Cooodinator可能拒绝该请求,致使该Consumer重新探测Coordinator并发起新的连接请求。如果该Consumer向新的Coordina⁃tor发送连接请求太晚,新的Coordinator可能已经在此之前将其标记为宕机状态而将之视为新加入的Consumer并触发一次Rebalance操作。
(3)CoordinatorRebalance执行机制
①在稳定状态下,Coordinator通过上述故障探测机制跟踪其所管理的每个Group下的每个Consumer的健康状态。
②刚启动或者选举完成后,Coordinator从Zookeeper读取它所管理的Group列表及这些Group的成员列表。如果没有获取到Group成员信息,它不会做任何事情,直到某个Group中有成员注册进来。
③在Coordinator完成加载其管理的Group列表及其相应的成员信息之前,Coordinator将为HeartbeatRequest、OffsetCommitRequest和JoinGroupRequests返回CoordinatorStartupNotCom⁃plete错误码。此时,Consumer会重新发送请求。
④Coordinator会跟踪被其所管理的任何Consumer Group注册的Topic的Partition的变化,并为该变化触发Rebalance操作。创建新的Topic也可能触发Rebalance,因为Consumer可以在Topic被创建之前就已经订阅。
Coordinator状态机图如图14-5所示,下面对这些参数进行详细解析。
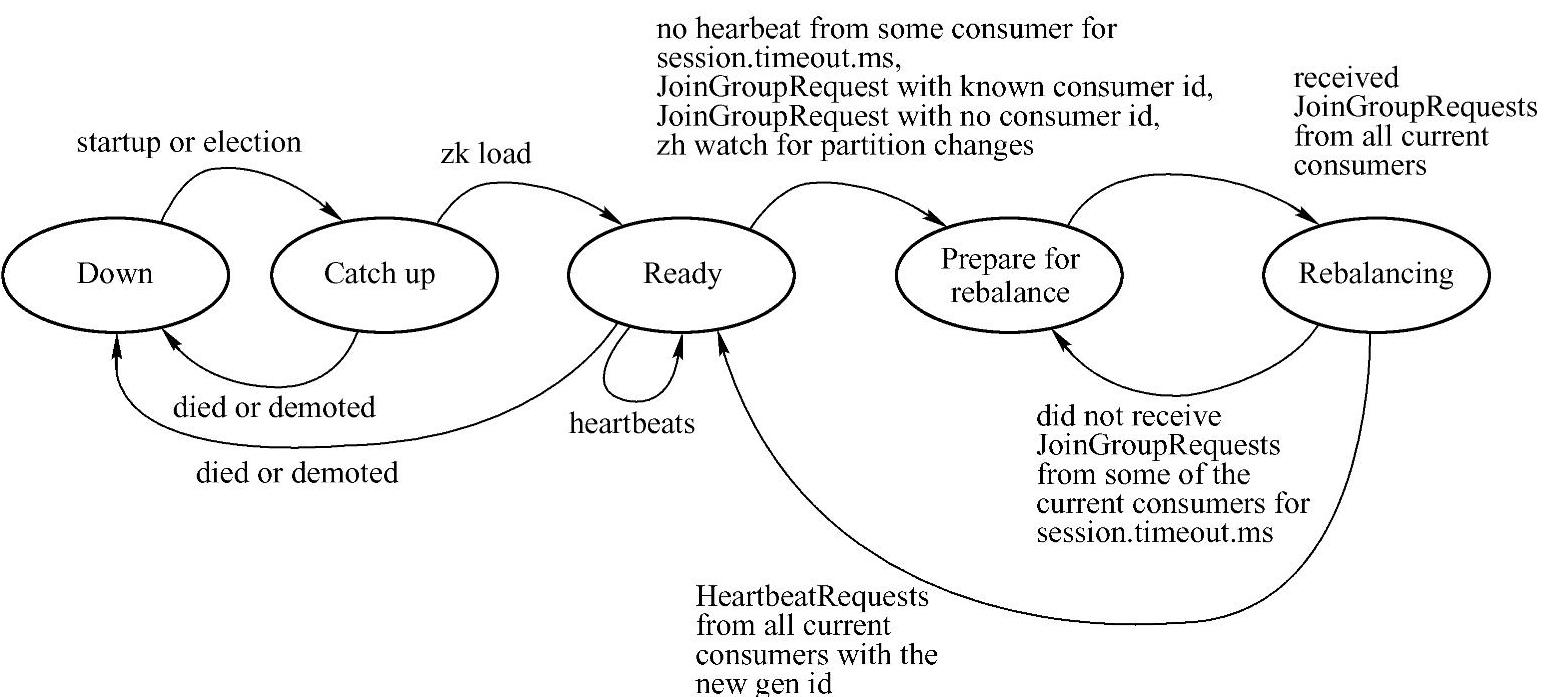
图14-5 Coordinator状态机工作流程图(https://www.daowen.com)
Down:Coordinator不再担任之前负责的Consumer Group的Coordinator。
Catch up:在该状态下,Coordinator竞选成功,但还未能做好服务相应请求的准备。
Ready:在该状态下,新竞选出来的Coordinator已经完成从Zookeeper中加载它所负责管理的所有Group的Metadata,并可开始接收相应的请求。
Prepare for rebalance:在该状态下,Coordinator在所有HeartbeatResponse中返回Illegal⁃Generation错误码,并等待所有Consumer向其发送JoinGroupRequest后转到Rebalancing状态。
Rebalancing:在该状态下,Coordinator已经收到了JoinGroupRequest请求,并增加其Group Generation ID,分配Consumer ID,分配Partition。Rebalance成功后,它会等待接收包含新的Consumer Generation ID的HeartbeatRequest,并转至Ready状态。
(4)Coordinator Failover机制
通过上面的分析,是否对Rebalance执行步骤有全面的了解呢?这里还是先列举出Re⁃balance操作的几个阶段,之后再看Rebalance不同阶段中Coordinator的Failover处理方式。Rebalance执行步骤如下:
①Topic/Partition的改变或者新Consumer的加入或者已有Consumer停止,触发Coordi⁃nator注册在Zookeeper上的watch,Coordinator收到通知准备发起Rebalance操作。
②Coordinator通过在HeartbeatResponse中返回IllegalGeneration错误码发起Rebalance操作。
③Consumer发送JoinGroupRequest。
④Coordinator在Zookeeper中增加Group的Generation ID并将新的Partition分配情况写入Zookeeper。
⑤Coordinator发送JoinGroupResponse。
在Rebalance执行上面几个步骤中,Coordinator都可能出现故障。那么,Coordinator怎样解决这些可能的故障呢?下面给出Rebalance不同阶段中Coordinator的Failover处理方式。
1)如果Coordinator的故障发生在第一阶段(步骤①),即它收到Notification并未及时做出响应,则新的Coordinator将从Zookeeper读取Group的Metadata,包含这些Group订阅的Topic列表与之前的Partition分配。如果某个Group所订阅的Topic数或者某个Topic的Parti⁃tion数与之前的Partition分配不一致,或者某个Group连接到新的Coordinator的Consumer数与之前Partition分配中的不一致,新的Coordinator会发起Rebalance操作。
2)如果失败发生在第二阶段(步骤②),它可能对部分而非全部Consumer发出带错误码的HeartbeatResponse。与第一种情况一样,新的Coordinator会检测Rebalance并发起一次Rebalance操作。如果Rebalance是由Consumer的失败所触发的,并且Cosnumer在Coordina⁃tor的Failover完成前恢复,新的Coordinator不会为此发起新的Rebalance操作。
3)如果Failure发生在第三阶段(步骤③),新的Coordinator可能只收到部分而非全部Consumer的JoinGroupRequest。Failover完成后,它可能收到部分Consumer的HeartRequest及另外部分Consumer的JoinGroupRequest。与第一种情况一样,它将发起新一轮的Rebalance操作。
4)如果Failure发生在第四阶段(步骤④),即将新的Group Generation ID和Group成员信息写入Zookeeper后,那么新的Generation ID和Group成员信息以一个原子操作一次性写入Zookeeper。Failover完成后,Consumer会发送HeartbeatRequest给新的Coordinator,并包含旧的Generation ID。此时新的Coordinator通过在HeartbeatResponse中返回IllegalGeneration错误码发起新的一轮Rebalance。这也解释了为什么每次HeartbeatRequest中都需要包含Gen⁃eration ID和Consumer ID。
5)如果Failure发生在第五阶段(步骤⑤),旧的Coordinator可能只向Group中的部分Consumer发送了JoinGroupResponse。收到JoinGroupResponse的Consumer时,发现在继续向已经失效的Coordinator发送HeartbeatRequest或者提交Offset时会检测到它已经失败。此时,它将检测新的Coordinator并向其发送带有新的Generation ID的HeartbeatRequest。而未收到JoinGroupResponse的Consumer将检测新的Coordinator并向其发送JoinGroupRequest,这将促使新的Coordinator发起新一轮的Rebalance。
本节从Consumer重新设计后的Consumer执行机制、Consumer状态机、Consumer故障检测机制、Coordinator Rebalance执行机制、Coordinator状态机、Coordinator Failover机制入手,对中心协调器(Coordinator)的Rebalance做了详细的分析和总结,这部分内容比较复杂,需要仔细研读。读者也可以结合Kafka wiki社区深入了解这些功能。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。