12.5.4 字符的分类和转换
C++标准程序库包含两个用于处理字符的刻面:ctype和codecvt。这两个刻面均属于lo- cale::ctype类型。ctype主要用于字符分类,此外还提供字母的大小写转换功能,以及在“型别char”和“该facet用以实例化对象的字符型别”之间的转换方法。codecvt用于表示在不同编码间进行字符转换,并主要用于basic_filebuf中的外部表述和内部表述之间的转换。
1.字符分类
ctype刻面是一个模板类,用以针对字符型别实现参数化。其定义的成员和功能见表12-28。ctype<charT>包含以下3个函数:
1)char和charT之间的转换函数。
2)字符分类函数。
3)字母的大小写转换函数。
表12-28 刻面ctype定义的成员和功能
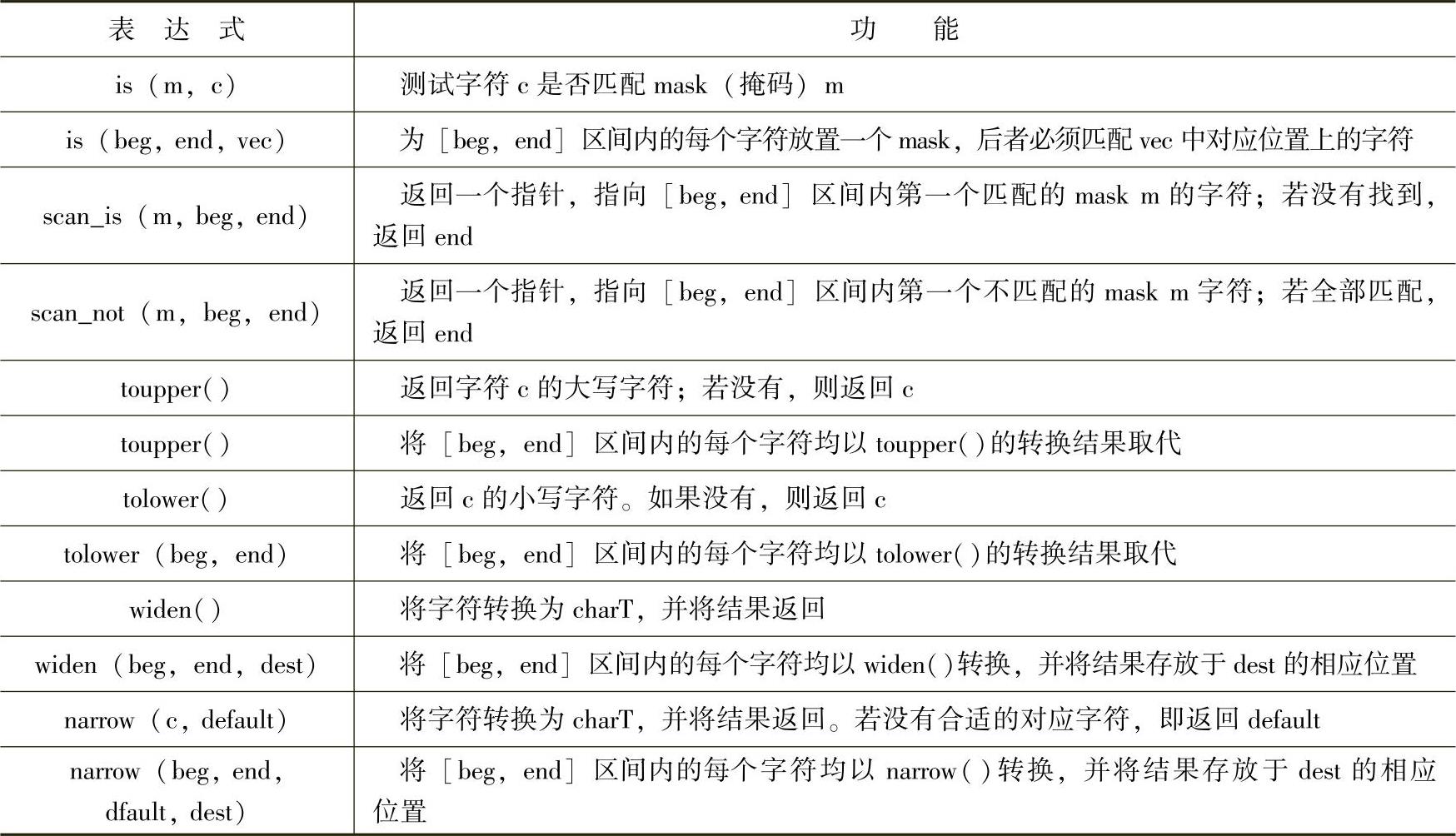
函数is(beg,end,vec)用于在一个数组中存储一系列掩码(mask)。对于beg和end之间的每个字符,在vec所指数组中均有一个对应的mask以及相应的属性。很多字符需要被分类,以避免“字符分类”的虚函数调用操作。
widen()函数用于将一个本地(native)字符集内“型别为char的字符转换为‘locale’所用字符集”内的对应字符,即此函数用于拓宽一个字符。
结果是char型别也无妨。相反,narrow()函数用来将“locale所用的字符集”内的字符转换为native字符集内对应的字符。下面的例子将数字字符由char型别转换为wchar_t型别:

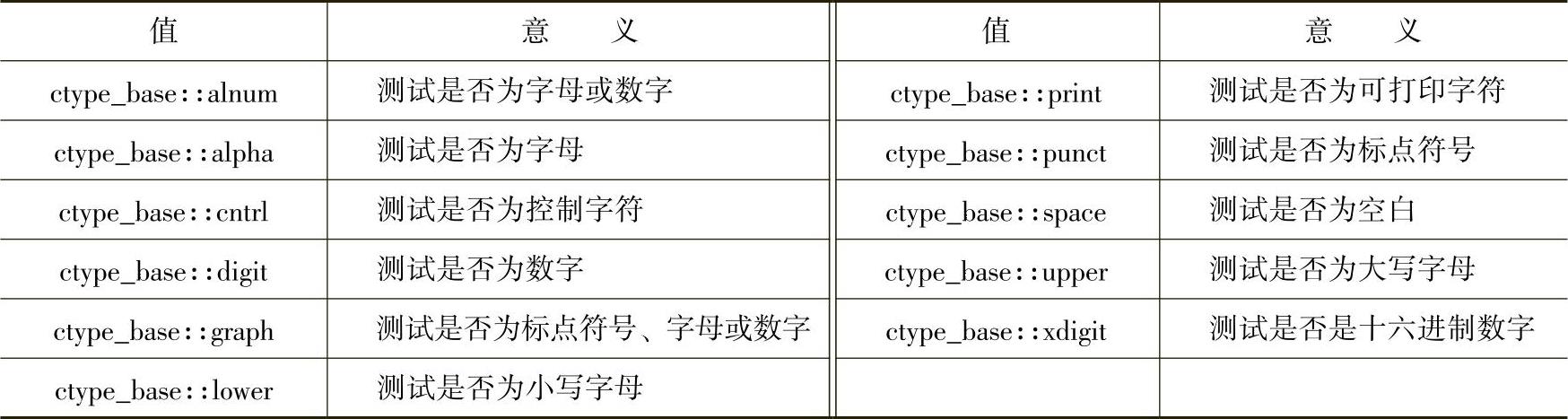
类ctype派生自类ctype_base,此类别仅用于定义一个枚举,名为mask。mask定义一系列值,可用于合成一个bitmask,用以检测字符属性。ctype_base使用的各种字符掩码见表12-29。字符分类的所有函数均需要一个bitmask参数,后者是由ctype_base内的值组合而成。为了获得需要的位掩码(bitmask),要使用各种位操作符(|、&、^和~)。若字符涵盖某个mask所规范的字符内,则该字符必定匹配那个mask。
表12-29 ctype使用的各种字符掩码
2.针对char而做的ctype特化版本
为使字符分类函数获取更佳性能,ctype针对字符型别char有一个特化版本。此特化版本并未将字符分类(is(),scan_is(),scan_not())函数委托给相应的虚函数处理,而是通过查表动作,以inline方式直接实例而得。为此,ctype<char>提供了一些额外的成员函数,详见表12-30。
表12-30 ctype<char>的额外成员函数及其功能

特化版本针对特定的locales,操控上述函数的行为。其做法仅仅是将某个mask表格传递给ctype构造函数作为参数。
静态成员table_size是一个常量,用于指示表格大小,由C++标准程序库实例版本自行定义。其值至少为256。ctype<char>构造函数的第二个参数用于指示“当刻面被销毁时,表格是否应被删除”。若此参数值为true,则当刻面被销毁时,传入构造函数的那个表格会被delete[]释放掉。
保护型成员table()函数返回的是构造函数的第一参数。静态保护成员函数classic_table()返回的是经典的“C”locale中用于进行字符分类的表格。
3.用于字符分类的全局辅助函数
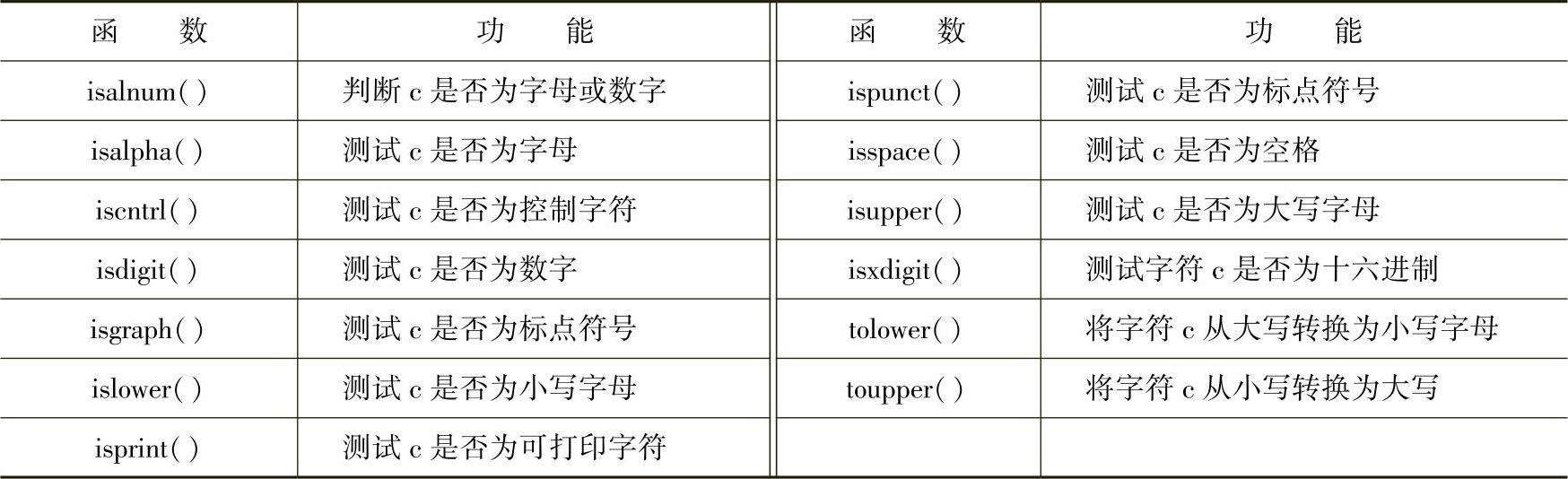
C++标准程序库定义了一些全局函数,可以协助程序员方便地运用ctype刻面。表12-31列出了所有用于字符分类的全局辅助函数。
表12-31 用于字符分类的全局辅助函数
例如,对于表达式确定locale loc中的一个字符c是不是小写字母:
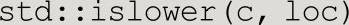
函数会返回一个bool值。
如果c是localeloc中的小写字母,以下表达式会返回对应的大写字母:

若c不是小写字母,则第一个参数会原封不动地返回。

上述表达式等同于以下表达式:

此表达式调用ctype<char>刻面的成员is()函数,用以判断字符c是否符合第一个参数传来的位掩码所指定的字符属性。位掩码实值定义于ctype_base内。
这些字符分类全局函数和“同名但只有一个参数”的C函数相对应。这些定义于<cctype>和<type.h>的C函数总是采用当前的全局locale,用法简单直接。(https://www.daowen.com)

若使用上述辅助函数,在同一个程序内使用不同的locale,则将无法运用使用者自定义的ctype刻面。
如果考虑字符转换效率,应尽力避免使用C++函数,而应从locale中获取对应的刻面对象,然后直接使用该对象的成员函数。很多字符需要根据同一个locale进行分类。函数is()可用于判断典型字符的掩码。函数对[beg,end]区间内的每个字符确定一个掩码,用以描述该字符的属性。这些掩码被存储在vec中,其位置对应于字符位置。快速搜寻时,可使用向量vector。
4.字符编码转换
codecvt刻面用于在字符内部编码和外部编码之间进行转换。例如,只要某个C++标准程序库实例版本支持相应的刻面,即可使用codecvt在Unicode编码和EUC(extended UNIX Code)编码之间进行转换。
该刻面在类basic_filebuf中被用于在“内部表述”和“文件表述”之间进行转换。类basic_filebuf<charT,traits>使用codecvt<charT,char,typename traits::state_type>的具体实例对象来完成此项任务:所使用的刻面是从储存于basic_filebuf的locale中抽取出来的。这是codecvt的主要用途——刻面很少直接使用。
为了理解codecvt,读者应该明白字符编码有两种方案:一种是对每个字符以固定个数的字节表示;另一种是对每个字符以不同个数的字节表示。
多字节表示法为了使字符的空间储存率更高,使用了所谓的转换状态。只有当前位置的转换状态正确,才可能正确翻译字节的含义。只有遍历整个多字节字符序列之后,才能正确理解其含义。
codecvt刻面包含3个函数:
1)字符型别internT用于指定内部表述方式。
2)型别externT用于指定外部表达方式。
3)型别stateT表示转换过程中的中间状态。
中间状态可能由不完全的宽字符或当前的转换状态组成。C++标准程序库对于该state对象中具体存储什么东西没有强制要求。
内部表述始终采用“每个字符的字节个数固定”的表述方案。在大部分情况下,程序使用的是char和wchar_t两个型别。对于外部表述,程序可能使用固定的字节表示法,也可能使用多字节表示法。若采用后者,第二个模板参数用于表示多字节表示法。若采用后者,第二个模板参数会用于表示多字节编码中的基本单位的型别,即每个多字节字符均存放在一个或多个该型对象中。
第三个模板参数用于表示当前转换状态,某些时候会显示出其必要性。处理单个字符时,可能会因“源端缓冲区”已空或“目的端缓冲区”已满而导致多字节字符的处理中断。若出现这种情况,则可将当前状态储存于该型对象中。
和其他刻面相同,C++标准仅仅强制要求支持少数转换。C++标准程序库仅支持以下两个具体实例化对象:
1)codecvt<char,char,mbstate_t>。该实例化对象将native字符集转换为其自身。
2)codecvt<wchar_t,char,mbstate_t>。该实例化对象在native窄字符集中与native字符集之间进行转换。
C++标准程序库没有指定第二个转换的确切语意。自然的做法是在wchar_t转换为char时,每个wchar_t可以切割为sizeof(wchar_t)个char对象。反向转换时,可将sizeof(wchar_t)个chars组装成一个wchar_t。转换动作与ctype刻面的成员函数widen()和narrow()很不相同:codecvt函数使用多个单字节字符构成一个宽字符(wchar_t);ctype函数则是将某种编码下的某个字符转换为另一种编码下的对应字符。
和ctype facet一样,codecvt同样派生一个基类codecvt_base,该基类中也定义了一个枚举型别result,其枚举值用于指定codecvt成员函数的结果,其确切意义视具体的成员函数而定。
in()函数将一个外部表述转换为内部表述。参数s是一个reference,指向stateT。这个“代表转移状态”的参数在转换开始时派上用场;结束时,最后一个转移状态也记录于其中。若待转换的输入缓冲区不是第一个被转换的缓冲区,则传入的转移状态可能和初始状态有所不同。参数fb和fe的型别都是const internT∗,分别代表输入缓冲区的起点和终点。参数tb和te的型别是externT∗,分别代表输出缓冲区的起点和终点。参数fn和tn分别用于表示输入和输出缓冲区中经过转换的序列的终点。函数返回型别是codecvt_base::result。co-decvt刻面的成员函数见表12-32。
表12-32 codecvt刻面的成员函数

转换函数的返回值见表12-33。
表12-33 转换函数的返回值

返回值ok表示函数已取得部分进展。若保持fn==fe,则代表整个输入缓冲区均被处理,并且tb和tn间的序列内含转换结果,其中的字符表示输入序列中的字符,并有一个上次转换留下的结束字符。若in()函数的参数s不是初始状态,则其中储存上次转换未完成的那个“局部字符”。
返回值partial包含两层含义:其一表示输入缓冲区中的内容尚未耗尽之前输出缓冲区已经满溢;其二表示字符处理完毕之前输入缓冲区的内容已经耗尽。此时,tb和tn之间的序列包含所有转换完毕的字符,但输入缓冲区的尾端有一个尚未被完全转换的“部分字符”。下次转换时,为正确表达转换这个“部分字符”,需要一些信息,该信息储存在转移状态s中。若fe!=fn,则输入缓冲区尚未清空,必定存在te==tn,即输出缓冲区满溢。下次转换会从fn开始。
返回值noconv用于只是一个特殊情况:若外部表述转换为内部表述,则无需进行任何转换。此时fn和fb相同,tn和tb相同。目标序列中不包含任何东西,输入缓冲区的内容已经足够使用。
返回值error意味着遇到不可转换的字符。“标的字符集”中没有合适的表述可以对应字符,输入序列结束时的转移状态是非法的。C++标准没有进一步规划任何函数而调查错误原因。
函数out()和in()是相似的,只有其转换方向相反,即内部表述转化为外部表述。参数和返回值的意义和in()同样,参数型别调换之后,tb和te是internT∗,fb和fe是const ex-ternT∗。同样的情况也发生在fn和tn上。
当前的转换状态被当作unshift()函数的参数s,该函数会安插必要的字符以形成一个序列。这通常意味着转换状态被转换为移动状态,即外部表述到达尾部。参数tb和tf的型别均是externT∗,tn的型别是externT&∗。tb和te之间的序列是输出缓冲区,其中存储着转换之后的字符。成果序列的终点储存于tn之中。unshift()函数的返回值见表12-34。
表12-34 unshift()的返回值

encoding()函数返回外部表述的编码信息。若返回-1,则转换动作将由状态决定。若返回0,则产生内部字符所需的externTs数量不是常数。若返回-1和0之外的其他数值,该值表示生成内部字符所需的externTs数量。该信息可用于粗略判断缓冲区的大小。
若函数in()和out()永远不能进行转换,则always_noconv()函数返回true。
length()函数返回“生成max个内部字符”所需的必要的externTs个数。若fb~fe序列中完整的internT字符数目少于max,此函数会返回“能够产生序列内最多internTs”的ex-ternTs的数量。