一个移动阅读行为数据的观察
数字鸿沟在移动阅读行为中是如何体现的?它会产生怎样的社会影响?是否有可能造成社会阶层的再生产过程?即:社会阶层影响了人的注意力流动,注意力的流动反过来又会加固个体所在社会阶层。这些都是亟待回答的问题。虽然“信息茧房”可能导致的在政治领域的受众群体极化(Group Polarization)等可怕的现象还没有明显的迹象,但娱乐化的媒介消费带来的社会阶层的固化已经不容小觑,这一发现为研究社会分层和阶层固化等问题提供了一定意义上的洞见与启发。
大多数针对受众的媒介消费行为的研究都集中在像人口统计或个体偏好这样的个人属性上,许多研究这样做并不是因为这些因素比研究媒体环境的功能(即确定新闻消费行为的结构和功能)更重要,而是因为它们容易被测量。传统的研究方法主要是通过调查问卷的形式,然而,这样的媒介接触的测量方式往往会存在许多关于自我报告(self-reported)数据多可靠性和有效性的问题。
我们以一款主流的移动阅读APP后台服务器所记录的用户行为数据为经验材料进行实证分析,该数据记录了约16万用户在2016年10月1日至2016年12月20日期间的所有行为记录,时间上精确到秒级别,阅读书目近29万本。通过对海量的行为数据进行挖掘,从而对受众的碎片化这一问题建立更为清晰的认识,并试图从更微观的角度,对个体碎片化阅读行为进行精细化的描述。
数据共包含了三部分用户行为,分别是阅读行为、购买行为和使用兑换券的行为。为了方便研究,首先对用户的阅读行为数据进行预处理,将用户的阅读行为数据按照用户id进行分组合并,从而获取每个用户阅读书目的序列及每次阅读同一本书持续的总时长。在整个82天的统计数据中,平均每个人读了38本书,大约平均两天一本书(包括网络文学),此外,每个人阅读数量的中位数也达到23本,这个阅读频率还是属于一个较高的水平。从时间上来看,平均每个人阅读了103小时,这些都表明该APP的用户总体上活跃程度较高。不过,从标准差来看,阅读总数和阅读总时长的标准差均大于平均数本身,这说明不同用户之间无论是从活跃度还是阅读数量上都存在着较大的差异,这一点在我们后面的研究中也会有所体现。
从所有的书目来看,阅读时长和阅读人数的人数都呈现很强的“长尾(heavy-tail)”特征,中,左图横坐标表示每本书被所有人阅读的总时长,单位为小时,可以发现,不同的书被阅读的总时长差异极大,被阅读时长最长的书的被阅读了接近100000小时,被阅读最少的书只有1小时左右,不过从概率分布而言,阅读时长角度的书数量较少(概率较低),大量的书被阅读的时长都很短(概率较高)。在中右图呈现的是不同书目被阅读人数的分布,同样可以观测到很强的长尾特征。少量的图书被阅读的人数可以达到10000人以上,属于非常流行的书,而大量的图书被阅读人数都在1人左右,这一方面说明在整个图书市场中,用户都在追逐流行书籍,另一方面也说明,书的数量很多,且小众图书的兴趣偏好也越来越多地被人们挖掘出来。
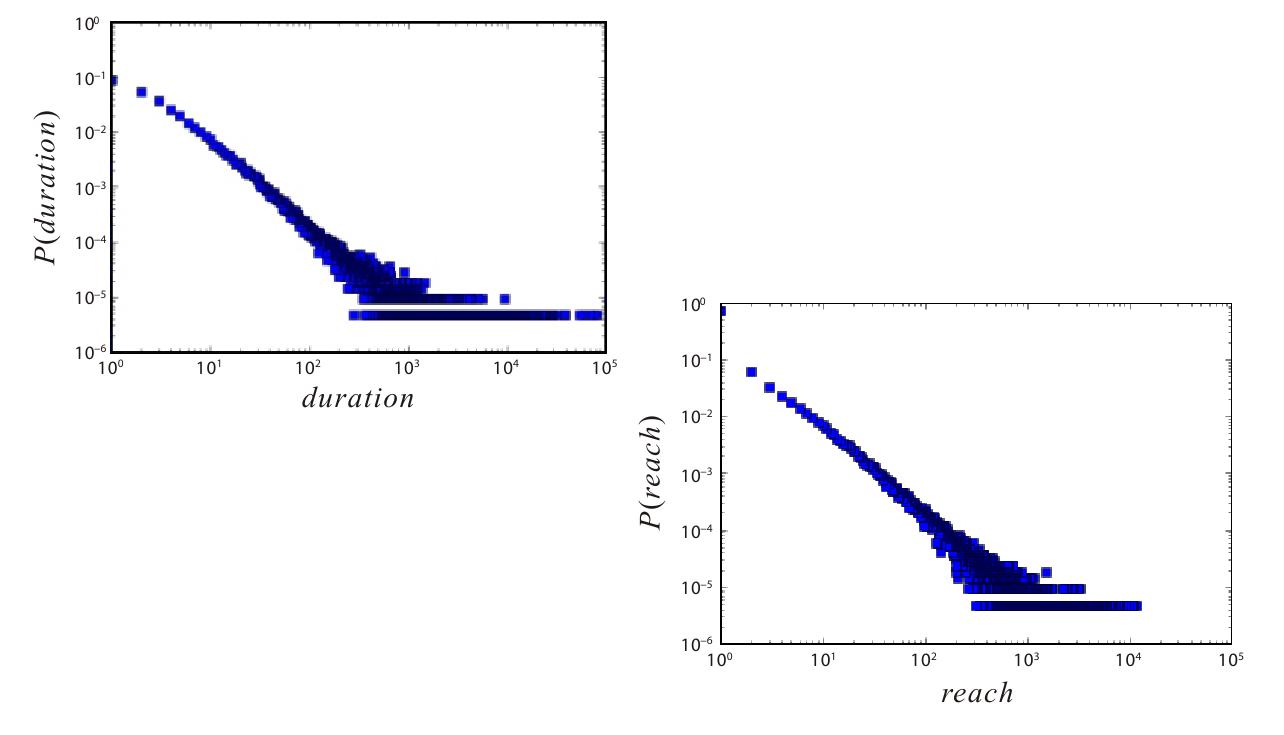
图6-2 每本书的阅读总时长和阅读总人数分布
从购买和使用兑换券的行为来看,有购买行为的用户数量为3.68万,占所有用户的不到25%,说明购买行为在当前的移动阅读APP中尚不普遍。平均而言,每个人会花7.47元用来付费阅读,不过实际上付费的中位数只有3元,标准差更是达到了18.87,说明在购买行为上不同人群的消费也存在着巨大差异。相比之下,使用兑换券的人数近13万人,占总体的80%左右,说明使用兑换券的行为较为普遍,且平均数与中位数相近,都在10本左右,说明用户一般都较活跃,愿意经常使用兑换券来扩大自己的购书量和阅读量。从付费和使用兑换券的行为来看,付费较多的种类依然是原创男频和原创女频,此外,小说、成功励志、经济管理以及计算机类书也获得了很多付费阅读用户的关注,付费的金额相对较高。付费较少的种类主要有文学艺术和期刊两类书,根据笔者的APP使用经验,可能是因为这两类书往往免费的数量较多。
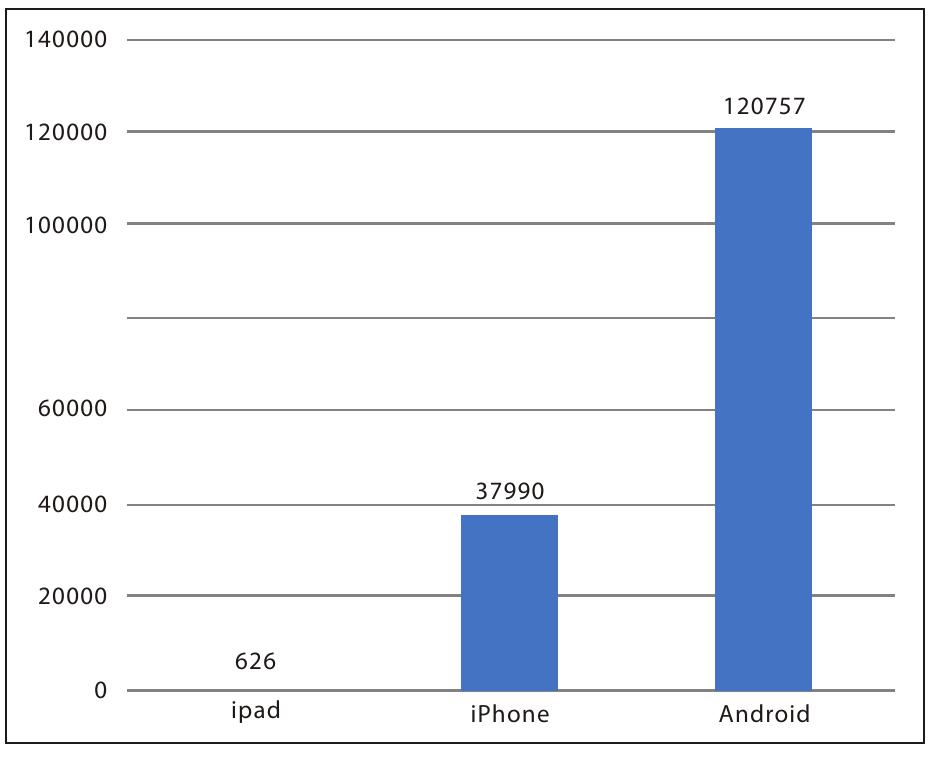
图6-3 各个移动终端的用户数量统计
最后我们关注用户基本信息,在该数据集中只有用户使用的手机终端类型,主要有iPad、iPhone和Android三种,我们将三类平台使用人数作出统计图,如所示。Android用户大约是iOS用户3倍多,是主要的用户人群,iPhone用户人群约占总体的不到1/4,iPad用户极少,只有不到1000个样本。