相似性网络
我们使用的是Uzzi的Z-score方法来构建两个加权的相似性网络。在注意力网络中,我们把用户访问的手机app看作是节点。用样的,在移动网络中,我们把用户所在的地理位置看作是节点。用Z-score来计算网络中任意两个节点之间连接的权重:Z-score=(obs-exp)/σ,obs是观察值,exp是期望值,σ是标准差。
以注意力网络为例(如图7-1和图7-2),将每一个用户浏览过的手机app进行两两组合,再将所有用户的两两组合进行累加,这样我们就得到了观察网络中的权重值。为了得到期望值,我们需要构建随机网络。所以重新回到个人层面,将整个app列表打乱,再将每个人浏览的app两两组合,所有人的组合累加,将这个过程重复10次,就得到了10个随机网络。对10个随机网络中得到的权重值取平均和标准差,就得到了公式中的期望值和标准差。这个公式的目的就是为了得到一个标准化和去偶然性的权重值。标准化是为了便于比较,去偶然性是为了得到更加真实的值。
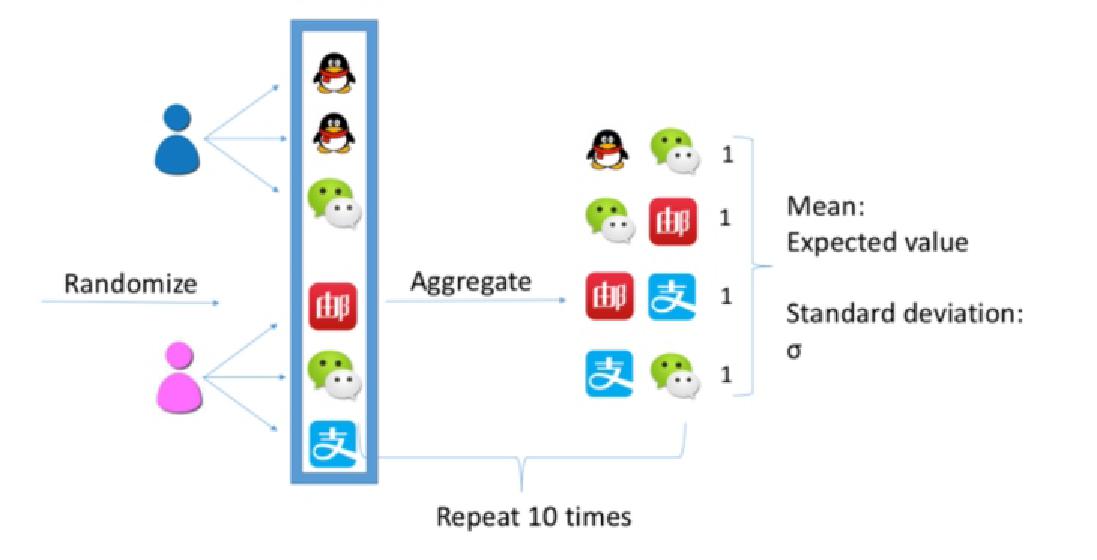
图7-1 观察值
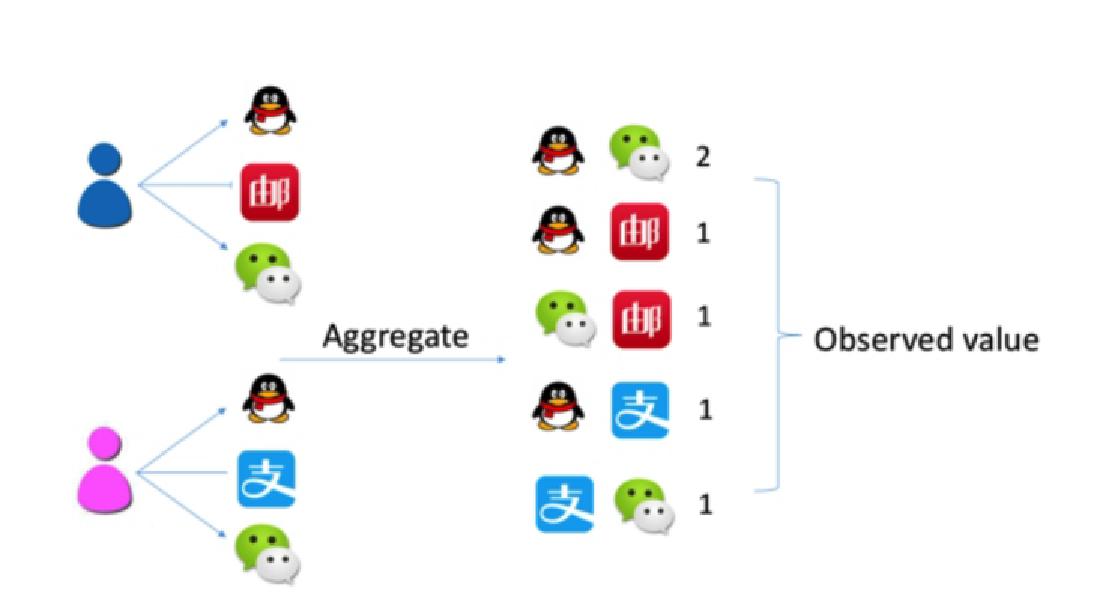
图7-2 期望值
如图7-3证明了Z-score的计算是标准化并去除由于自身因素而带来的偶然性。横坐标ki*kj代表的是注意力网络中任意两个app被访问次数乘积,代表的是app自身的受欢迎程度。在图7-3(A-C)中,无论是观察网络中的权重值,还是随机网络中的权重值和标准差,和ki*kj都是呈线性相关。但在图7-3(D-E)中,当两个权重值相减,再除以标准差,我们会发现线性关系消失了,并且y值不断的趋向于0。
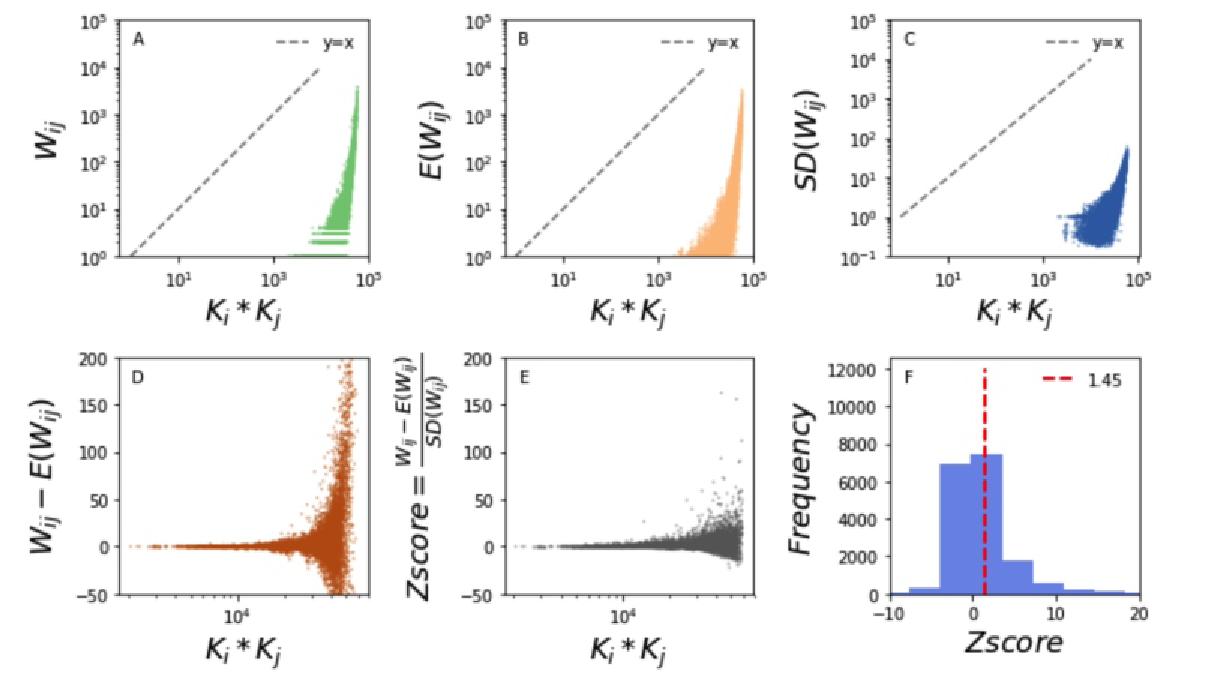
图7-3 z-score计算过程
用样的方法应用于移动网络,也是一样的。
所以我们使用Z-score方法就构建好了两个网络,可以去描绘每个人的轨迹。如图7-4(A)是以一个用户为例,在两个网络中的Z-score累计分布频数图。虚线代表中位数,作为统计量,可以衡量用户的轨迹情况。如图7-4(B)统计了所有用户的中位数,得到了median Z-score的累计分布频数图,同样用虚线标出了median值,将个人的median Z-score和所有用户的median值进行比较。小于median值的,说明用户的轨迹主要停留在不常见的节点组合,相较而言比较创新;大于median值的,说明用户的轨迹主要停留在常见的节点组合,相较而言比较传统。
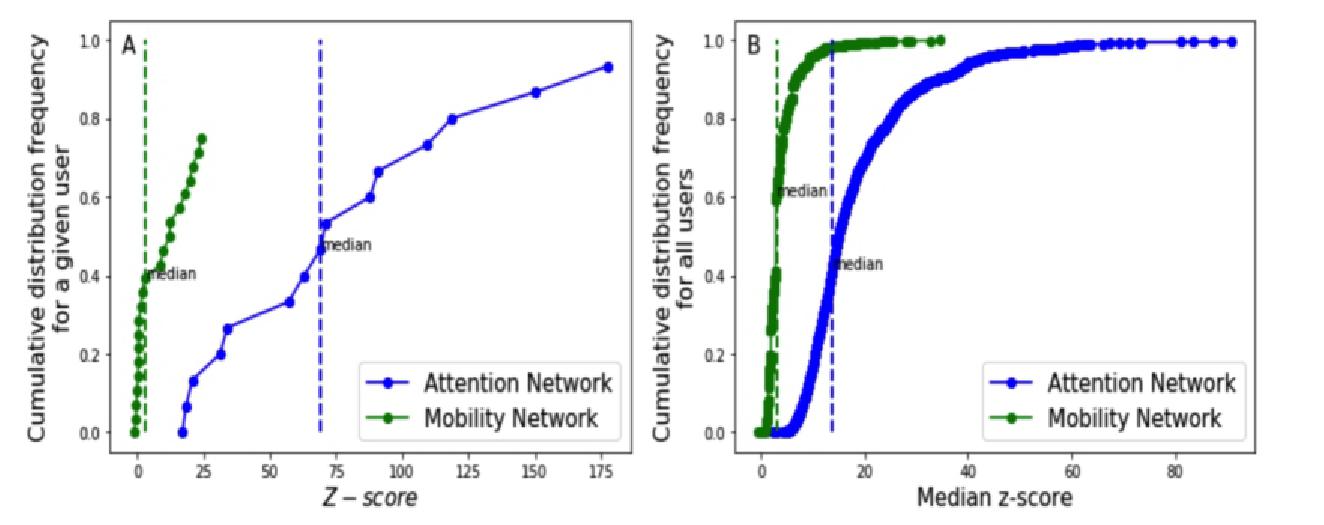
图7-4 用户z-score的累计频数分布图