探究
第4节说明阶层确实会影响用户的移动轨迹,无论是注意力流动还是物理移动上。但这个现象背后的机制是什么呢?有什么更深层次的原因导致阶层影响轨迹,这需要我们进一步探索。
为了进一步探索,我们根据房价、手机终端价格和付费情况选取了前20%和后20%这两类人,这意味着被选择的富人是房价、手机终端价格和付费情况都在前20%的交集,穷人的选择也是一样。严格的定义和选择过程可以帮助我们更准确的观察模式和发现原因。一共有1704个用户被选为富人,1404个用户被选为穷人。图7-7显示了两组人在性别和年龄上的分布。尽管有小部分的用户在性别和年龄的数据上缺失,我们仍然可以观察到这两组人的信息。就性别而言,女性在富人和穷人组中都超过女性,这也符合总样本中男性女性的分布情况。此外,就年龄而言,富人比穷人在25岁到35岁区间有更多比例的人。

图7-7 富人和穷人的性别年龄分布
关于为什么社会阶层会影响轨迹的问题,我们有四个猜想,并且进行了验证。
猜想1:不同社会阶层的人有不同的时刻表,所以他们有不同的轨迹。
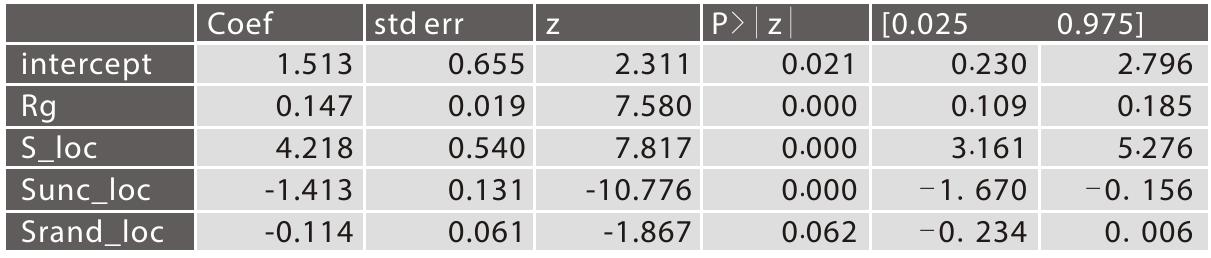
如图7-8的横坐标代表一天的24个小时,各个时段app被触发的平均次数,可以看到,在休息时间晚上8点后到早上8点前,富人使用手机频次明显比穷人少,而工作时间段富人则要比穷人多一些。相比之下,富人有更加规律作息习惯。
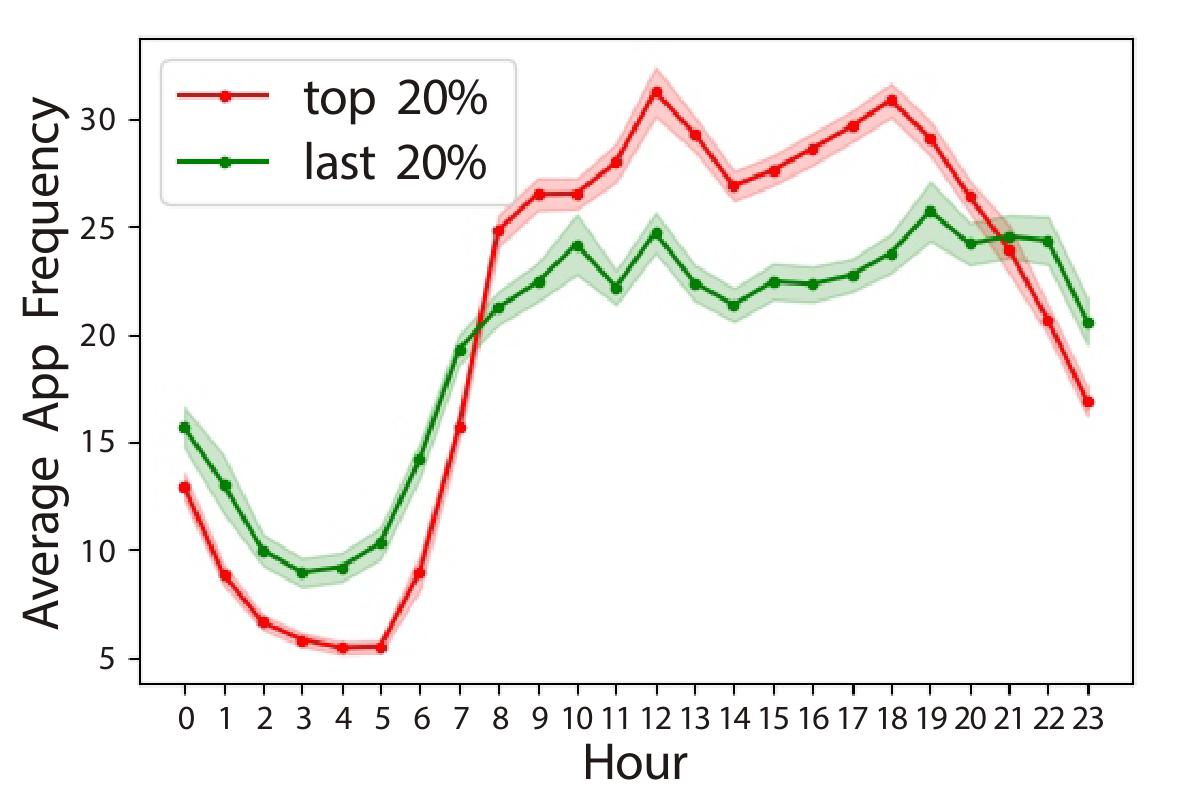
图7-8 富人和穷人在24小时中触发app的平均次数比较
猜想2:不同社会阶层的人有不同的生活方式,所以有不同的轨迹。我们使用每一类的app来衡量生活方式的一个部分。
如图7-9代表在一天不同时间段使用各类app的情况。图7-9(A-C)代表视频、游戏和音乐一类的娱乐化app,穷人在视频类app的使用上比富人频次高,而富人更经常听音乐。说明无论是穷人还是富人,都有自己的娱乐方式,但娱乐方式又各有侧重,视频相比于音乐需要更多的注意力。而在游戏这一类中,比起穷人有很少的波动,我们可以发现对于富人来说,当他们上下班和吃午饭的时间游戏触发会达到高峰,因此证明富人有更加规律的日常作息。图7-9(D-E)表示读这种行为,富人更偏向于读新闻资讯类的app,而穷人则要偏向在6点以后的休息时间看一些普通类的app阅读。图7-9(F-G)代表社交沟通,社区论坛,穷人晚上在社交沟通类的app上使用更频繁,但富人在论坛类的app上特别活跃。图7-9(H-I)是邮箱和导航,穷人很晚还在使用邮箱和导航,我们可以推测他们可能迫于生活经济压力还在工作。所以穷人里面可能有两类人,一类一直活跃在论坛里无所事事,一类人迫于经济压力还在辛苦工作。图7-9(J-L)是网页浏览、搜索和软件工具,穷人在网页浏览,搜索和软件工具的频繁使用也说明他们在注意力网络比富人有更多的探索,符合我们得到的结论,富人在app使用上更大众,更传统。图7-9(M)表示旅游,毫无疑问富人使用更多,他们有更多的意愿和能力去旅游。我们可以看到穷人在图7-9(N-Q)服务类app,购物类app,支付类app和app store类使用更加经常。最后,在图7-9(N-Q)房地产类,这是一个比较小众的类,不管是穷人还是富人都只有少部分人在较少时候用它。总体来看,穷人使用app比富人多,可以说,在娱乐、阅读、沟通、工作这些生活方式上,穷人和富人都有显著差别。

图7-9 富人和穷人在24小时中触发不同类app的平均次数比较
猜想三:不同阶层的人有不同的需求,所以有不同的轨迹。
如图7-10是看两类人在各类app中使用的不同app个数,可以看出富人在沟通类app的使用个数更多,说明富人出于社交或工作需求,需要使用更多不同的app,但富人在沟通类app上使用并没有穷人频繁。这并不矛盾,是广度和深度两个维度的考量,富人在社交类需求更广泛,但使用不够深入。而穷人在导航和软件工具类需求更多。
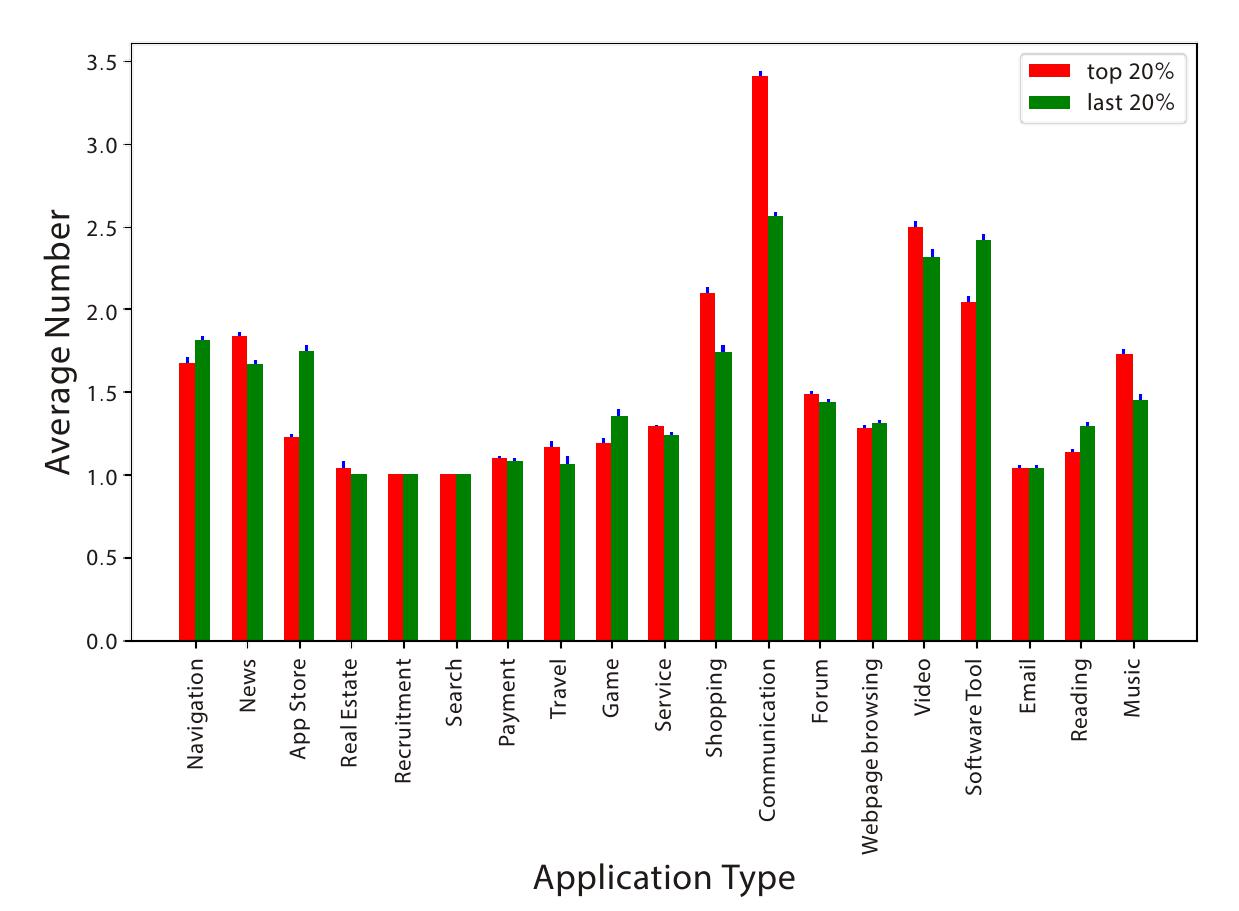
图7-10 富人和穷人使用的各类app个数比较
猜想4:不同社会阶层的人有不同的权限到地理位置,所以有不同的轨迹。
前3个猜想都是基于注意力在app上分配的观察。我们将使用地理移动行为来证明我们的第4个猜想。如图7-11展示了在不同时间点走过的不同地理位置。无论什么时间,富人走过的位置都比穷人多。我们也计算出前20%的更高阶层的人走过52.81个不同的地理位置,后20%的更低阶层的人走过44.18个不同的地理位置(T检验显示两类人有显著的不同,p=0.005)。富人位置变化的多样性表明他们能够有机会访问到更多不同的地理位置。
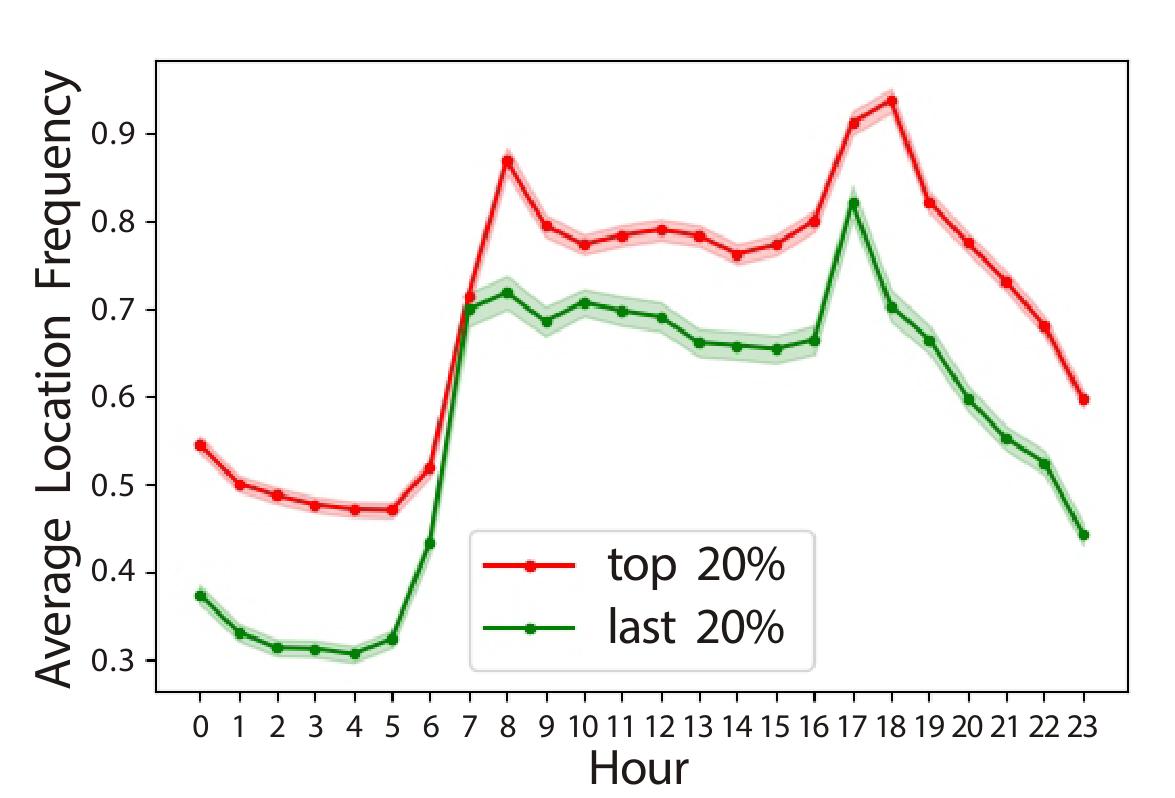
图7-11 富人和穷人在24小时中走过不同地理位置的平均次数比较
我们对选择出来的前20%和后20%的用户计算了四个变量,回转半径,真实熵,随机熵和信息熵(如图7-12)。
在计算移动网络的回转半径中,每一个信号塔通过和它连接的手机使用数量来加权,半径是根据所有加权信号塔的重心来获得。Gonzalez et al.(2008)和Song et al.(2010)在他们的研究中使用回转半径来描述一个人轨迹的典型范围。回转半径rg描述一个人轨迹的典型范围,算式是:

其中,ri代表的是在时间t的位置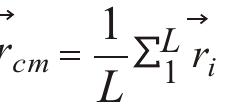 是轨迹的重心,L是个人位置被记录下来的点的总数量。
是轨迹的重心,L是个人位置被记录下来的点的总数量。
我们使用了三种熵来测量每一个用户的移动模式:
(I)随机熵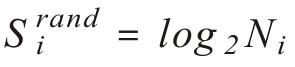 ,其中Ni是用户i走过不同地理位置的数量,假设每一个位置会被以同等可能性走过,从而捕捉到用户位置的可预测性程度;
,其中Ni是用户i走过不同地理位置的数量,假设每一个位置会被以同等可能性走过,从而捕捉到用户位置的可预测性程度;
(ii)时间不相关的熵(信息熵)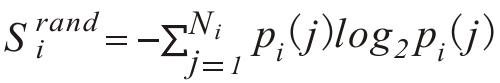 ,其中pi(j)是位置j被用户i访问的历史概率;
,其中pi(j)是位置j被用户i访问的历史概率;
(iii)真实熵,S,这不仅仅取决于访问的频次,同时也考虑了节点被访问的顺序和在每一个位置上所花费的时间,因此可以捕捉到个人移动模式上完全的时空顺序。
真实熵的算式是:

其中P(T′i)是在轨迹组Ti找到一个唯一独特的时间顺序T′i的概率。通常来说,S可以通过式子被估计:
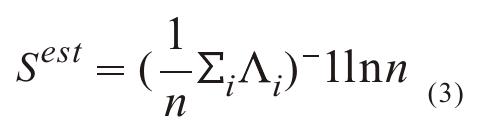
其中,Λi是最短子字符串的长度,从位置i开始,在之前的位置1到i=1都没有出现。这已经被证明,当n接近正无穷的时候,Sect趋近于真实熵。
然后我们构建了一个用户层面的logistic回归模型,结果显示在如表7-1。结果表明,穷人的日常活动范围要比富人大,但是走过地理位置的多样性不及富人。如果考虑上时间因素的话,富人的移动轨迹更有规律性。
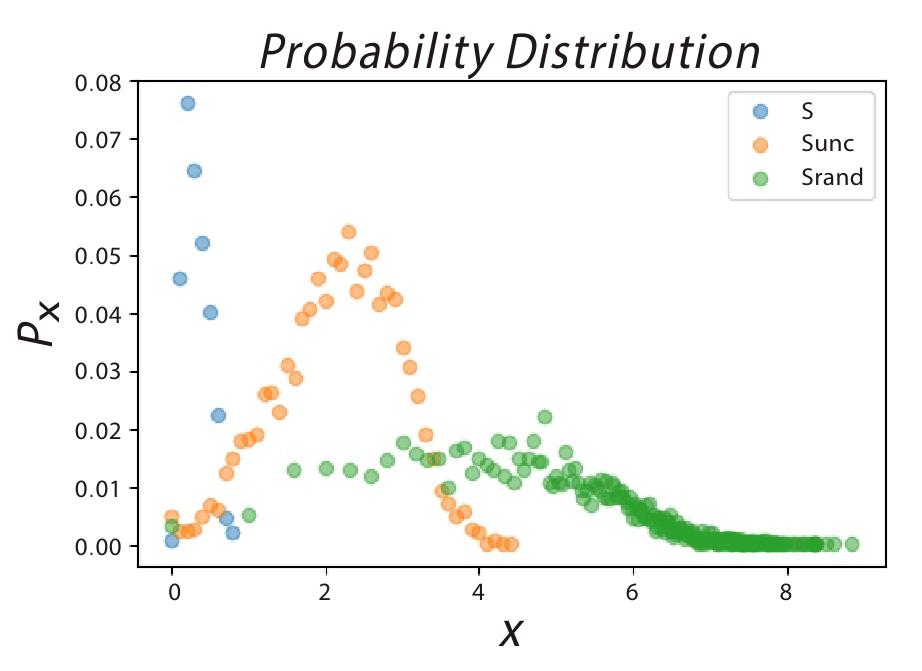
图7-12 真实熵S,随机熵Srand和时间不相关的信息熵Sunc的分布情况
表7-1 预测成为富人的可能性