新闻标题
在这个小节中,我们将介绍Sesen et al.(2019)基于财经新闻讨论的并购套利案例。并购套利是一种成熟的投资策略。简单来说,它是一种在并购公告日建仓的风险策略,然后押注所涉的并购交易会最终完成。根据Jetley/Ji(2010)的分析,虽然随着时间推移,并购策略的获利能力会下降,但即使是基于公开信息,投资者也可以从这种策略上获取相当大的风险溢价。长久以来,像对冲基金这些的机构投资者会使用并购策略,而现在散户投资者也可以通过ETF或者是公募基金投资于并购策略。
当前,就新闻媒体在并购交易中的角色已经有了很好的研究。Liu/McConnell(2013)分析了新闻媒体的报道可能会让有声誉风险的公司放弃进行并购交易,而Ahern/Sosyura(2015)则指出,新闻媒体可能会传播让报纸读者感兴趣的并购谣言,而这些谣言会扭曲股票价格,并且导致价格波动。与之相比,分析新闻资讯流在并购套利中的作用就比较少了。在有关并购交易的文本分析中,Buehlmaier/Zechner(2021)发现,市场对并购新闻的反应存在着不足,需要花费几天的时间才能完成定价。根据新闻内容设计的一个简单并购策略,可以让风险调整收益率增加12%。更进一步,他们发现,如果用财经新闻过滤掉实现概率较低的并购交易,那么并购套利的获利将会显著增加。
Sesen et al.(2019)的分析是通过各种机器学习方法,把并购相关的新闻标题和并购无关的新闻标题区隔开来。这种算法首先对并购新闻进行分类标记,然后从中提取分类模式。最终通过这个“新闻过滤器”(NewsFilter)的模型,推断出其他的新闻标题是属于和并购有关还是无关的分类。这种分析可以帮助投资者及时对并购公告做出反应,筛选出与并购交易相关的股票,并且启动并购套利交易。
作者分析的数据集覆盖了从2017年1月到2017年6月之间总计1.3万条新闻标题。某家大型资管公司的投资经理把这些新闻标题分为和并购套利相关与无关两类。在这个数据集中,总计有31%的新闻标题被标记为“相关”类型,剩下的被标记为“无关”类型。
一般来说,一篇财经新闻常常会涉及多家公司,同时对这些公司的讨论强度各有不同。大多数新闻服务商像瑞文一样,会对特定的新闻报道给出关联性分数,从而可以量化某篇新闻报道对于特定公司主体的报道强度。在并购相关的新闻中,因为所涉及的主体主要就是收购公司和收购目标公司,所以相比于其他类型的财经新闻,其中的实体匹配问题比较小。在Sesen et al.(2019)分析的数据集中,数据服务商已经给出了关联性标签(relevance tags),这样就很容易把并购新闻和相关的公司证券代码联系起来。
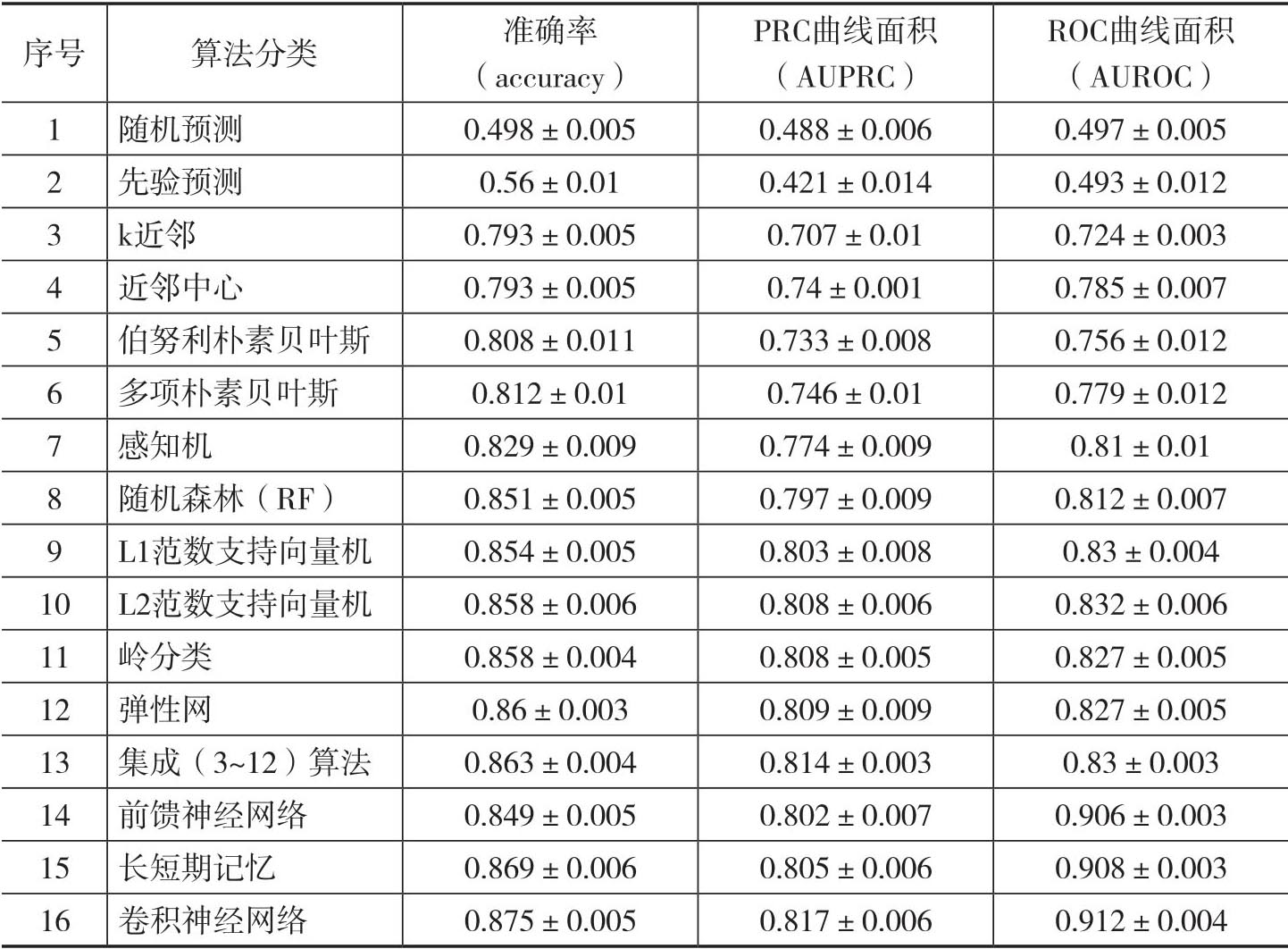
Sesen et al.(2019)将人工标记的并购新闻标题数据集等分成五组,其中每组并购相关和并购无关的频率和总体样本的频率大致相当,也就是并购相关的标题约为69%。对于各种不同基于分类算法,作者在四组样本上进行训练,然后在剩下的一组中进行测试,这个过程将在所有五组中通过迭代的方式来进行,因此就进行了五次交叉验证(cross-validation)。最后,所有的预测模型都将根据以下三个指标来评估绩效:
(1)准确率(accuracy);
(2)精确-召回曲线(precision-call curve/PRC)下方的面积(AUPRC);
(3)接收者操作特征曲线(receiver operation characteristic/ROC)下方的面积(AUROC)。[17]
表1.6报告了各种二元分类算法的预测绩效。第1行和第2行给出了“随机预测”(random predictor)和“先验预测”(prior predictor)这两个基准分类器的结果。顾名思义,随机预测就是说随机分配一半的新闻标题为并购相关,然后剩下的一半标题分类为并购无关。先验预测与随机预测相似,只不过此时我们将样本按照某个先验分类而不是等概率的方式进行随机分配。从直觉上看,这两个分类器效果不会太好,而绩效指标结果支持了这个直觉判断。
第3行和第4行给出了k近邻(k-Nearest Neighbors/k-NN)和近邻中心(Nearest Centroid)这两种近邻算法的分类绩效。结果表明它们的分类效果也很一般。不过一个有趣的结果是,虽然两者的平均准确率几乎相同,但是AUPRC和AUROC表明近邻中心的算法在分类效果上更好。
第5行和第6行给出了两种朴素贝叶斯(Naïve Bayes/NB)方法的结果,即伯努利朴素贝叶斯(Bernouli NB)和多项朴素贝叶斯(Multinomial NB)。多项朴素贝叶斯通常要求在文档术语(document-term matrix)中采用整数型单词计数的方式,不过在实际应用中,类似词频-逆文频(TF-IDF)这样的比率型计数方式也很常用。[18]与多项方法相比,伯努利方法具有二进制特征,这样词频-逆文频就会退化为0和1。表1.6的结果表明,虽然多项分类器具有更复杂的结构,但是它的分类绩效并没有比二项分类器好很多。
第7行到第12行报告了其他各种常用分类算法的结果,这些分类算法包括感知机(perceptron)、随机森林(random forest)、具有不同正则化惩罚的支持向量机(supporting vector machine/SVM)、岭分类(ridge classifier)以及弹性网(elastic net),它们可以归为传统但是相对复杂分类算法。结果表明它们在对新闻标题进行分类方面表现得不错。
第13行报告了把第3行到第12行的分类器进行集成(ensemble)的分类效果。正如其名称所示,集成分类算法得到的结果要好于所有成分算法,当然从绩效指标上看,它只是略微强于弹性网这种在前面12种算法中最优算法产生的分类效果。
近些年飞速发展的以神经网络为代表的人工智能和深度学习技术也开始应用到文本分析中。[19]表1.6的最后三行给出了前馈神经网络(feedforward neural network/FNN)、长短期记忆(long short-term memory/LSTM)和卷积神经网络(convolutional neural network/CNN)三种方法的分类效果。[20]从中可以看到前馈神经网络的预测绩效要好于感知机。因为神经网络模型拥有更多的隐藏层,所以就比感知机拥有更强的表征能力,所以这个结果并不意外。如果把三种不同的神经网络算法进行比较,显然后面两种更为复杂的神经网络方法分类效果更好,虽然增加的绩效比较有限。[21]
表1.6 NewsFilter样本数据集的五倍交叉验证预测性能结果