手机位置数据
我们在第一章第四小节中看到了手机位置数据在量化投资中的应用,下面将介绍一个类似的数据集在股票主观投资中的应用:预测公司业绩。这个例子改编自Denev/Amen(2020)。
这个案例使用的是Thasos的数据集。手机上的应用程序,无论是导航、天气预报还是和朋友家人的通信,都会根据经纬度坐标来记录手机位置。通常这种位置记录是被动式的,也就是说我们无需进行手机操作来完成这种定位。Thasos就是收集并且整理手机位置数据的服务商。Thasos通过把人工智能模型和地理围栏技术结合起来,从而将原始的手机位置坐标转换为有价值的信息。这里地理围栏就是通过在商场和停车场周围绘制边界框或者多边形,然后将顶点转换为经纬度坐标创建的。通过寻找手机和地理围栏坐标的交叉点,Thasos就确定了针对商场或者特定区域的到访次数。这样的访问信息,再结合其他方面的数据,就可以度量很多经济活动,包括进入大型购物中心的顾客数量以及在制造生产车间上的工作时间。
Denev/Amen(2020)使用Thasos的手机定位数据,分析了美国零售商场和餐厅的顾客访问量对于公司盈余的预测含义。他们使用的数据集是2016年到2018年的日数据,同时覆盖了麦当劳和沃尔玛等知名企业。表2.3给出了这个案例中涉及的美国零售商基本信息。
表2.3 美国零售企业信息
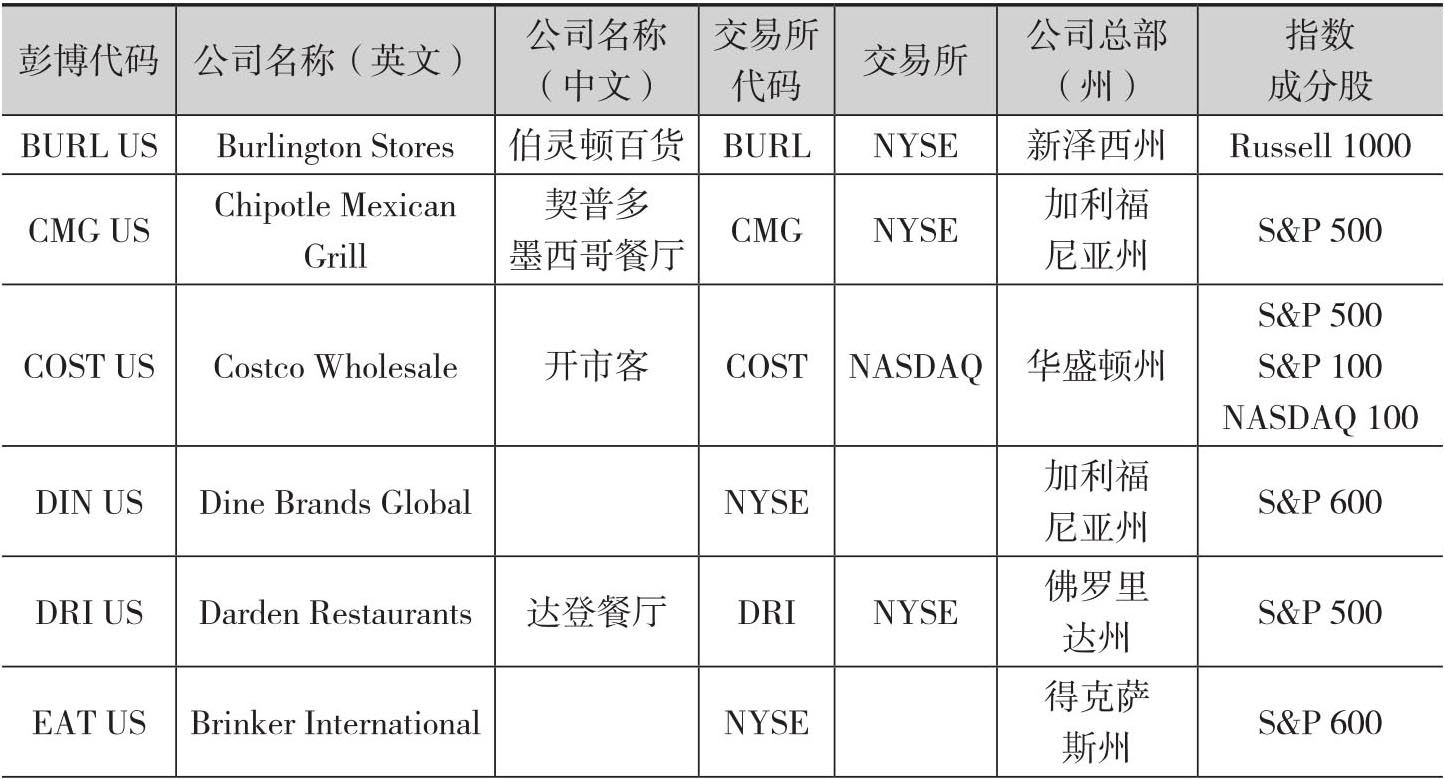
续表
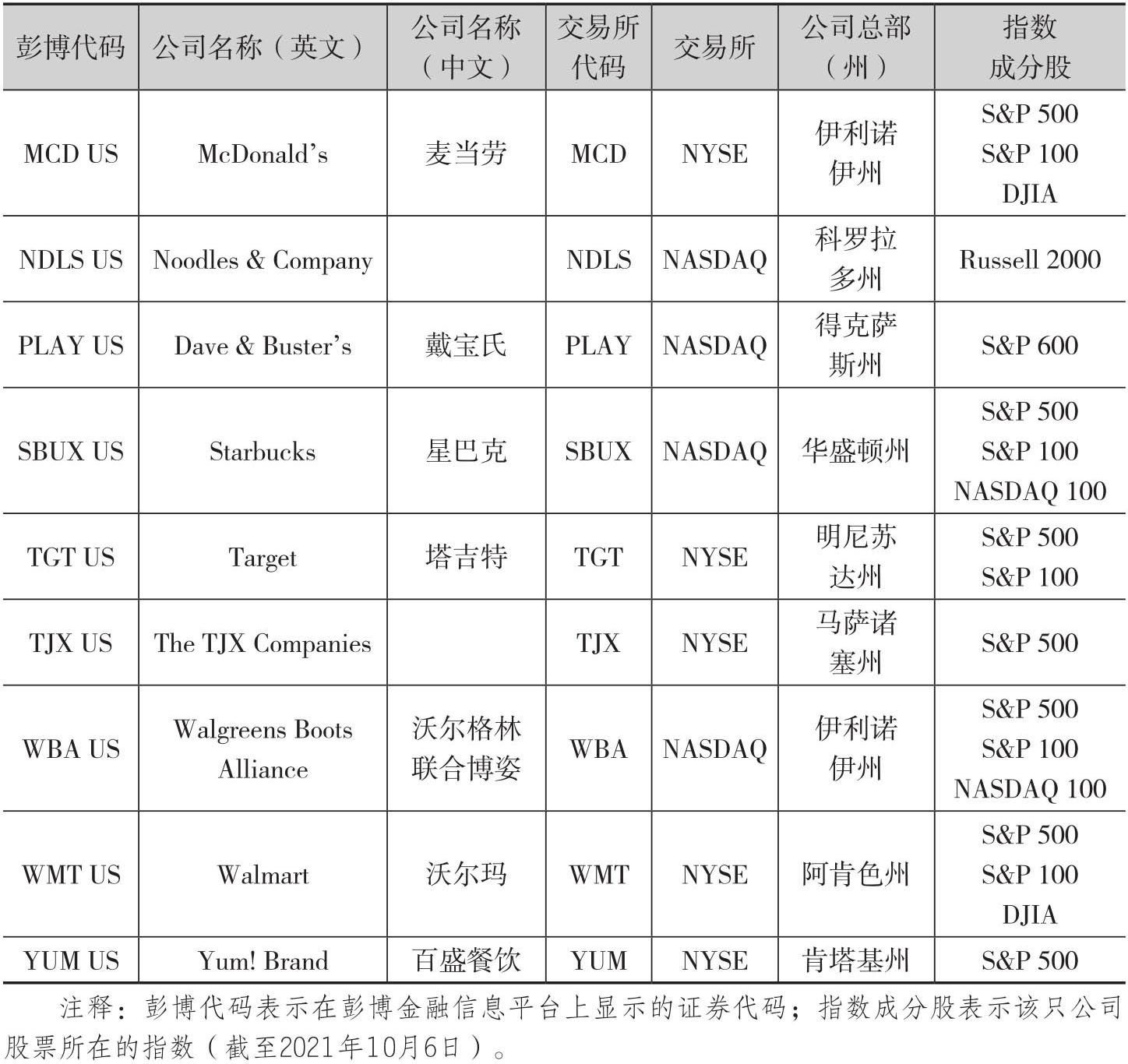
表2.3中的所有公司都有公布季报。这样Denev/Amen(2020)就基于Thasos数据集构建了一个客流分数(footfall score),后者是公司季报所对应时段的日观测值季度平均。考虑到各家公司季末的时点各不相同,所以需要对原始的Thasos数据进行标准化处理以消除其中可能存在的偏误。另外,Thasos的数据集获取的资料只是商场顾客的一小部分,因此还需要对原始数据进行更进一步的预处理,以消除在年龄或者收入等方面的偏误。
图2.6针对沃尔玛公司对比了客流分数、公司发布的每股盈余以及市场对公司盈余的共识三者之间的关系。从中可以看出客流分数和市场共识以及真实的盈余是高度相关的,相关系数分别达到了85%和98%。因此对于沃尔玛公司来说,基于手机位置的客流量对于估计公司每股盈余而言是有用的。
图2.6 沃尔玛的客流量和公司盈余
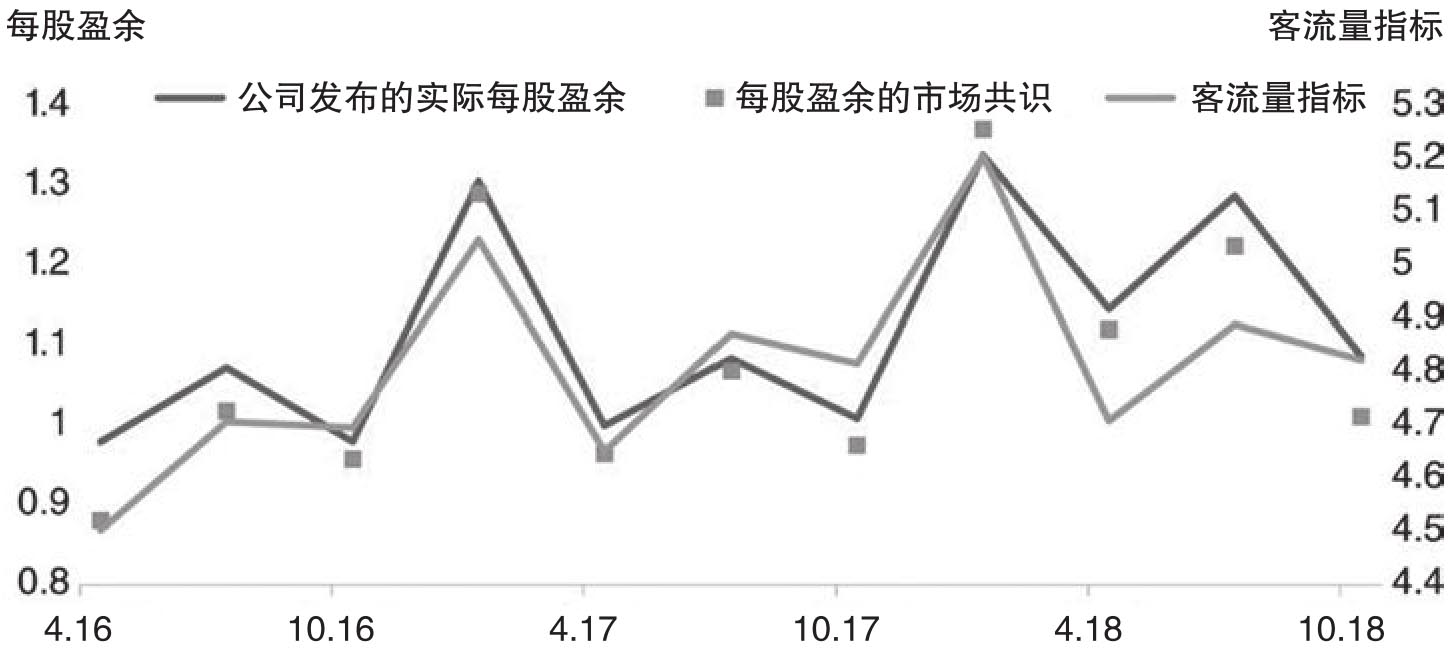
资料来源:Denev/Amen(2020)。
接下来,仿照卫星图像数据在欧洲零售商的应用案例,Denev/Amen(2020)就针对表2.3中的每个美国零售公司做了三个以真实每股盈余为自变量的回归。这三个回归的解释变量分别是针对公司每股盈余的市场共识、基于Thasos得到的客流分数以及这两个变量的组合。图2.7报告了这15家公司在三个回归中得到的调整R2。对于达登餐厅(DRI)这样的公司来说,市场预估显示出很高的调整R2,这就表明市场分析师们在预测公司盈余方面表现很好。就此而言,我们可以认为很多分析师在形成对公司基本面信息预测时使用到了各种另类数据。同时我们会看到,当同时考虑客流指标和市场共识时,前者对于调整R2的影响不大。当然这个故事和前面在基于卫星图像的车辆计数案例中看到的一样,市场分析师们很大可能会在公司财报正式发布之前较短时间内更新预判,而基于手机定位得到的客流量基本上在公司季报对应的季末就可以得到,而这要比正式发布财报要领先很多时日。
图2.7 每股盈余相对于市场共识和客流量的回归
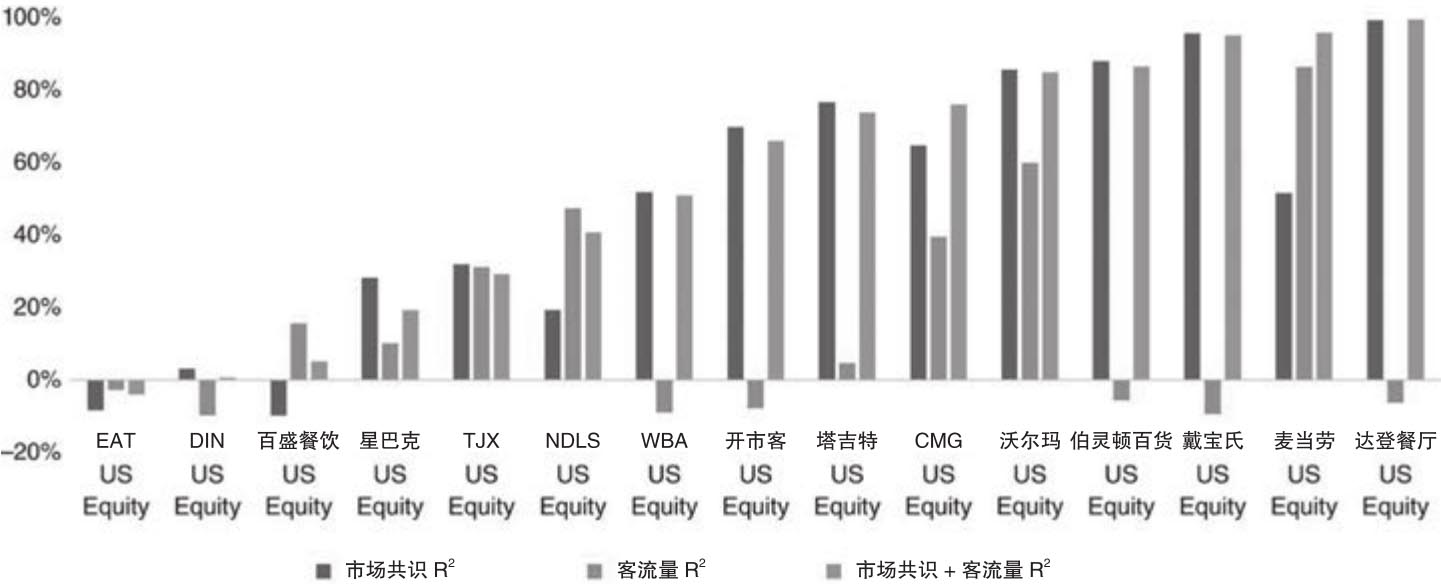
资料来源:Denev/Amen(2020)。
最后,Denev/Amen(2020)把手机位置这种另类数据和其他两种文本数据结合起来进行了分析。第一个文本数据源是在“二、卫星图像数据”案例中看到的,就是彭博社的新闻。以此为基础,通过计算在公司财报的报告期内正面新闻数量和负面新闻数量差额的滚动均值,这样就得到新闻情绪指标。第二个文本数据源是推特的推文,与之类似,计算在报告期内正面推文数量和负面推文数量差额的滚动均值,由此就得到了推文情绪指标。现在以公司报告的每股盈余为自变量,由此针对每个公司就可以进行如下的五个以不同另类数据指标为解释的变量回归:
(1)新闻情绪;
(2)客流指标;
(3)推文情绪;
(4)客流指标和新闻情绪;
(5)客流指标、新闻情绪和推文情绪。
图2.8报告了针对表2.3中所有公司的上述五组回归调整R2。从中可以看出,对于沃尔玛(WMT)和麦当劳(MCD)等公司来说,回归的调整R2表明公司发布的每股盈余和客流指标之间存在着很强的关系,而且在回归中增加新闻情绪和推文情绪指标并不能增进调整R2的数值。同时对于有些公司而言,使用不同的另类数据得到的调整R2并不显著。
图2.8 每股盈余相对于客流量、新闻情绪和推文情绪的回归
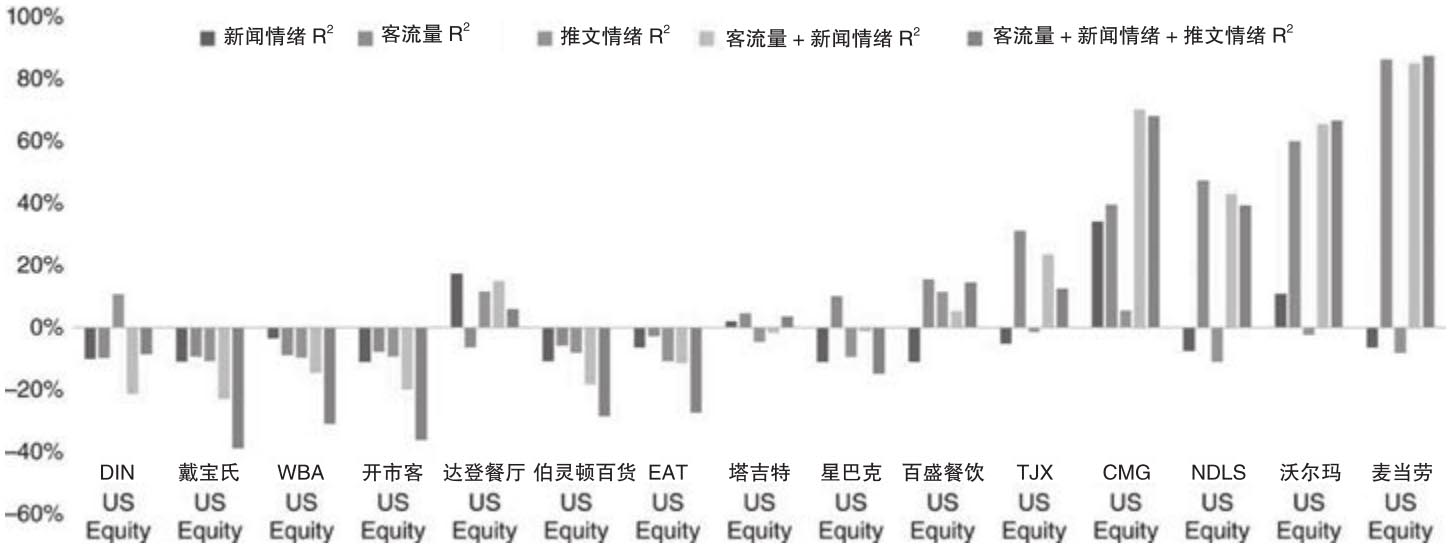
资料来源:Denev/Amen(2020)。
当然,如果我们要从这些观测值中构建一个可交易的投资策略,那么我们就不能进行全样本的回归,而是需要使用滚动回归的方式来估计模型系数。另外,如果要给每股盈余构建模型,更好的做法是使用另类数据来扩充传统的模型,而不是单独使用不同种类的另类数据。