七、商业洞察数据
在本章的最后,我们介绍两个基于商业洞察(business insight)数据的用例,它们改编自Eagle Alpha(2018)。[60]第一个用例使用的商业洞察数据集包括美国上市公司每月的应收账款信息,除了应收账款金额,还包括预期的商业信用金额数据。考虑到商业信用在公司融资中大致占有四分之一的比例,所以这些数据可以对公司的经营绩效和前景提供有价值的判断。不能给上游供应商支付货款就是公司存在不良绩效的信号,因为无法付款则意味着未来和商业伙伴再进行交易就存在着困难。
Hirshleifer et al.(2020)研究了公司商业信用相对公司资产的比例、逾期商业信用金额以及股价表现之间的关系。结果表明商业信用高并且能够按时还清信用余额的公司在短期内股价表现良好。在这项研究中,作者分析了超过5700家有商业信用的上市公司在2001年到2017年之间的数据。每个月,所有公司根据商业信用相对于公司资产的比率分成五分位组,同时根据逾期商业信用占比分成高、中、低三组,接下来观察每家公司随后一个月的股价表现。
他们的分析表明,买入商业信用相对于公司资产最高分位组的股票组合,同时做空最低分位组的股票组合,然后进行月度再平衡,就可以在年化基础上比基准收益高出6%~7%。买入商业信用余额较高同时逾期余额较低的公司,同时做空商业余额较高但是逾期余额较高的公司,这样的多空组合可以获得略微更高的绩效,它可以比基准收益在年化水平上高出6.2%~7.3%。对于逾期信用金额较少的公司而言,还款的时间线对于公司股价绩效来说在统计上不是重要的影响因素。做多逾期余额高的公司,同时做空逾期余额少的公司,只能比市场基准高出3%~4%。
Eagle Alpha(2018)中第二个用例中的另类数据集包括了以下三类数据:
(1)公司的商业信用金额以及逾期金额数量;
(2)用户的点击模式(click patter);
(3)信用评分(credit score)。
公司的商业信用数据并没有直接进入到投资分析,而是商业信用的提供者作为这个数据集的使用者或者贡献者会针对某个特定公司提出问题,或者对公司进行研究。这个用户的点击模式就考虑了这个数据集中有关商业信用数据的用户对公司询问的次数以及研究的深度,据此数据集所涉公司每个月就得到了一个点击模式评分。而这个数据服务商同时也自创了一套信用评分体系,用来评估每家公司在未来12个月内破产的可能性。
这个用例分析了公司的点击模式评分、公司信用评分以及公司股价三者从2001年到2017年之间的关系。首先是按照每月点击模式得分的百分比变化对上市公司划分为五分位,然后在每个五分位组中,再按照信用评分划分为高、中、低三组。这样分组过后,表现最好的股票是点击模式得分较高同时信用得分最低的股票。这个结论看起来和直觉很不相符,不过它表明了人们更为关注的是扩大信贷规模,而不是关注信贷质量。
现在构造一个市场中性组合,其中做多那些点击模式得分升幅很大并且信用评分低的公司股票,同时做空那些点击模式得分涨幅很小以及信用评分低的公司股票,同时每月重新排序并且对股票组合进行再平衡,这样的多空组合得到的投资业绩比市场指数每年会超出12%。需要特别指出的是,在我们根据上述两个指标进行先后排序所形成的分组中,信用评分最低同时点击模式得分增长最小的公司表现是最差的。
[1] 参见https://en.wikipedia.org/wiki/Systematic_trading。
[2] 自主交易不能和所谓的“全委投资管理”(discretionary investment management)的概念相混淆。根据维基百科(https://en.wikipedia.org/wiki/Discretionary_investment_ management)的定义,全委投资管理是指一种专业的投资管理形式,其中代表客户进行各种证券投资。这里的英文“discretionary”为全权委托之意,也就是投资经理更具自己的判断而在委托人的指导下做出投资决策。这种服务的主要目标是超越在投资计划中确定的绩效基准,或者说给客户带来alpha。全委投资管理的服务通常是针对非金融企业、养老金和高净值客户而专门制定的,资产管理公司需要持续确保投资组合符合客户的投资目标和风险水平。
[3] 维基百科(https://en.wikipedia.org/wiki/Systematic_trading)就指出,量化投资是指所有使用量化技术的交易;大多数量化交易会使用量化技术对资产(比如衍生品)进行估值,但交易决策可能是基于系统的方式或者是基于自主的方式。
[4] 需要指出的是,在本书写作的时候,作为一家金融科技公司,iSentium已经在2019年停止运营了。不过在摩根大通后续的研究报告Kolanovic/Smith(2019)中依然列出了这家公司。
[5] 相关的研究包括Bliss et.al(2012)、Dodds/Danforth(2009)、Dodds et al.(2011)、Frank et al.(2013)、Mitchell et al.(2013)等,读者可以参考https://hedonometer.org/papers.html。
[6] 19世纪曾经有一架国际象棋机器The Turk在欧洲巡回比赛,它曾经打败过本·富兰克林和拿破仑·波拿巴等名人。这台机器曾经被誉为是人工智能的创举,不过后来人们发现它根本不是机器,而是一个机械木偶,由藏在棋盘下方的人类象棋高手控制着。后来亚马逊公司运营的众包平台取名为Mturk,用来指称辅助人工智能的人力。
[7] MTurk的网址是www.mturk.com。我们在《另类数据:理论与实践》一书的第七章第四小节中介绍了众包概念。
[8] 相关文献可以参考Bernanke/Kuttner(2005)、Cieslak et al.(2019)以及Lucca/Moench(2015)。
[9] Azar/Lo(2016)把这些情绪分数称为推文的极性分数(polarity score)。
[10] CRSP全称是证券价格研究中心(Center for Research In Security Prices),它附属于芝加哥大学布斯商学院,现在已经公司化运作,公司网站是www.crsp.org。CRSP创建于1960年,是由当时芝加哥大学金融学教授J.Lorie和副教授L.Fischer两人共同创立的。它是美国第一个用于金融证券实证分析的数据库。
[11] 凯利标准也被称为凯利策略(Kelly Strategy)或者是凯利赌局(Kelly Bet),它确定了针对特定赌局的最优理论赌注公式。当赌局的预期收益已知时,这个公式是有效的。凯利赌注可以通过最大化财富对数的期望值来确定,其中最大化财富对数的期望值就等价于最大化几何增长率的期望值。这个公式是由贝尔实验室的John Kelly在1956年发明的。这个方法也被称为科学赌博方法,因为从长期来看,和所有其他策略相比,凯利标准可以得到更多的财富。假定每次赌局只有赢和输两种结果,p表示赢的概率,b表示赔率,这种简单情形下凯利标准确定的最优赌注就是: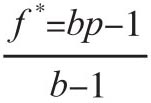
[12] 这里的前瞻性偏误就是在构造日的交易策略时使用了在这个时点尚未知道的推文以及回报率的信息。
[13] 有关TRESS的详细算法读者可以参考TipRanks(2018)。
[14] 有关ESS指标的介绍,读者可以参考瑞文的研究报告Hafez/Xie(2011)。
[15] 需要指出的是,这种构造多空组合的方式和传统方法并不一致。在传统方法中,我们会选取某个指标作为股票的筛选器,也就是按照这个指标对股票样本进行排序,然后基于分位数形成不同的分位组合。按照这个指标和股票回报率的关系同时做多和做空最高和最低分位组合,由此形成多空组合策略。
[16] 这些指标是用来比较各种不同分类器算法的绩效。对于任一二元分类器,分类结果
将出现由22维混淆矩阵(confounding matrix)定义的结果:
(1)TP:预测为真同时事实为真的情况;
(2)FP:预测为真但是事实为假的情况;
(3)FN:预测为假但是事实为真的情况;
(4)TN:预测为假同时事实为假的情况。
根据上述四种情形,我们可以定义如下的指标:
(1)准确率表示样本中分类准确的比率;
(2)精确率表示预测为真的样本中事实为真的比率;
(3)召回率表示事实为真的样本中预测为真的比率;
(4)真阳率(true positive rate/TPR),它等于召回率;
(5)假阳率(false positive rate/FPR)表示事实为假的样本中预测为真的比率。
PRC曲线是以召回率为横轴、精确率为纵轴的曲线,而ROC曲线则是以假阳率为横轴、真阳率为纵轴的曲线。
[17] 词频(term frequencey/TF)表示一个单词/短语在文档中出现的频率;而逆文频(inverse-document frequency/IDF)则表示某个词在不同文档中出现的频率倒数。
[18] 相关的技术读者可以参考Goodfellow et al.(2016)的经典大作《深度学习》。
[19] 长短期记忆是循环神经网络(recurrent neural network/RNN)的特例。
[20] 如同Yin et al.(2017)所示,当前的文献对于循环神经网络和卷积神经网络是否适合于文本分析的任务还存在争议。
[21] 这些要求包括市值不低于5亿美元、日平均交易量达到100万美元以及名义价格不低于4美元。
[22] 这是金融决策中的马赛克理论(Mosaic theory),也就是说为了得到更有价值的分析结论,就必须从各种公开和非公开渠道获取信息。有关这个理论的详细介绍读者可以参考下面的维基百科词条:https://en.wikipedia.org/wiki/Mosaic_theory_(investments)。
[23] 闪崩表示证券价格在很短时间内发生快速、大幅度且不稳定的波动。迷你闪崩次数的数据来自于沃顿研究数据服务(Warton Research Data Source/WRDS)。发生一次迷你闪崩就意味着交易超出了做市商买卖报价价差的范围,此时要么表示买家急于入手,要么表示卖家急于出手。
[24] 索提诺比率(Sortino ratio)是一个类似夏普比率的指标,只不过分母项用下侧偏差(downside deviation)替换了标准差。所谓下侧偏差就是收益低于均值形成的标准差。
[25] SKU就是库存进出计量的基本单元,可以是以件、盒、托盘等为单位。它包含了三个方面的信息:从货品角度看,SKU是指单独一种商品;从业务管理的角度看,SKU还含有货品包装单位的信息;从信息系统和货物编码角度看,SKU只是一个编码。SKU是用来定价和管理库存的,比如一个产品有很多颜色、很多配置,每个颜色和配置的组合都会形成新的产品,这时就产生很多SKU。
[26] 对于序列x而言,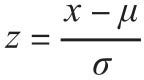 ,其中μ和σ分别表示原始数据序列的均值和标准差,这样z分就把原始序列修正为均值为0、方差为1的序列。
,其中μ和σ分别表示原始数据序列的均值和标准差,这样z分就把原始序列修正为均值为0、方差为1的序列。
[27] 这里的市场预期可以理解为卖方分析师在财报发布前形成的平均预期,外文文献中也会称之为市场共识(consensus)。
[28] 我们在《另类数据:理论与实践》一书第七章中详细介绍了卫星图像数据和地理位置数据。
[29] 有关ExtractAlpha风险模型的介绍读者可以参考Jha(2019c)。
[30] SDK(software development kit)的中文含义是软件开发工具包,一般都是一些软件工程师为特定的软件包、软件框架、硬件平台、操作系统等建立应用软件时的开发工具的集合。
[31] 我们在《另类数据:理论与实践》一书的第七章第三小节中介绍了这个数据集。
[32] Shleifer/Summers(1988)讨论了这种行为。
[33] Guiso et al.收集上市公司网站数据的时间是从2011年6月到10月之间。
[34] 这个指标可以参考文献Fornell et al.(1996)。
[35] 这个数据取自斯坦福证券集体诉讼数据集(Standford Securities Class Action Database)。
[36] 我们在《另类数据:理论与实践》一书的第七章第四小节中介绍了这个数据集。
[37] 按照心理学家Thorndike(1920)的说法,光环效应就是在数据收集过程中从一个判断转向另外一个判断存在遗留(carry-over)时所出现的问题。Guiso et al.(2015)把这种光环效应看作是一个变量误差(error-in-variable)问题,它会影响到问卷调查中的所有回答。现在令x表示赞同诚信这个观点,而z表示赞同调查中的另一个观点。令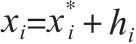 ,其中
,其中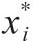 表示真实反应,也就是不会受到问卷调查中其他陈述性问题的影响,同时hi表示光环效应。与之类似有
表示真实反应,也就是不会受到问卷调查中其他陈述性问题的影响,同时hi表示光环效应。与之类似有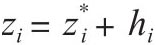 ,同时
,同时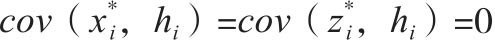 ,因此就和标准的变量误差问题一样,真实值和光环效应不相关。Brown/Perry(1994)和Fryxell/Wang(1994)讨论了公司财务领域的光环效应以及处理方法。
,因此就和标准的变量误差问题一样,真实值和光环效应不相关。Brown/Perry(1994)和Fryxell/Wang(1994)讨论了公司财务领域的光环效应以及处理方法。
[38] 根据Guiso et al.(2015)报告的数据,管理层诚信、托宾Q的截面标准差分别是0.25和1.53,由此可以得出0.23=(0.25×1.417)/1.53,0.47=(0.25×2.880)/1.53。
[39] 如果同时使用“安全场所”和“表现自我”作为控制变量,那么管理层诚信(管理层伦理)的回归系数就变为1.235(1.493),它们都在1%的水平上是显著的。同时因为两个控制变量之间的共线性,所以控制系数就变得不显著了。
[40] 根据Guiso et al.(2015)报告的数据,工会员工率的标准差是0.13。
[41] 优兴(Universum)是一家国际知名的集调查研究与管理咨询于一身的公司。优兴公司每年定期在欧美国家进行毕业生问卷调研,对结果进行严谨分析后得出最佳雇主排名,并在各国权威网站及其他相关媒体上发布该结果,其公司网站是 https://universumglobal.com/。
[42] 我们在《另类数据:理论与创新》一书第七章第一小节中介绍了Glassdoor数据 集。
[43] 20世纪60年代,哈佛大学的Biz Stone、Evan Williams等人开发了一种计算机辅助定量内容分析的软件,这个软件就是一般问询者系统。相关文献可以参考Stone et al.(1966)。
[44] KLD是由P.Kinder、S.Lydenberg和A.Domini在1989年成立的咨询机构,其目的是给美国的机构投资者提供全面、准确并且易于使用的公司社会研究。KLD后来改名为MSCI。自从成立以来,KLD一直为金融市场提供研究产品和服务,它拥有世界上最多的公司社会研究人员。2009年KLD被RiskMetrics收购,然后RiskMetrics又在2010年被明晟(MSCI)收购,所以KLD现在就成为明晟的一部分。KLD会在七个主要定性议题领域提供大约80个指标,这些领域包括共同体(commnuity)、公司治理(corporate governance)、多样性(diversity)、员工关系(employee relations)、环境(environment)、人权(human rights)和产品(products)。同时它还提供涉及争议性商业活动的信息,包括酒精(alchohol)、赌博(gambling)、枪支(firearms)、军事(military)、核能(nuclear power)和烟草(tobacco)。有关KLD的介绍可以参考Sharfman(1996)、RiskMetrics Group(2010)和MSCI(2016)。
[45] Moniz(2019)的这种做法沿用了Waddock/Graves(1997)、Hillman/Keim(2001)、Statman/Glushkov(2009)和Verwijmeren/Derwall(2010)等人的分析。
[46] 账面收益率是上个日历年末的权益账面价值和市值的比率(这里沿用了Fama-French 1992的经典度量);公司规模是上个日历年末的公司市值;价格动量是过去12个月内的股票收益率;分析师更新指标等于过去三个月内分析师预测中位数变化加总处于过去一个月公司股价;销售增长率是过去一年的销售增长率。
[47] 沿用Petersen(2009),作者在这组回归中根据公司对标准误差进行了聚类处理,以校正标准误差中存在的时序相关性。
[48] 沿用Tetlock et al.(2008)的分析,这里要求每家公司具有最近10个季度的盈余数据,同时对于盈余数据少于四年的公司设定盈余趋势为0。
[49] 当前在金融和财务文本中应用词袋方法具体应用包括Loughran/McDonald(2011)和Henry/Leone(2016)基于手工搭建的词汇表,Routledge et al.(2018)使用的文本分类方法,以及Huang et al.(2018)和Lowry et al.(2020)使用的主题建模方法。
[50] 使用有监督学习的文章包括Routledge et al.(2018)对并购的预测以及Erel et al.(2021)讨论的董事长选举问题;而使用无监督学习的文章包括Huang et al.(2018)和Li et al.(LMSY,2021)。
[51] 词频(term frequencey)表示一个单词/短语在文档中出现的频率;而逆文频(inverse-document frequency)则表示某个词在不同文档中出现的频率倒数。
[52] 本书没有给出各种价值观度量指标之间的相关系数,对于感兴趣的读者可以参考LMSY(2021)的表3。
[53] 这里的Delta和Vega指标是由Coles et al.(2006)提出的。
[54] 这里的CEO薪酬久期是由Gopalan et al.(2014)提出的。
[55] 这个指标的计算是通过Jones(1992)模型得到的。具体而言,就是进行如下的行业截面回归: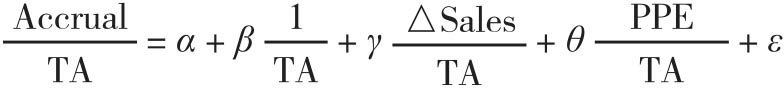
其中“Accrual”表示净收入减去净经营现金流,“TA”表示总资产,“△Sales”表示销售额的年度变化,PPE表示不动产、厂房和设备。操控性应计利润就等于上述回归中得到的残差。
[56] H1B签证是美国签发给在该国从事专业技术类工作的人士的签证,属于非移民签证,是美国最主要的工作签证类别。这种签证必须由雇主出面为申请人申请,且申请人的雇用申请书需要美国劳工部下属的公民及移民服务局的批准。
[57] 注意这里并没有用前90天发布的全部评级次数进行缩减,因为后一个数值可能波动过于剧烈。
[58] 它们分别是Eagle Alpha(2018)中的用例7、用例10和用例37。
[59] 我们在《另类数据:理论与实践》一书第七章第五小节中介绍了谷歌趋势这个衡量互联网搜索流量的指标。
[60] 它们分别是Eagle Alpha(2018)中的用例1和用例2。