一、文本数据
原油等能源类大宗商品在我们日常生活中扮演着重要角色,因为它们为全球大部分的运输系统提供燃料,同时也是工业企业的重要投入要素。它们的价格会根据自身的供需变化而做出反应,同时与经济周期联系密切,而且像国内生产总值、失业率这样的经济变量以及地缘政治或者自然灾害这些变量都会对其产生影响。
在第一章中我们介绍了几个基于瑞文(RavenPack)数据分析股票市场的案例,在本小节中我们将介绍基于这个数据集在能源期货市场上的应用。Brandt/Gao(2019)利用瑞文数据分析了地缘政治和宏观经济事件以及情绪对于原油价格的影响。他们发现宏观基本面的新闻可以在月度时长上具有预测能力,地缘政治事件会对能源期货价格有很大影响,但是短期来看并没有预测性。和Brandt/Gao(2019)不同,瑞文的分析师Hafez/Lautizi(HL,2019)分析了包括原油在内的四种能源类大宗商品,并且通过瑞文提供的事件检测(event detection)功能给这些商品建立预测模型,进而获取投资收益。在这个小节中我们将报告这个案例。
在作者撰写这篇文章的时候,瑞文建立的事件分类已经拓展到超过6800种不同的类型,它们可以让投资者针对不同资产类型和不同商品快速并且精准地确定影响市场的各种事件,比如大宗商品领域中的供给增加、进出口动态、库存变化等。
类似我们在第一章中看到的那样,瑞文通过自然语言处理技术,将传统新闻和社交媒体这样的非结构化数据集转化为可用于量化投资的结构化数据和指标,由此让投资者识别新闻中涉及的经济主体,并且将这些实体和最有可能影响其资产价格的事件联系起来。每个事件都存在三个指标,包括事件的情绪(ESS)、事件的新颖性(用事件相似性天数衡量/ESD)以及事件关联性(ERS)。[1]在分析这些能源商品时,作者在事件新颖性方面只考虑ESD≥1,这样就去除了日内重复性的新闻事件,同时对事件关联性指标不做任何限制。[2]通过对2005年1月到2017年12月之间近13年和大宗商品相关的事件进行分析,在原油上总计找到了103个事件类型;而在平均意义上大宗商品的事件类型只有34个。表4.1给出了四种能源类商品的基本事件信息。
表4.1 四种能源类商品期货基本事件信息(2005.01—2017.12)
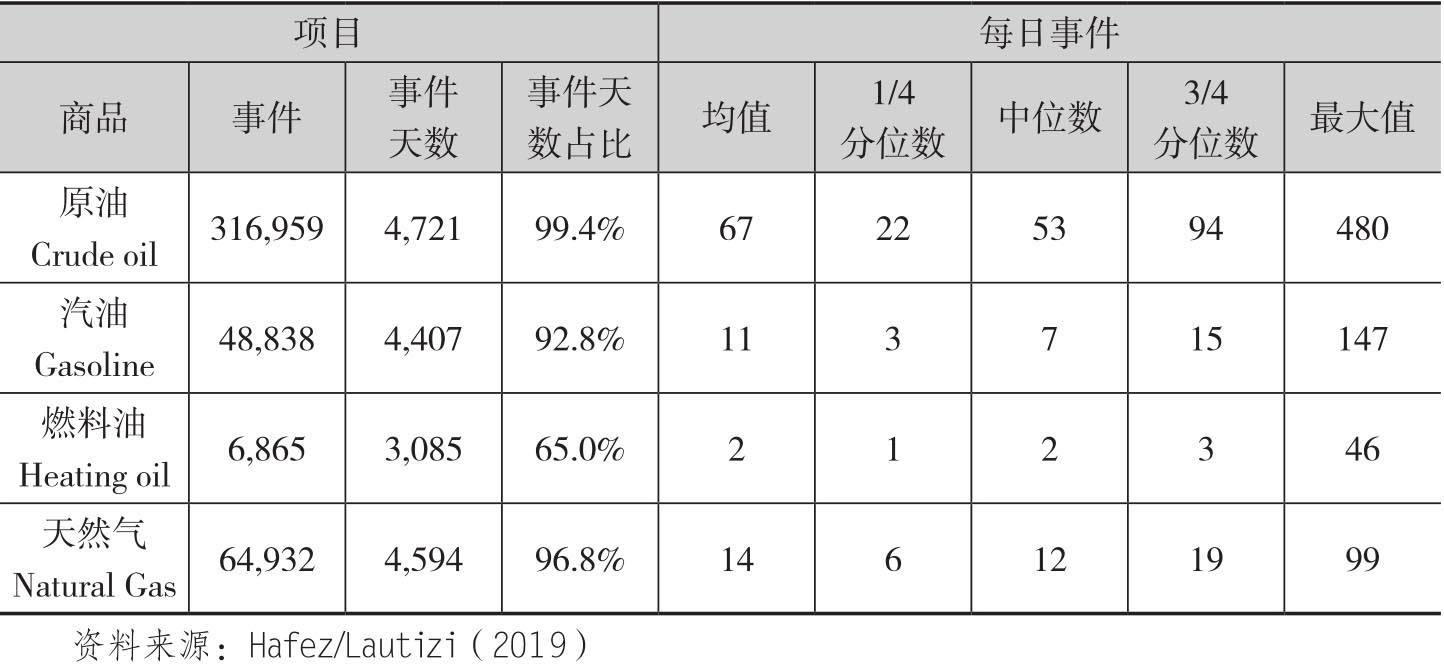
考虑到事件类型的数量过多,这样自变量矩阵的维度就会变得很大,为了解决维度诅咒(curse of dimensionality)的问题,[3]以及事件类别之间的非线性关系,HL就没有使用存在过度拟合的OLS回归方法,而是使用了几种不同的机器学习方法进行研究。[4]另外考虑到表4.1中的四种能源期货价格波动率存在着较大的差异,这样为了避免在这个期货组合中过分强调波动率高的商品品种,因此作者就计算了波动率调整的收益率:
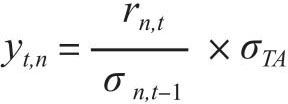
其中
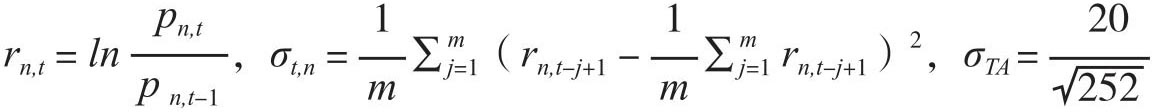
这里Pn,t表示第n种能源期货在时点t的收盘价,计算标准差时时间窗口取m=21表示过往一个月的实现波动率,[5]而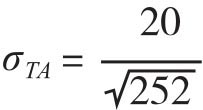 表示设定的年化目标波动率是20%。
表示设定的年化目标波动率是20%。
在应用机器学习算法方法时,作者使用了如下五种不同的模型,同时使用十重交叉验证(cross-validation)的方式对这些模型的超参数进行优化:
·弹性网络回归(elastic net regression/ELNET);
·k-近邻回归(k-nearest neighbor regression/KNN);
·人工神经网络(artificial neural network/ANN);
·随机森林(random forest/RF);
·高斯梯度增强树(gradient boosted trees with Gaussian loss function/GBN)。
期货收益率具有如下的预测形式:
yn,t=f(xn,t-1)+en,t
其中函数形式f取决于上述不同的模型,而yn,t是预测变量(特征变量)向量。由此我们看到所有的模型都是用了相同的输入变量,其中目标变量是波动率调整的对数收益率,而特征变量则是一组连续变量的矩阵。这里特征变量体现了事件类型n在时点t对商品n产生的影响:

其中i=1,…,I表示属于事件类型的事件次数。上式表明,特征变量将通过事件关联性来确定,这样如果某个事件特别相关,比如出现在标题中,那么其权重也就越大。交易策略将根据上式得到的预测收益率进行构建:预测收益率的正负符号决定了交易的多头和空头方向,而收益率的相对大小则决定了四种能源期货的组合权重。某个特定交易日的预测收益率进行标准化处理,从而确保组合的总风险敞口等于1,[6]同时四种不同期货品种的净敞口介于-1到1之间。
表4.2给出了各种模型组合的绩效指标,除了最后一列集成模型(ensembel model)以外,其中每一行中为黑色的数值表示五个机器学习模型中在这个绩效指标上表现最好的模型。A组报告了样本内分析的结果。从中可以看到各个模型之间的投资绩效存在较大的差异。但是除了随机森林这种非线性模型之外,其他的非线性模型相对于弹性网络回归这种线性模型的绩效都更好。特别是梯度增强树(GBN)和人工神经网络模型,它们得到的信息比率分别达到了2.40和2.39。B组报告了样本外的绩效指标。结果表明随机森林(RF)模型的绩效最好,其信息比率达到了0.85,同时年化收益率为13.1%。次好的模型是k-近邻(KNN)模型,其信息比率是0.83,同时14.1%的波动率是最小的。接下来是梯度增强树模型;而作为线性模型的弹性网络是次差的。这就表明对事件特征变量和大宗商品收益率之间的非线性关系进行建模的确可以获得相对更好的投资绩效。
表4.2 各种模型组合的投资绩效
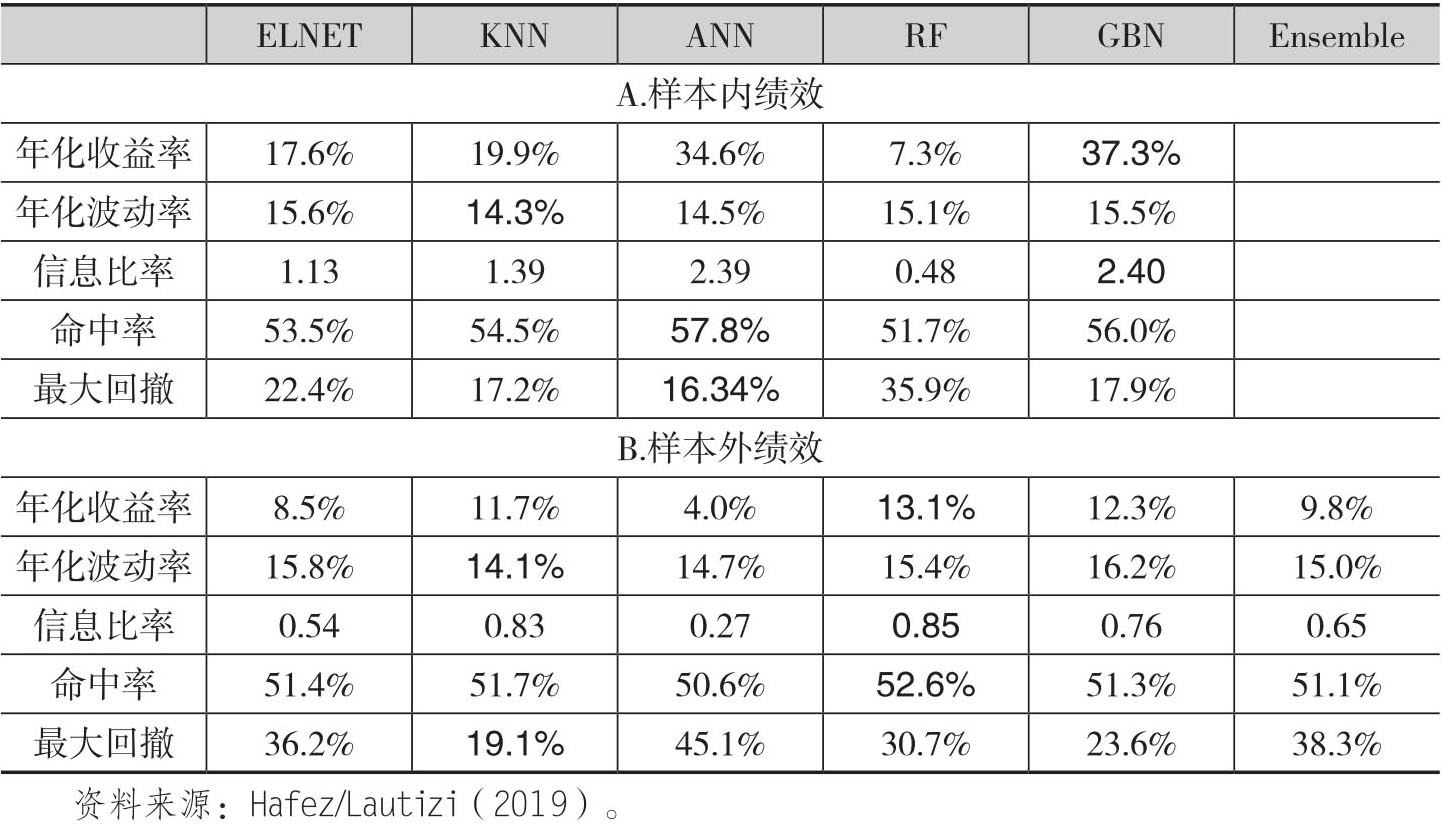
从表4.2中可以看到,样本内和样本外分析得到的最优模型存在着差异。如果是基于样本内分析进行,选择梯度增强树和人工神经网络模型,那么根据信息比率它们在样本外的绩效排名就是第三和最后一名,这表明了模型选择的风险。现在我们需要在这些模型中进行选择。一个直觉方法就是每年选择前一年表现最好的模型。但是表4.2的结果的差异表明依赖样本内选择的模型很可能会在样本外表现不佳。比如我们选择人工神经网络模型进行预测,那么样本外的绩效就是最差的。另外一种方法就是采用集成方法(ensemble method)。考虑对五种模型样本内和样本外绩效的差异,所以作者并没有根据交叉验证的误差确定权重,而是采用等权重的方式,也就是所在集成策略中,将根据五种模型的预测收益率通过等权重的方式组合在一起。表4.2B中的最后一列报告了集成方法的绩效,它的信息比率是0.65,年化收益率是9.8%。在对五种模型的相对绩效不存在先验知识的情况下,集成方法得到的投资绩效是有竞争力的,无论是绝对意义上的收益率还是风险调整的收益率。而且集成方法还可以降低模型选择风险,所以就降低可能存在的过拟合风险。
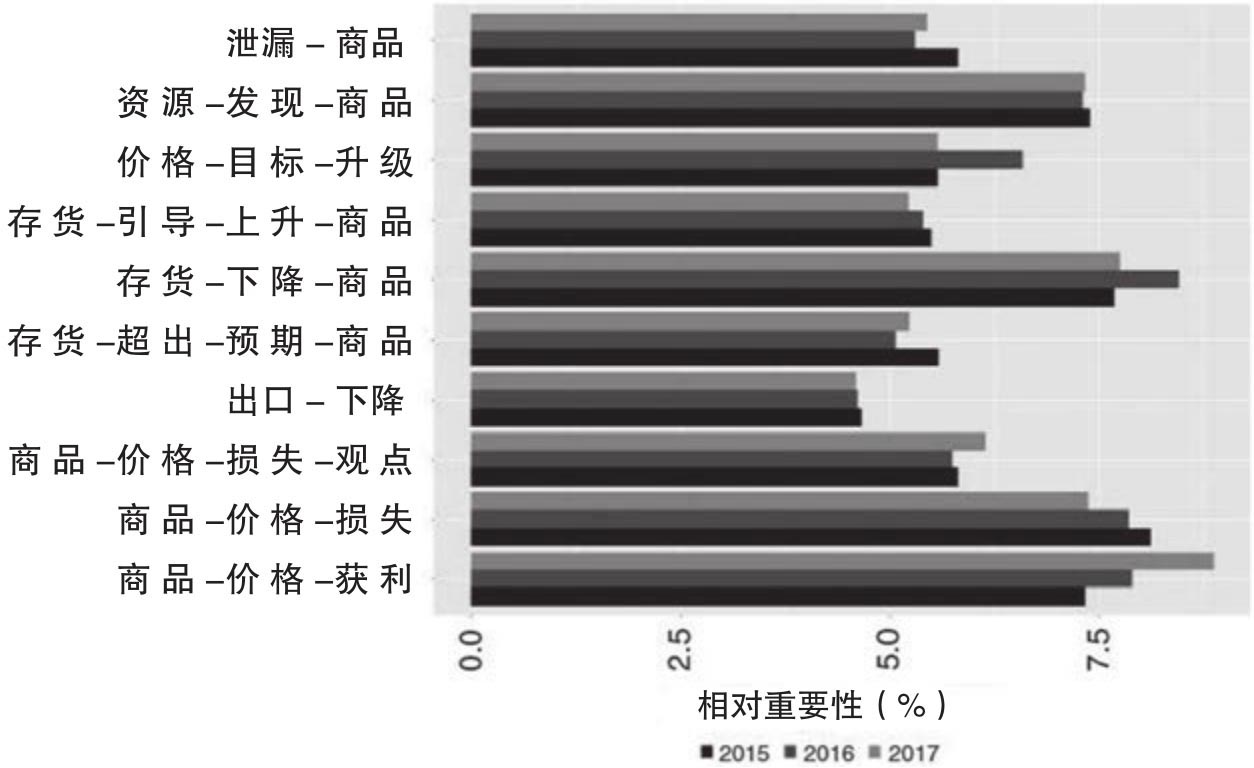
前面的分析表明如何把事件指标组合在一起产生超额收益也就是alpha,但是并没有说明哪些变量和哪些类型的事件对于超额收益有影响。作者还以随机森林模型为例说了这个问题。之所以采用随机森林模型,是因为它在样本外的绩效最好,同时它也提供了一种计算和分析特征变量重要性的清晰方法。图4.1报告了位列前十的事件类型重要性。[7]它表明和商品库存相关的事件类型是最重要的,例如“存货-下降-商品”这个事件。存货类的新闻事件对于价格影响发挥了重要作用,因为位列前十的事件类型中有三个和存货有关。此外,和供给相关的新闻事件对于价格变动也有影响。指向未来供给增加的资源发现类事件,以及让供给减少的泄漏类事件,都是影响期货价格的重要事件因素。
图4.1 不同事件类型(特征)的相对重要性
资料来源:Hafez/Lautizi(2019)。
上述分析表明,瑞文公司的事件分类体系对于商品期货交易来说是有价值的。需要指出的是,上述分析忽略了全球经济新闻这样的新闻事件,同时也没有把事件情绪评分指标纳入分析中,就像我们在第一章股票量化案例中看到的那样。同时这个案例提供的分析框架可以很容易拓展到股指期货、利率期货和汇率这样的宏观资产上。