3.4 建立态度和行为量表
在调研过程中,调研人员常常需要测量人们的主观性表现,如态度、行为、意见、看法等。这些内容不仅构成复杂、不易量化,且往往有着深层次的意涵,不容易通过单一指标进行测量。因此就需要建立适当的量表。在视听市场上有数百种已公布的量表,这些量表有些可以直接使用,有些需要根据调研需求和行业发展对其标准进行调整后再使用。人们对量表其实并不陌生,比如在常见的民意测验中就大量使用了各种形式的态度量表。本节将介绍多种常用于测量受众态度和行为的量表。但在此之前,介绍构建量表的一般步骤,见表3-1。
表3-1 构建量表的一般步骤[5]:

3.4.1 总和量表
总和量表(summated ratings)也称总加量表或总评量表,它由一组参注者对相关概念以“同意”“不同意”的态度陈述所构成并计分,通过对受访者所有选择的得分总和来表现受访者对该事物(概念)的态度。表3-2就是总和量表的一个例子。
表3-2 暴力画面总和量表
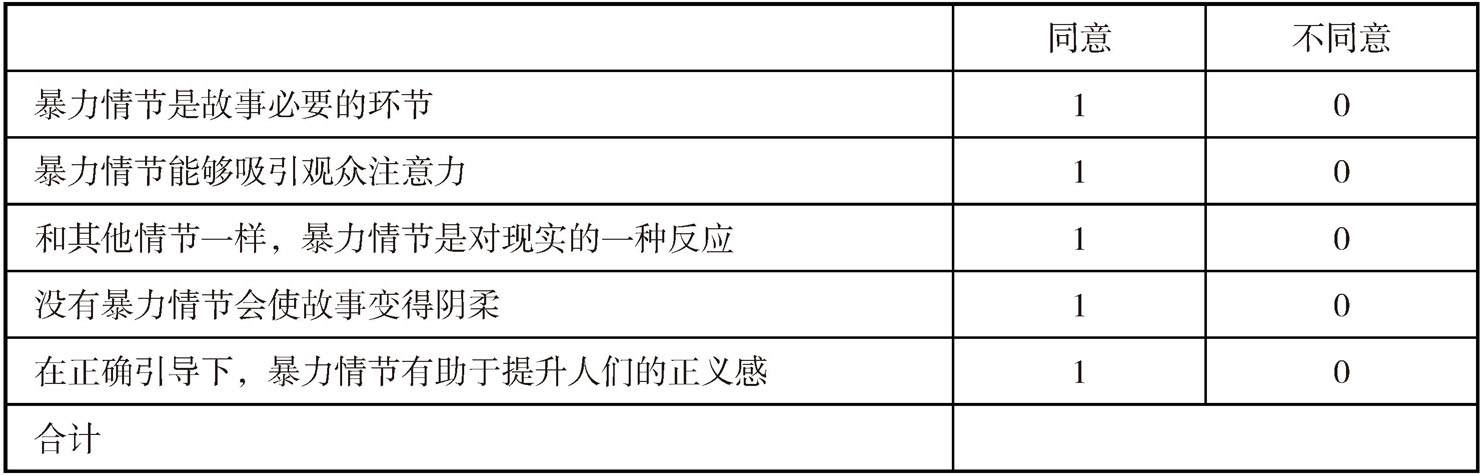
表3-2测量的是人们对视听内容中出现暴力情节所持的态度。它由同一方向(需要有暴力情节)的描述构成,每个描述对应同意和不同意两个选项。对应描述选择同意的计1分,不同意的计0分。总和一个被测者关于这5个描述的答案就得到了他对于这一问题的态度。在此例中,总分最高为5分,代表被测者强烈认同节目中应存在暴力画面;最低为0分,表明被测者认为节目中的暴力画面完全没有必要。
需要注意的是,在总和量表的描述部分,要关注描述的方向,当出现某条描述与其他描述方向相反的情况时,其对应答案的分值也应与其他描述对应答案的分值相反。比如在上例中,如果出现“暴力情节无助于故事思想的表达”这样与其他描述方向相反的描述,则其计分方法应与其他5条描述相反,即“同意”记0分,“不同意”记1分,以保证整个量表在测量方向上的一致;在总和量表的答案部分,其类别可以是两个,也可以是多个。
总和量表是否有效取决于一个重要前提:每一个关于态度的描述在反映人们的态度方面都是相等的,即每个描述的效果是同等的,这表现在每个描述的对应分值都相同上。只有当这个假设前提成立时,研究人员才能说得分为4的不同受测者具有同等的“主张应有暴力情节”的态度。同样,只有在假设成立的前提下,研究人员才能声称那些同意3条描述(得分为3)的受测者相较于同意2条描述(得分为2)的受测者有着较强的认同暴力情节的态度。
3.4.2 李克特量表
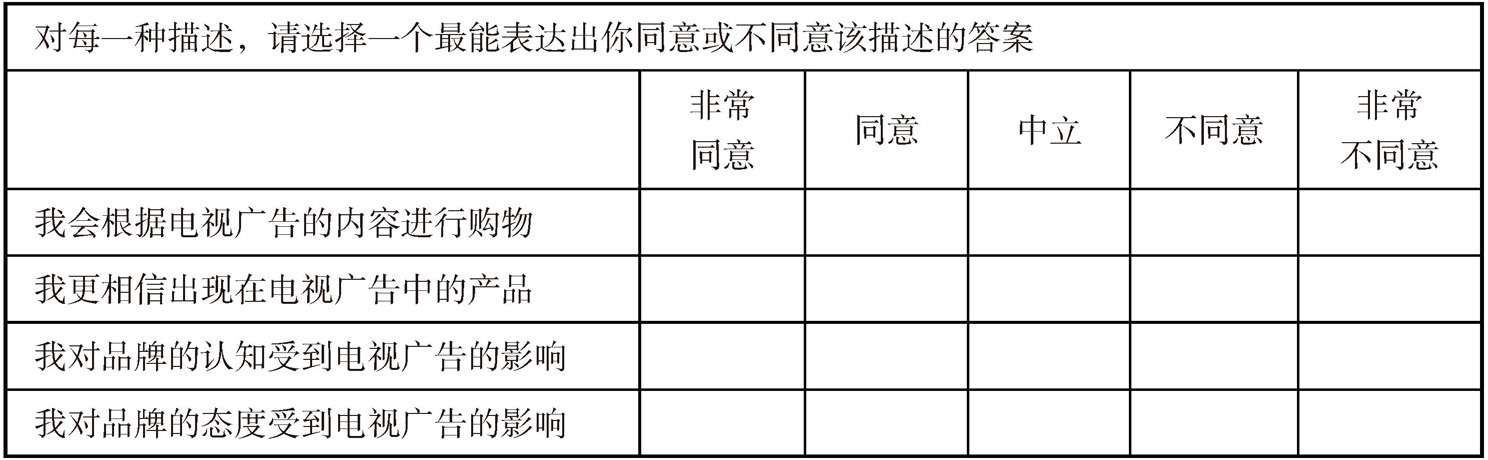
李克特量表(likert scale)是一种通过一系列的描述来探究受访者对相关事物认同程度(或不认同程度)的量表。它以最初的设计者Rensis Likert的名字命名,是在原有总和量表基础上改进而成的,最初包括5个描述答案:“非常同意(赞成)”“同意(比较赞成)”“中立(无所谓)”“不同意(比较反对)”和“非常不同意(反对)”。相较于总和量表,李克特量表的答案种类增加了,相对应的这使受测者的态度区隔体现得更加清晰。随着李克特量表被大量使用,原有的5个描述答案逐渐发展到6个,进而7个……在问卷调查、访谈中,李克特量表均被广泛使用。表3-3为一个5级李克特量表的示例。
表3-3 李克特量表
3.4.3 语义差异量表
另一种在视听市场调研中经常使用的等级量表是语义差异量表(semantic differential scale),也被称为语义分化量表。这种量表比较独特,它将几对极端的形容词放置于量表两端,将被测量的概念(如某个问题、某个群体、某个区域等)放置在顶端,每一对极端形容词之间分为7个等级(大多数分为5级或7级),并从左到右赋予分值7、6、5、4、3、2、1(也可以计为+3、+2、+1、0、-1、-2、-3)。受测者根据自己对每个描述的回答在对应位置标记,调研人员根据不同位置的标记给定分值并进行统计。通过对每个特性的均值计算,可以画出受测者的认知形象轮廓。通过语义差异量表,调研人员既可以评价不同公司、不同品牌、不同作品的形象,也可以通过询问受测者对理想作品的描述,从而比较理想情况与实际作品的差距,进而找到改善的途径。
一般认为,语义差异量表中的形容词通常包括三个维度:评价、力量和行动:
评价:好—坏、重要—不重要、专业—业余等
力量:强—弱、刚—柔等
行动:主动—被动、迅速—滞后等
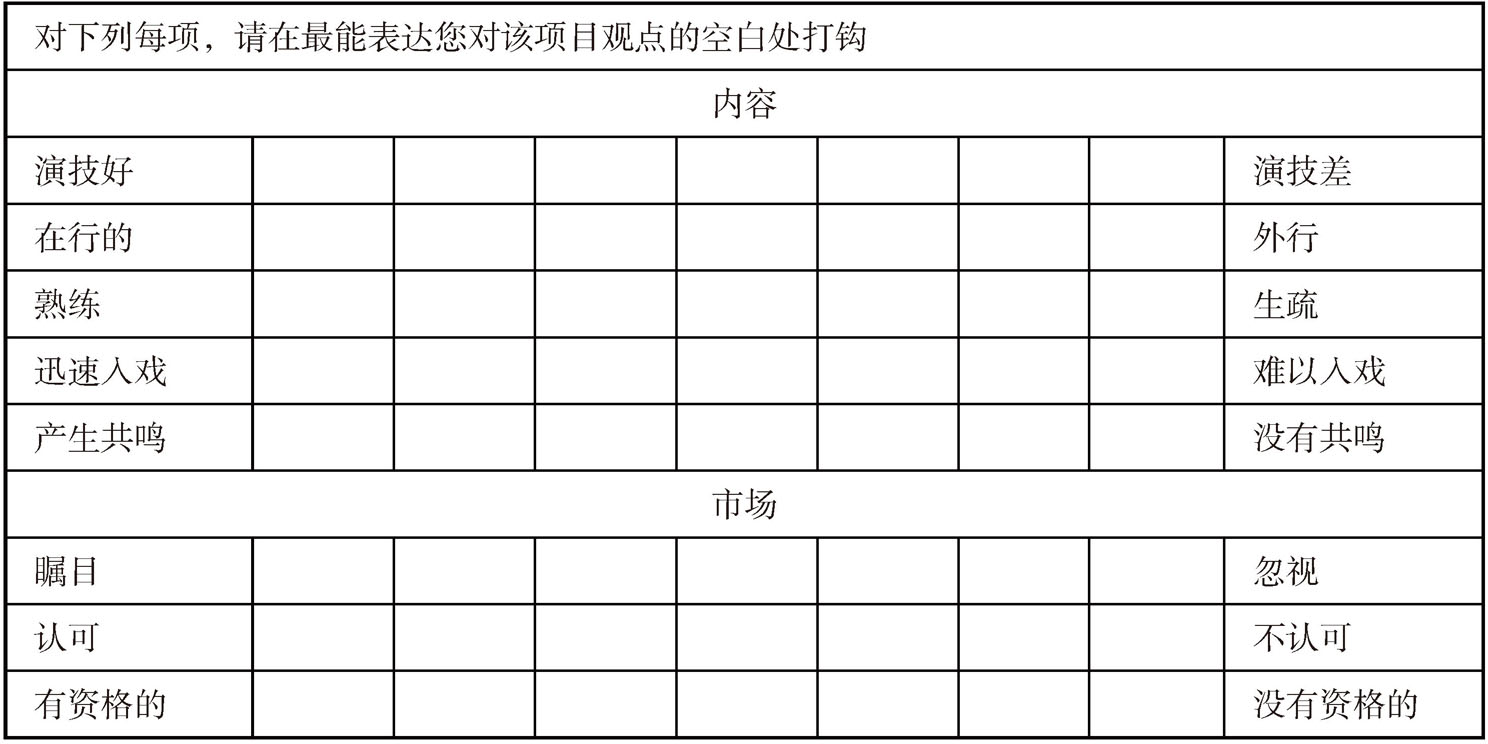
以下是一个相关实例,其中表3-4是一个关于“小鲜肉”在影视作品的作用的语义差异量表。
假设某影视公司准备筹拍一部电视剧,相关人员想了解当下目标受众对“小鲜肉”在影视作品中的态度,以作为公司是否选择“小鲜肉”参演作品的依据之一。此时会用到的关于“小鲜肉”在影视作品中作用的框架至少包括2个维度:(1)对于内容;(2)对于市场。每个维度都可以通过7个维度的语义差异量表来进行测量。
表3-4 “小鲜肉”在影视作品中的作用的语义差异量表示例
在实际调查中,调研人员经常会调查“你认为……是否重要”“你觉得……好不好”等诸如此类的问题,相较于每一个单独提问,采用语义差异量表来测量则显得更加简便。
3.4.4 其他常用量表
在视听市场调研中,调研人员还会使用的量表有行为意向量表(behavioral intention scale)和比较等级量表(comparative rating scale)。
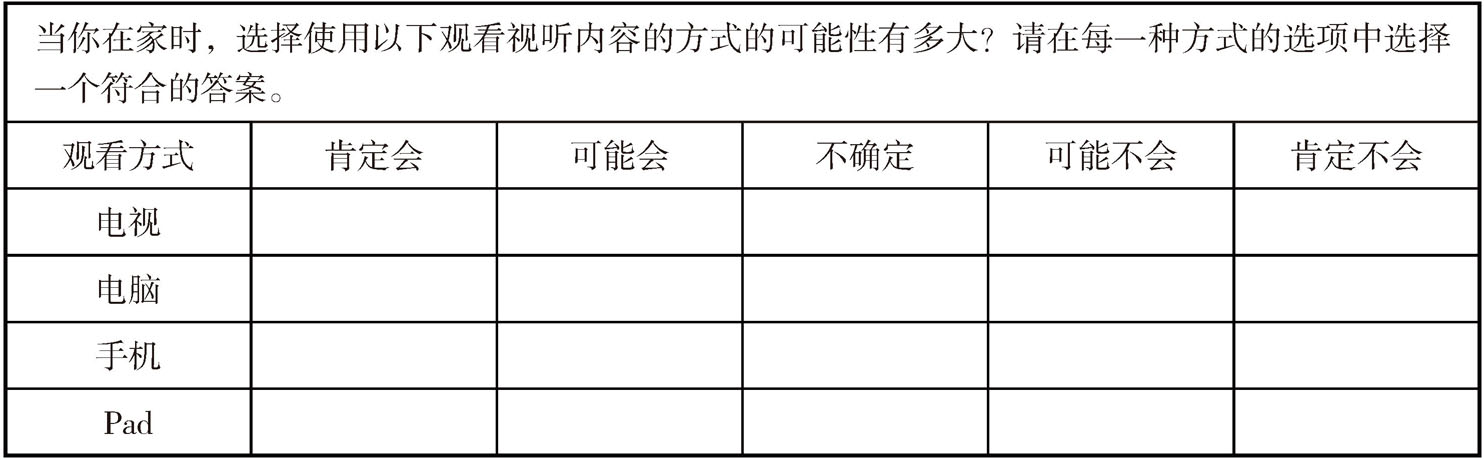
行为意向量表被用来评估用户对某个作品或服务做出对应行为的可能性,如观看意向、参与意向、购买意向等。在预测用户选择行为时,行为意向量表非常有用。行为意向量表中的量表描述一般采用“肯定会”(90%—100%)、“可能会”(61—89%)、“不确定”(40—60%)、“可能不会”(11%—39%)、“肯定不会”(0—10%)五类。表3-5是一个关于受众选择观看方式的行为意向量表。
表3-5 观看方式选择行为意向量表示例
比较等级量表也是使用较为广泛的量表之一。它包括等级顺序量表(rank-order scales)、固定总和量表(constant sum scales)以及配对比较量表(paired comparison scales)。图3-6是一个比较等级量表的示例。


图3-6 比较等级量表举例
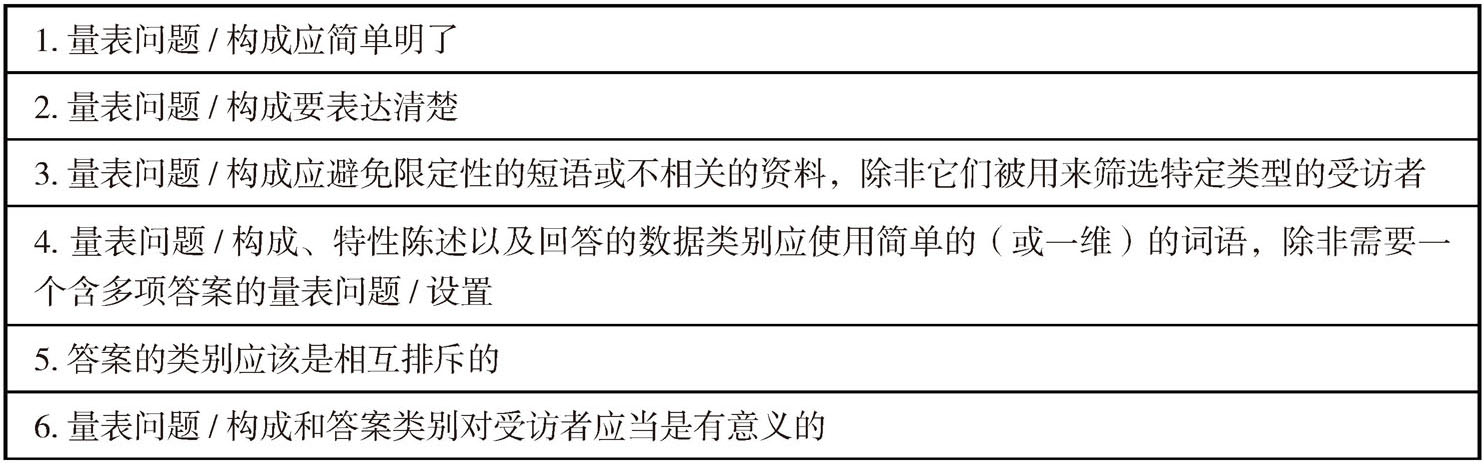
通过量表测量问题能够提高调研结果的实用性。如何构建一个好的量表不仅要掌握构建量表的基本逻辑以及常用量表的使用方法,还要保证在陈述量表问题时描述的准确性和易懂性。表3-6总结了评价量表设计是否恰当的一些原则。
表3-6 量表充分性和问题设计评价指南[6]
续表

3.4.5 评价测量量表
无论是在设计一个量表时,还是在量表测量完成后面对所收集的数据和资料时,有一些问题一直萦绕在调研人员脑海:“测得的结果准吗?符合我们所要调查的目标吗?是我们希望测得的数据吗?如果换一个环境,测量结论会不会改变?”这就涉及了量表的可靠性与有效性,即信度与效度。
信度(reliability)指采用相同方法对同一对象进行反复测量时,量表产生相同或近似测量结果的程度。由于抽样误差的存在,事实上量表测量的结果会出现不一致,因而降低了量表的可靠性。除了在设计量表时要精心设计问题之外,调研人员还可以通过重测信度和等价形式的方法来评估量表的信度。
重测信度法指对同一个受访者在不同时间用相同量表进行多次调查,或同一目标群体下对多个近似目标对象进行同一量表测试,根据多次结果的差异程度判断量表的信度。如果多次结果(如第一次与第二次)差异不大,则我们认为该量表表现稳定,因此是可靠的。
重测信度法在三个方面存在风险:(1)多次调研间时空环境等外在因素的变化会导致同一受访者答案的改变;(2)完成第一次调研的受访者可能不会参加第二次量表调研;(3)相同受访者在反复测试中,对相同问题会变得敏感,因而改变答案;4.个人因素可能会发生变化,因而使第二次测量答案发生变化。等价形式法则在一定程度上解决了这些问题。
等价形式法是指调研人员根据测量框架制定两组相似但不相同的测量量表,让一个受访者或同一目标群体下的多个不同受访者接受测量。通过计算两个测量量表之间的相关性(相关系数越高,可靠性越强)来确定等价量表的可靠性。
然而一个可靠的量表并不一定是一个有效的量表。调研人员不仅要考虑量表的可靠性,还要考虑量表的有效性,即效度。量表的效度(validity)又被称为量表的准确度,指测量结果和实际结果的一致性程度,或者说是量表能够准确地度量客观事物的程度。评测效度的常用方法有两个,一个是表面效度,另一个是构建效度。表面效度是指测量内容与测量目标之间的逻辑关系,调研人员根据自己对相关概念的理解评估框架下的各个陈述能否测得所需内容。构建效度则是通过目标概念与其相关概念的测量来完成的。比如我们需要测量受众对某节目的满意度,则我们应先确定以下假设:对节目的满意度与受众观看节目后在微博上发表评论的行为有关,且受众满意度越高越会主动发表评论。那么,如果我们最终测得的节目满意度与发表评论的结果具有一致性(符合假设),则测量具有建构效度;而如果节目满意度不同的受众在发表评论这一行为上相似或相同,则测量的构建效度就会面临挑战。
需要注意的是,信度和效度都是一个相对的值。对同一目标对象,不同的调研人员会采用不同的测量方法(框架)和指标(描述),这些方法没有对错之分,但存在效度和信度的差别。在选择测量方法时应遵循这一原则:越是可靠性和有效性高的方法越是好的测量方法。在资源较多的情况下,可以先对目标人群中的100名受访者进行试验性研究,确定测量方法的信度和效度,然后再决定实际测量方法。在资源有限的情况下,可以通过专家(小组)评估来确定测量方法。