5.2 内容分析法设计
由于内容分析法只能对媒介内容进行描述,所以其研究对象只能是已被记录、保存的媒介内容。内容分析法作为一种调研方法,其价值集中体现在基于内容描述基础上的研究推论。本节将以格伯纳对于电视暴力的相关测量作为连续案例,详细介绍内容分析法的操作步骤。
5.2.1 操作步骤
一般来看,内容分析法由以下操作步骤组成:(1)界定研究目标、研究问题;(2)界定研究总体;(3)抽取样本;(4)构建测量框架,对内容进行编码;(5)分析数据;(6)报告结果。对于部分在前文中已经做过解释的步骤,这里将只做简单解释。以下将以格伯纳有关电视暴力研究中在“讯息系统分析”部分所采用的内容分析法为例对各操作步骤进行说明。
界定研究目标、研究问题
研究目标、研究问题应该是清晰且具体的。只有在明确的研究目标基础上展开调研,才能收集到有效的数据,研究才会有意义。
20世纪60年代后期,美国社会的暴力和犯罪问题很严重。针对这一社会现象,美国政府成立了“暴力起因与防范委员会”,邀请格伯纳在该委员会主持研究解决相关问题的策略的工作。格伯纳指出,人们获取知识的途径是多种多样的,而这些知识构成了人们对现实世界的理解,因此,在不知道具体的电视媒介在为人们描绘什么样的世界之前,就讨论电视暴力的方法是不可取的。格伯纳的团队从对社会暴力和犯罪问题的研究这一最初的调研问题,进展到重新界定调研问题,并提出了以下两个研究目标:一是分析电视画面上的凶杀和暴力内容与社会犯罪之间的关系,二是考察这些内容对人们认识社会现实的影响。
界定研究总体

报告中文版二维码
对研究总体的界定将帮助我们在浩如烟海的媒介内容中确定我们要研究的对象究竟是哪些。回到格伯纳的相关研究上,根据他所提出的研究问题该如何界定出研究总体呢?问题的关键落到了对“暴力”的界定上。世界卫生组织(WHO)在《世界暴力与卫生报告2002》中将暴力定义为:蓄意地运用躯体的力量或权力,对自身、他人、群体或社会进行威胁或伤害,造成或极有可能造成损伤、死亡、精神伤害、发育障碍或权益的剥夺 。WHO认为暴力行为的本质可以是 :躯体的、性行为的、精神的、剥夺和漠视的。
一般而言,对于肢体暴力这个范畴争议较小。根据调研的需要,我们可以就暴力的定义提出一些基本的问题,如除了肢体暴力外,语言暴力纳不纳入研究?除了蓄意伤害外,意外伤害纳不纳入研究?除了受到伤害的行为外,未造成伤害的行为纳不纳入研究?格伯纳给出的答案是,暴力是指公然表现出对自己或他人的攻击行为,或者其他强迫性的行为,从而让其承受伤害所带来的痛苦或实质造成人身伤害或死亡(The overt expression of physical force against self or other,compelling action against one’s will on pain of being hurt or killed,or actually hurting or killing)。根据定义可以看出,格伯纳将有明显肢体暴力的行为作为测量的标准,而将心理上的伤害、言语暴力等排除在外。
接下来,格伯纳以ABC、CBS、NBC的相关电视节目(television drama)作为目标总体。还记得界定目标总体的方法吗?既定目标总体通常由个体、抽样单位和时间范围组成:
个体:三大电视台的所有节目
抽样单位:三大电视台所播放的电视剧、卡通节目、电视上播放的电影
时间范围:自1967年来每周黄金时段以及周末白天时段[3]
抽取样本
信息时代,各种媒介生产了大量的内容。仅以电影为例,根据《国家电影局关于2018年07月(上旬)全国电影剧本(梗概)备案、立项公示的通知》所示,仅2018年07月01日—07月10日,全国处理备案故事影片共133部(其中现代题材(49年以后)99部,占74.44%,历史题材(49年以前)34部,占25.56%);全国处理备案动画影片共11部、纪录影片共15部、科教影片共4部、特种影片共5部。[4]调研人员需要从大量的媒介内容中抽取具有代表性的样本,以保证调研的质量。
根据目标总体的定义,格伯纳团队就能够得到所有符合条件的全部抽样单位(抽样框)了。到相关报告(Cultural Indicators:Violence Profile NO.9)发表时为止,项目共抽取分析了1437档节目、4106个主要角色以及10429个次要角色。
构建测量框架,对内容进行编码
在第三章中我们已经对框架做了详细的分析。总的来说,框架由一系列可被测量的单位(维度)所构成。一系列的框架共同定义了调研目标。
在确定测量单位的基础上,就可以对所测内容进行编码。如同问卷是调查法的测量工具,编码表是内容分析法的测量工具。编码表(code sheet)是指记录了分析单位相关信息的表格。在一次内容分析中,所有样本应采用相同的编码表。
为了进行研究,格伯纳确定了以节目、暴力事件和角色三个测量框架为基础的编码表,对目标对象进行搜集与分析。
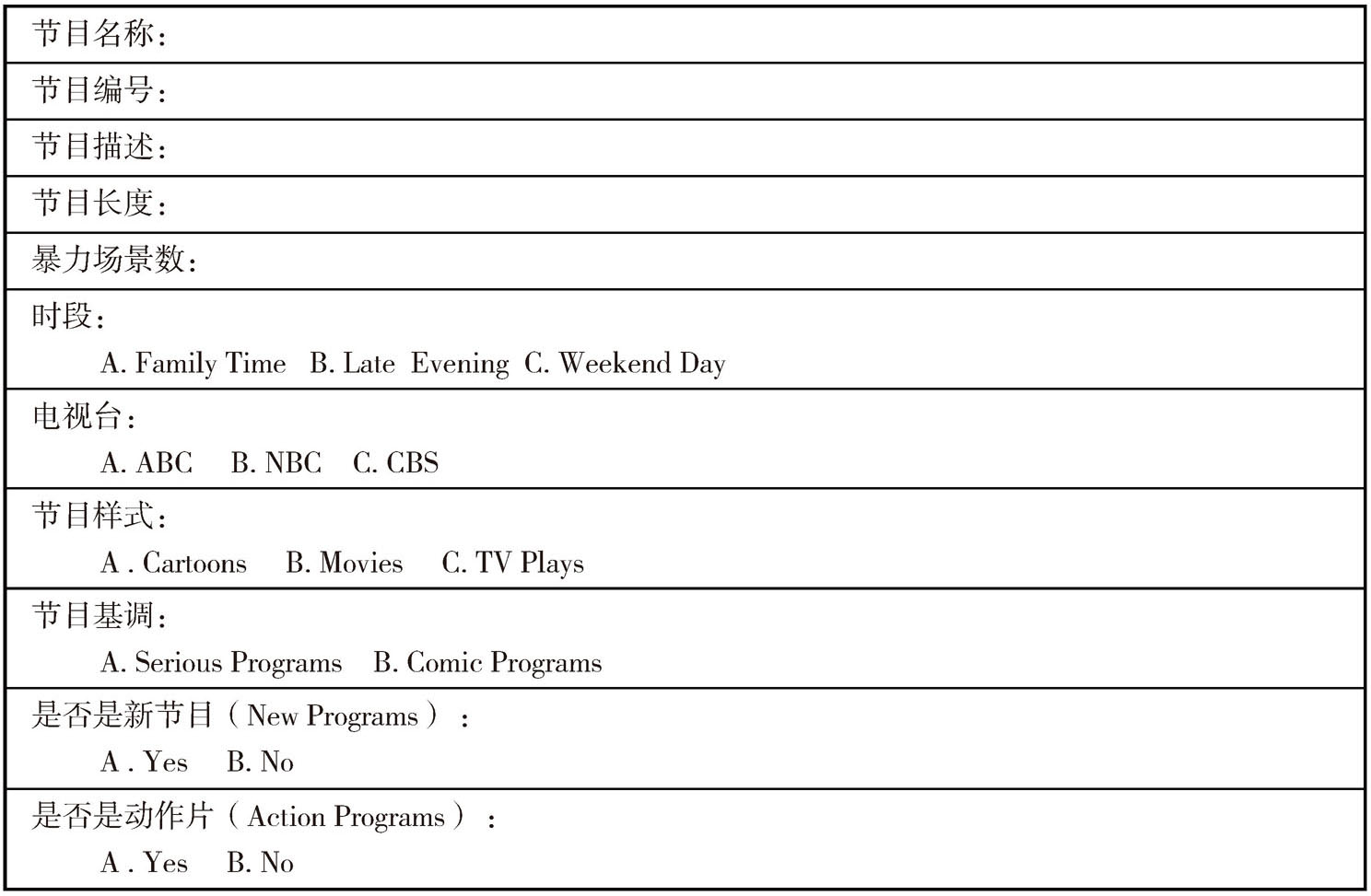
节目(program):以戏剧性的形式将一个虚构故事呈现出来。在取样周期中,它可以是用于电视放送而生产的一出剧目,在电视中播放的故事片(电影),也可以是一个动画片(在一个节目中可能播放一个或多个动画片)。以上这些被用来单独分析并以“节目”这个名称来记录。所有在调研期间播放的节目都基于是否包含暴力来进行分析。其记录表格如表5-1所示。
表5-1 节目记录表[5]
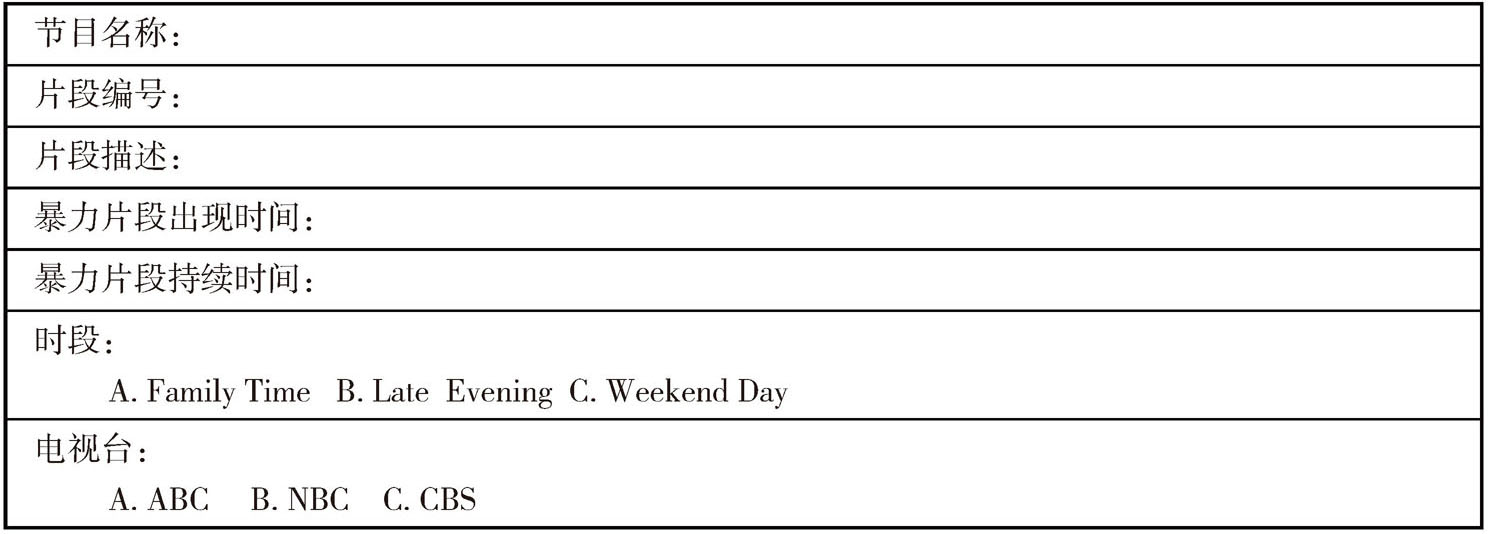
暴力片段(violence episode):作为分析单元的暴力事件是指限定于共同参与下的暴力场景。如果一个场景被打断(通过闪回或者转向其他的场景),但是在“现实时间”中还在持续,则其依旧属于一个相同的片段。然而,角色的变换,如一个新的暴力形象进入这个场景,那么就开始了另一个暴力行为。其记录表格如表5-2所示。
表5-2 暴力片段记录表
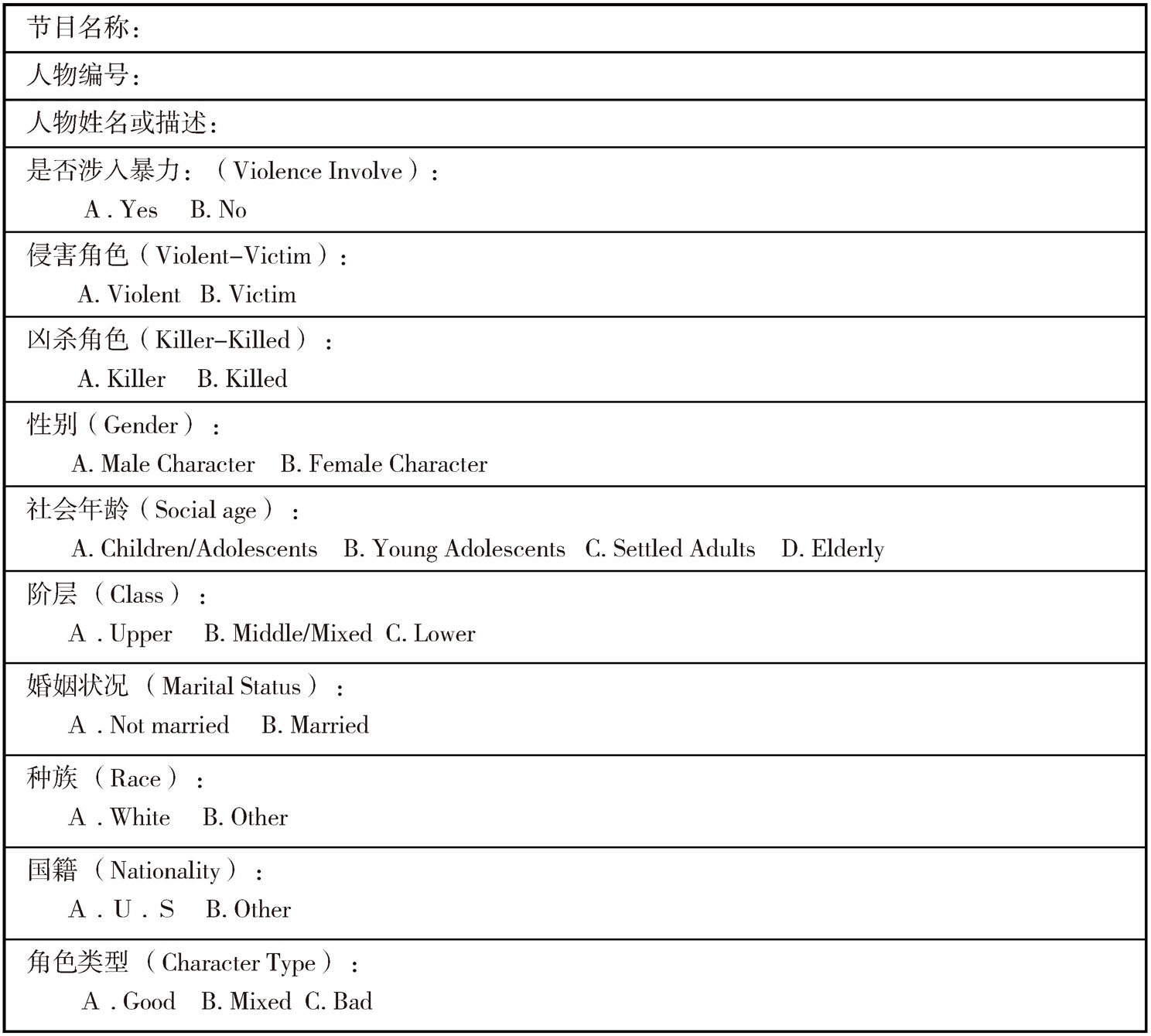
角色(characters):所有节目中的角色将被划分为两类。对故事至关重要的主要角色(major characters),是根本角色。次要角色(minor characters)指其他所有有台词的角色,只做简略分析。其记录表格如表5-3所示。
表5-3 角色记录表
在进行编码前,需要对编码员进行培训。如同在问卷调查法中所提及的,访员不一定是研究者一样,设计编码表的调研人员可能并不是编码员。在实际操作中,编码人员往往由多人组成。因此,通过培训让编码员理解调研的目的,掌握统一的编码手段,成为内容分析法执行过程中必不可少的环节。一份详尽的编码说明能够有效地帮助到调研人员。编码说明(coding instruction)是一份对每个测量指标及类型都作出清晰、明确解释的编码指导说明。只有各访员的编码方式一致,才能降低因编码(访员对指标的模糊)所带来的误差。
分析数据
编码结束后,就可以将所得到的数据通过统计学方法进行分析。常用的统计方法在第三章测量中已做过介绍,我们还将在后续章节中做更具体的介绍。
根据编码得到的数据,格伯纳给出了有关暴力指数的公式:
暴力指数=PS+CS
其中PS由P%(含有暴力情节的节目与全部节目样本数的比值)、R/P(暴力情节次数/样本总数)和R/H(暴力情节次数/样本总时数)构成;CS由V%(施暴者或受暴者的百分比)和K%(杀人者或被杀者的百分比)构成。图5-1是详细的暴力指数计算方法。
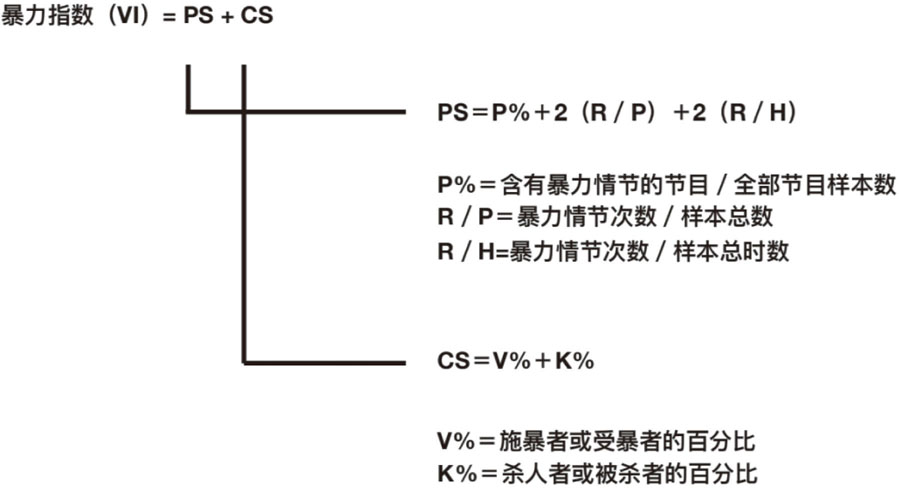
图5-1 暴力指数计算公式
图5-2是根据1967—1975年间的相关数据所得到的暴力指数。通过内容分析法,格伯纳得到了电视暴力指数变化图、三大电视网在家庭收看时间、夜间以及周末白天交叉的电视暴力指数、不同节目类型、电视网、时间段交叉的暴力指数、电视暴力比例和电视暴力角色等相关数据。
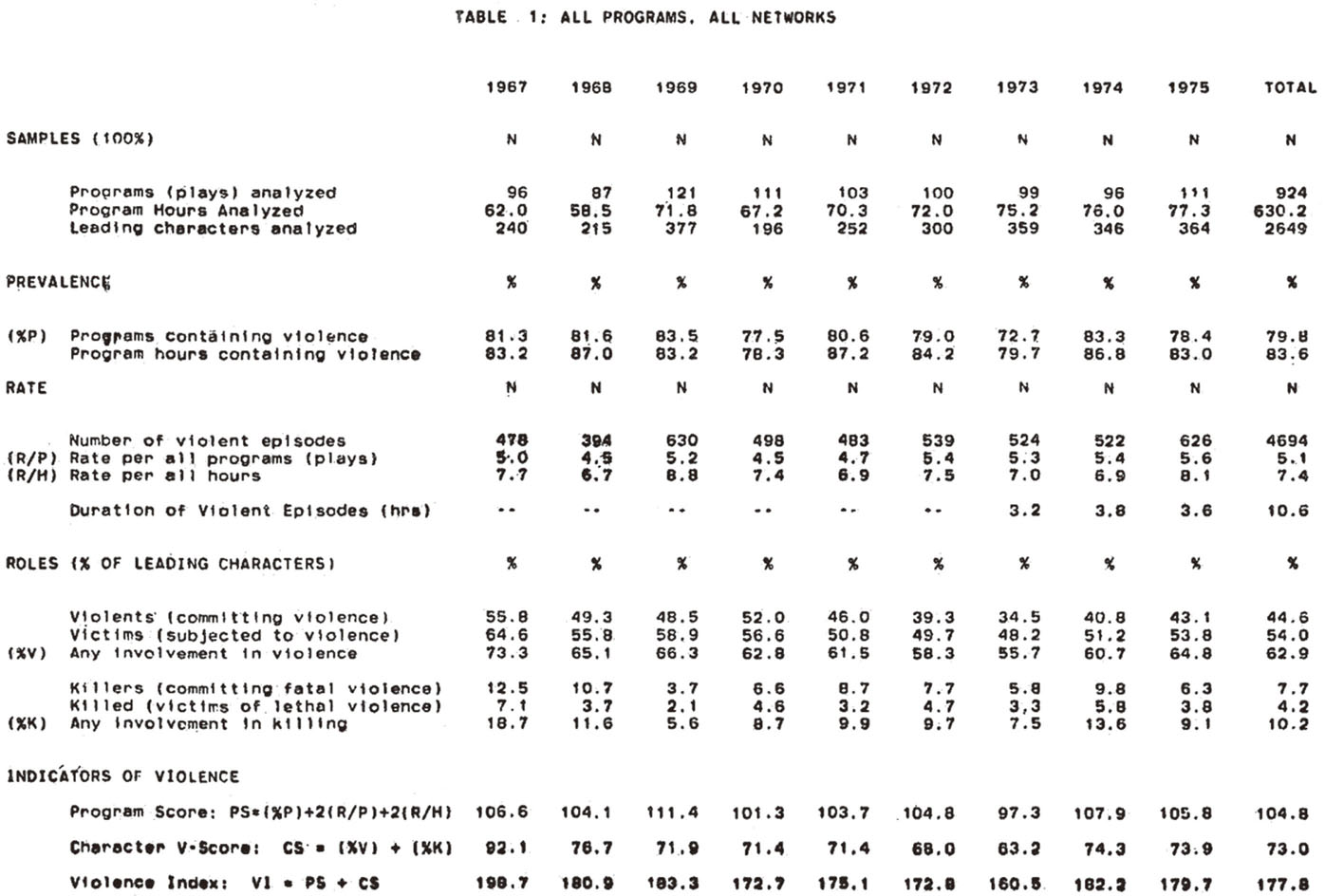
图5-2 1967—1975年暴力指数表(全节目、节网络)
报告结果
最后,对数据进行解释,并尝试根据数据分析的结果来回答研究问题。如果研究问题涉及社会现实,则还应根据分析所得到的特性去推断媒介内容与社会现实之间的变化关系。1976年,格伯纳根据相关调查内容完成了论文“Living with television:the violence profile”。
5.2.2 编码员间信度
信度和效度的相关概念我们在第三章做过解释。从抽样到数据分析,内容分析法同调查法一样存在着准确与否的问题。本节我们将介绍内容分析法所特有的问题——编码员间信度问题。所谓编码员间信度(Inter-coder reliability),指的是不同编码员在使用内容分析法进行编码时的一致性程度。当编码一致性程度高时,内容分析法的结果所具有的信度就高。反之,当编码一致性程度低时(不同编码员对同一研究对象的编码差别大),其结果所具有的信度就低。由于人为因素导致编码过程中出现误差的常见原因主要源自两个方面:编码表设计和编码员自身。表5-4是对这两个方面的简单描述(抽样误差不可避免,只能降低)。
表5-4 编码过程的误差来源

一般来说,如果运用内容分析法的调研规模较小,编码工作常常由一个编码员完成,那么如何复查其编码质量呢?我们会从中抽取出部分样本,安排第二个编码员进行编码,从而检验样本的两次编码的信度。
编码员间信度是一份内容分析报告中必不可少的内容,它反映了报告结果的有效性。编码员间信度计算的公式有多种,我们将通过一个实例介绍其中3种计算方法。
实例:某研究团队针对凤凰网首页要闻栏目下新闻类型进行了编码(共5种类型),部分编码结果如下。
表5-5 凤凰网要闻栏目新闻类型编码结果(部分)

编码员间信度计算:霍斯提公式(Holsti)
a=2M/N1+N2
M代表在一次编码行为中,不同编码员选择相同编码的数量;
N1代表编码员一进行编码分类的样本总数;
N2代表编码员二进行编码分类的样本总数;
以表6-5数据为例,根据霍思提公式可算出在此内容研究上,编码员一与编码员二的编码员间信度为:
a=(2×7)/(10+10)=0.7
霍斯提公式是编码员间信度的计算公式中最简单的一种,但它并没有考虑到随机因素带来的一致率现象。如当某一指标只有2个类别时,编码员即使不根据实际情况而使用完全随机的方式编码,其编码员间信度也会达到50%。因为未能解决这种问题(偶然随机因素),所以霍斯提公式未能被广泛运用。
编码员间信度计算:Scott’s Pi指数
针对霍斯提公式中的缺陷,Scott提出了Scott’s Pi指数公式:
π=(π0-πe)/(1-πe)
π0代表观察到的一致性的百分比,可以通过计算霍斯提公式中的a得到。
πe代表期望的一致性的百分比,通过计算编码中每个类别的百分比的平方和得到。
根据表5-5的数据:
π0=0.7
两个编码员同时选择类型1(根据表5-5,编码员一出现1次,编码员二出现1次,共出现2次)的概率为0.01(2/20×2/20);选择类型2(编码员一出现1次,编码员二出现2次,共出现3次)的概率为0.0225(3/20×3/20);选择类型3(编码员一出现3次,编码员二出现2次,共出现5次)的概率为0.0625(5/20×5/20);选择类型4(编码员一出现3次,编码员二出现3次,共出现6次)的概率为 0.09(6/20×6/20);同时选择类型5(编码员一出现2次,编码员二出现2次,共出现4次)的概率为 0.04(4/20×4/20)。则πe的值为
πe=0.01+0.0225+0.0625+0.09+0.04=0.225
π=(0.7-0.225)/(1-0.225)≈0.6129
编码员间信度计算:Cohen’s Kappa系数
这是一种被广泛使用的指数,在SPSS等统计软件中可以直接计算。其公式表达形式与Scott’s Pi指数一样,但πe的计算方法不同。在计算πe时,其思路是将两个编码员各自选择概率单独计算后相乘,并对结果求和。
以上方法只能用于计算由两个编码员完成编码的编码员间信度。如果是大型的内容分析研究,则可以通过Krippendorf的a系数计算公式得到。对我们而言,一般不会进行大型的内容分析研究,故在此不做解释,如有需要请自行查找学习。但总的来说,在大型内容分析研究中,当多个编码员之间对编码产生意见分歧时,通常会通过试编码来进行协调。