9.1 数据准备阶段
在做任何分析之前,都必须对我们所搜集的数据进行量化处理。所谓的将数据转换为数字形式,其实是指将我们所搜集的社会科学类的数据转换成为可以被机器读取的形式,即可以被计算机程序读取并操作的形式。数据准备阶段包括了3个步骤:数据验证、数据编码和数据录入。
数据验证
数据验证(data validation)的目的是为了确认研究方法(调查、实验等)的执行过程是否正确。常用的验证方法有三种:对数据进行简单处理,观察其有无违背经验、常识;与其他数据来源进行比较;回访。在市场调查中,最常用到的验证方法是回访。在量化研究中很难完全避免出现虚假数据的状况,比如收视率造假等。虚假数据(curbstoning)指的是访员在调查过程中不对受访者进行数据搜集,而是由访员自己虚假填写或篡改受访者信息所得。这使得数据验证成为整个量化研究的重要环节。一般情况下,研究人员会抽取10%(最高到30%)的受访者,通过电话、邮件等方式进行回访,以保证数据搜集过程的可靠性。通常情况下需要被验证的内容有:
是否欺骗:访员真的“访问”了受访者吗?
是否符合筛选:被“访问”的受访者符合研究要求吗?
是否按照程序:数据搜集的过程有按照程序执行吗?
是否完整:访员是否在“访问”过程中编造受访者的部分回答?
数据编码
在完成了对数据的验证后,第二步就是对数据进行编码。针对封闭式问题和开放式问题(参见第五章调查法),研究人员有着不同的编码方式,但其基本思路通常是通过对所得到的资料进行归类和赋值完成,以下是一些对数据进行编码(转换)的例子:
通过制定数字来表示定类和定序变量
将调查答案中的“男”以数字“1”来表示,“女”以数字“2”来表示
用数字“1”代表“感兴趣”,“0”代表“无所谓”,“-1”代表“不感兴趣”
为连续变量(定距变量、定比变量)赋值
用数值3表示看过3部电影
用数值22来转换出生年份:2000(当下是2022年)
这些方法多用在封闭式问题的答案编码上。但在实际编码过程中,还会出现一些更具挑战性的数据,那就是通过开放式问题获得的数据。由于开放式问题允许受访者自由回答,这使得通过数字直接对答案进行转换变得不再可行。但开放式问题同样需要编码,且必须编码。因此,研究人员一般通过两种基本的方法对开放式问题的答案进行编码:
依据由研究目的所编撰的编码表(编码方案)来执行编码
在对所有开放式问题的回答(数据)进行梳理的基础上,从数据中归纳生成编码
请记住编码的逻辑是将大量不同的信息归纳转换成一组极为有限的变量属性。以下是一个针对开放式问题的编码步骤举例:
问:你的职业 ______ (很显然不同的受访者在横线处填写的答案可能不同)
(1)归类(合并)
根据事先准备好的编码表可以将不同答案划归为:专业人员、管理人员、行政人员、半职业人员、自由职业者等。(想一想为什么不选择在这里直接给出这些选项让受访者选填呢?)
在考察完所有数据后,基于所获取答案的特征创建一份编码表
(2)赋值
根据编码表中的不同类别进行赋值:专业人员=1,管理人员=2,行政人员=3……当受访人员在横线处填写为“灯光师”时,就可以将其编码为“1”
请记住,如果数据在被编码时保留了大量的细节(即分类细致),那么这些归类可以在之后被再次合并(减少)。但是,如果在编码的初始就只有很少的分类,那么在未来将无法把因合并而失去的细节找回来。如果使用的是调查问卷,那么基于编码表来进行编码无疑是明智的选择(如创建一个编码表)。
编码表的创建其目的在于:
在编码过程中有可依据的主要指南
注意到分配给每个变量属性(响应)的值
成为分析过程中对变量定位和编码解释的指引
在数据输入阶段指导数据集的构建
在问卷调查中,研究人员不仅需要对所得到的答案进行编码,还应该对问卷本身进行编码。通常来说,如果问卷总数小于1000,则采用三位数进行编码,如001,002;如果问卷数量超过或等于1000,则因采用四位数编码,如0358,0876,以此类推。
数据录入
在完成检验和编码后,接下来就是对数据的录入了。数据录入(data entry)是一个将数据录入到计算机,为后续数据分析做准备的过程。它是一个单调且冗长的过程,但实际上当下最为普遍的数据搜集方法是通过网络调查的方法来获得数据,其好处不仅是速度快,而且可以免去数据录入的过程。若依旧使用传统方法进行数据搜集,则数据录入人员会将相关资料按照编码表录入到如SPSS数据文件、Excel电子表格或ASCII文件中。表9-1归纳了不同属性文件的数据录入过程。一般情况下,在数据录入阶段,研究人员至少会安排两名录入人员分别完成对数据的录入,通过比较两人的录入结果,尽可能地保证在数据录入阶段不会出现人为失误。在数据录入阶段,研究人员往往选择使用ASCII文件来完成录入,因为ASCII文件几乎可以被所有统计软件所读取或使用。它可以被导入进SPSS和Excel中,甚至可以直接在SAS中进行操作。
表9-1 不同属性文件的数据录入过程

数据清洗
数据录入完毕并不意味着可以马上进行数据分析。录入完的数据还需要将其中的“脏”数据剔除出去才可以使用。事实上,做数据项目时,大部分时间常常都花在了获得准确、可靠并是可用格式的数据上。脏数据(dirty read)是指数据格式可能不对、同一个事物可能有不同的拼写方式、数据存在输入错误、部分数据可能缺失、数据质量有问题、计算结果和设想不同、数据样本可能有偏向,甚至数据部分或全部都是假的。比如,在传统收视率调查中,需要受众自行填写收看时间、收看时长等,这些情况都可能因书写习惯而导致记录形式存在差异(即便在事前做了足够的规范)。对脏数据的处理过程被称为数据清洗(data Cleaning)。
比如,在定类数据中,同一名字的不同拼法会在数据集里引起大问题。任何时候,只要你有类型性数据,类型名必须得前后拼写一致。当你拿到一份数据文件时,可能会出现如图9-3所示的情况:这是关于美国的获奖电影的相关信息,数据被纳入了不同的“美国”名称中,这时如果需要计算所有“美国”的获奖影片在数据集中出现的次数,而只指定一种拼写(如U.S.A.),那么这次分析就错过了所有其他拼写方式。这种情况并不罕见,如果你没有意识到可能存在这样的问题,你甚至不知道所有其他的拼写方式也没有被纳入计算。另一个例子出现在数据新闻中,美联社有关卡扎菲名字的所有拼法多达200余种,这意味着如果有记者想以美联社有关卡扎菲的报道为资料做相关分析的话,他需要解决的一大麻烦是如何将这些名字统一起来(图9-4为部分卡扎菲名称列表)

图9-3 定类名称举例

图9-4 美联社所用卡扎菲名称(部分)
类似的问题也可能出现在数字中,比如关于收入,不同的数据录入方式也会给研究人员带来困扰。如:
10000
10,000
1万
…
设想你要对一长列的不同电影的票房收入进行计算,取平均值,其中一个数字是1.13 billion(billion = 10 亿),而电脑却以为它是1.13,你得到的答案会和实际相去甚远。
我们可以采用Open Refine软件对数据进行清洗。Open Refine是Google开发的一款开源软件。通过该软件研究人员能够轻松地完成诸如数据归类、数字清理等任务。
下面我们简单地介绍Open Refine软件的使用方法(具体方法可参考Google官方提供的Open Refine操作手册)。
第一步,载入数据文件,打开Open Refine,点击屏幕左侧的“新建项目” (Create Project):

点击“这台电脑” (This Computer),然后点击“选择文件”(Choose Files)。 选择你需要清洗的数据文件后,相关数据会显示在窗口内。
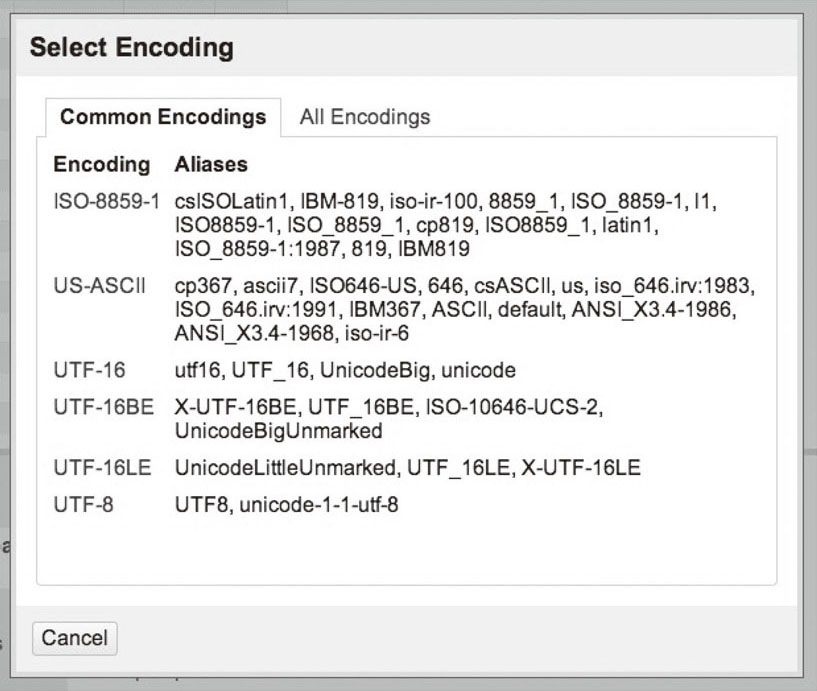
当数据中包含有中文(如列的名称)时,可能会显示乱码,这时就需要修改编码方式。点击“字符编码” (Character encoding)旁边的空白空间,从中选择UTF-8(因为常用的编码方式为ASCII):
当确定数据载入没有问题后,点击右上方“新建项目”(Create Project),就可以进入清洗界面了。
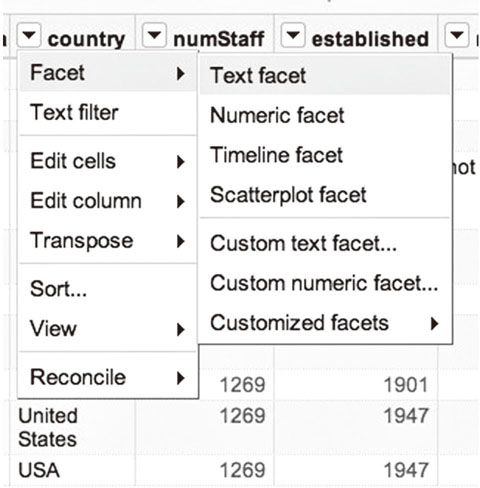
你可以看到country (“国家”)这一列中,国家名字不统一。例如,美国既叫 United States,也叫USA。我们要通过创立一个文字归类,让Open Refine 展示出 country 一列中所有的值。通过country 旁边的小箭头选择归类 (Facet)-> 文本归类(Text Facet)。在对应生成的展示窗口里,我们可以通过编辑文字统一美国的名称。除了文本归类,Open Refine还提供了数值归类、时间线归类、散点图归类等功能,在这里就不再叙述。大家可以根据官方介绍实例进一步深入学习。