2.3.2 诊断评价的特点
诊断评价也称分析性评价。诊断评价多见于语言学习者日常翻译训练,在机器翻译领域的评价中开展得很少。人工诊断评价的角度涉及译文的很多方面,比如语法形式是否正确、语义表达是否准确、语体是否恰当,甚至包括文化背景是否符合等等都可以列为诊断评价的内容。通常的情况下,诊断评价的结果是以文字说明的形式给出错误有关内容的描述。下面是一段教师对学生汉英译文常见的评价形式,利用Word中批注功能对译文进行了详细的评改:

上一节中我们介绍了制定诊断评价标准的例子。实例中对译文诊断的内容进行了量化处理,属于一种简化的诊断评价方式,就是判断译文中重要的语言点信息有没有译出,有没有错误。部分较小规模的翻译考试和日常训练中也会采取这种方式。这种简化的诊断评价方式可以方便与宏观评价结合起来,作为宏观评价的基础和依据。比如,通过为特定的语言点设定分值,根据测试译文是否能够译出或准确译出这些语言点给予相应的分值,然后通过累加得分的方式得到整体得分。
以下是一个针对语言点的诊断评价的实例,句子中的下划线部分为出错的位置,句子最后的括号里标注了译文的错误类型:
①在这种衰竭的关系中,夫妻或对彼此,或对他们的婚姻失去激情或兴趣。(词或短语搭配不当)
②我们走在小路上,路两边全是密密麻麻的针叶树。大大的常绿树覆盖在针叶林上。(词或短语不符合常识或自相矛盾)
③接着,我转过拐角。于是我停下来了,被这儿迷住了。(“于是”多余)
④这是个寒冷的雨天,我不想开车沿风雨交加的山路去我女儿凯洛琳房子去。(词语重叠不当,使用“去……房子”即可)
⑤眼前这情景就像太阳把金子贴在了洒在了山坡上。(词或短语冗余)
⑥在被动和谐的关系中,父母满足于他们的生活,尽管他们过得不是很开心。(词或短语顺序不当)
通过对诊断评价结果的分析和分类研究,可以得到译文中翻译问题的一般特点和规律,对于语言教学而言,这是重要的改进教学的依据,该方向已有大量的研究成果。
在机器翻译评测中有少数研究开始关注此类诊断性评价,以发现机器译文的具体问题。WMT自2013年开始增加了译文词汇错误标注任务。译文词汇级的错误分类主要依据Vilar et al.(2006)的分类框,如图2-2(其中带边框的错误是WMT要求标注的类型)。由于错误识别的正确率太低,2015年WMT又将错误类别简化为good和bad两类。
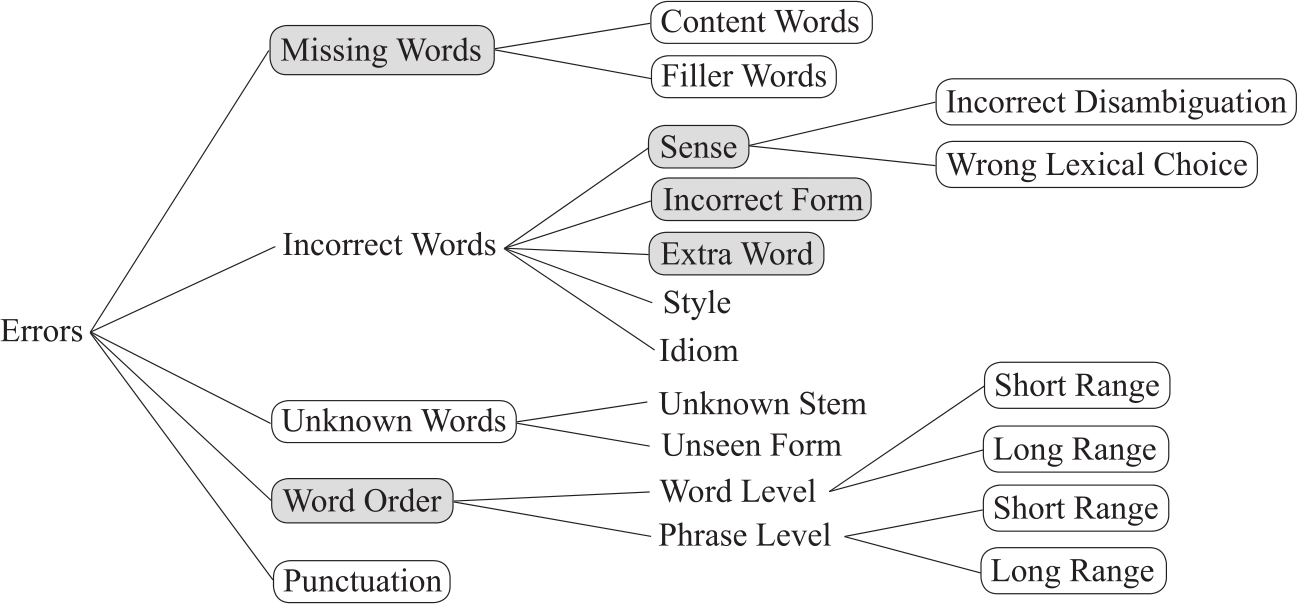
图2-2 机器译文错误分类
俞士汶在评价机器翻译系统时,最早采用的也是诊断评价的思路(Yu,1991)。863机器翻译评测的WoodPecker系统是基于自动提取的关键词类和短语的诊断评价(Zhou et al.,2008)。这是国内对机器译文诊断评价的一些探索。这部分内容将在下一章的自动评测方法中详细展开介绍。
综合来看,诊断评价需要评价人员付出更多的劳动和时间,因为不仅仅要对译文给出一个整体印象分,更要详细标定译文中的问题,再依据问题的多少和严重程度进行评价。实际上,由于同一个原文的译文不具有唯一确定性,针对某一些语言点的译法更可能存在多种观点,甚至可能得到完全相反的观点。为尽量克服质量评价中的主观因素,提高评价的信度,实施诊断性评价一般都要对评价人员进行事先的培训和指导,明确正误等级和评价标准,有时也提供参考答案和各种档次的评价样例,才能得到一致性较好的评价结果。因此,诊断评价的代价相比宏观评价要高很多,争议也更多,但能形成更丰富的翻译分析结果,便于有针对性地提高和改进。