3.2.2 译文质量估计算法
翻译质量自动评估任务是为给定译文一个质量得分,分值为实数时,评估问题就是回归分析问题,当只需要区分译文是“好”还是“坏”时,质量估计也可以视为二分类问题(Wisniewski et al.,2013)。显然,基于回归分析的评估结果可以隐含地进行质量排名,但是反之不可以。质量估计一般为有监督学习,首先在一定数据集上训练预测模型,然后运行测试。也有研究无监督的译文质量估计方法(Moreau & Vogel,2012),节省了训练过程。
机器学习中的有很多分类器,这里不展开介绍。下面重点介绍常用的回归分析算法和无监督的方法实现译文质量的估计。
一、回归分析
目前的研究中,回归分析的算法主要采用的有Ridge Regression,SVR(Supported Vector Regression)和M5P regression tree。
(一)Ridge Regression
Ridge Regression是一种线性回归方法,简单而且训练速度快。它通过最小化残差的平方和来完成参数训练,模型优化的表达式为3-23:
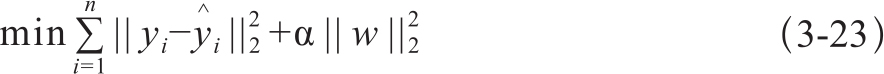
式中,yi表示第i个样本的标注结果,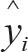 表示估计结果,w为参数向量。α为控制归一化强度的复杂度参数。|| . ||2为欧式范数(Euclidean norm)。
表示估计结果,w为参数向量。α为控制归一化强度的复杂度参数。|| . ||2为欧式范数(Euclidean norm)。
(二)SVR
作为baseline的QuEst++系统就基于支持向量回归(Supported Vector Regression,SVR)构建的,采取了径向基函数(radius basis function)作为核函数。
SVR(Basak et al.,2007)是无参数机器学习模型,可用于监督学习的回归分析。和支持向量机(Support Vector Machine,SVM)用于分类问题的原理类似,只是回归处理是在连续的实数集上的拟合。如果在给定样本集上,存在一个超平面可以拟合一个实数集的标记结果,那么就属于线性回归分析;否则需要利用核函数将线性不可分的样本集映射到一个高维空间中,并且在高维空间中是线性可分的,这样可以进行线性回归分析,之后返回原来空间,从而实现非线性回归。下面简单介绍原理。
给定样本集:S={(xi,yi),xi∈Rn,yi∈R},给定一个ε>0,在Rn空间中如果存在一个超平面f(x)=<w,b>+b,w∈Rn,b∈R,使得|yi-f(xi)|≤ε,∀(xi,yi)∈S成立,那么f(x)=<w,b>+b就是在误差范围内的线性回归。其参数优化问题满足以下约束条件,式3-24:
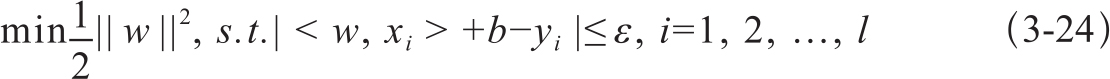
当线性不可分时,引入一个核函数K(s,t)将数据映射到高维空间:K(s,t)=<φ(xi),φ(yi)>,使得特征线性可分。其参数优化的条件是式3-25的解αi,ai*。
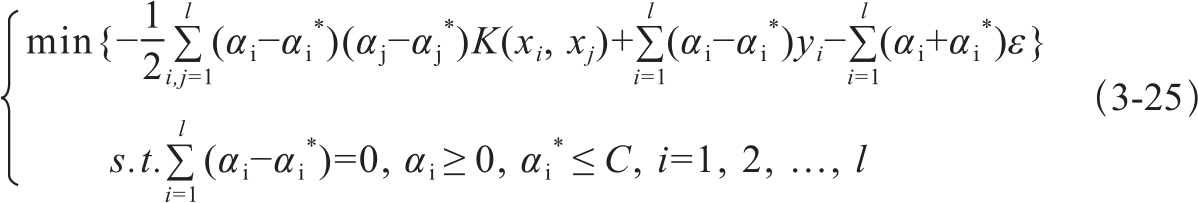
构造的非线性函数形为:
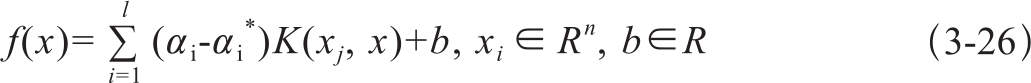
(三)M5P regression tree
回归树属于一种决策树(decision treee),树的非叶子节点为基于某个特征的分类器,这一点和普通的决策树一致,不同的是,回归树的叶子节点是线性回归函数而不是决策的结果。从根节点到叶节点的路径构成一个决策的序列,到叶节点的回归函数时,就能得到一个实数值的预测结果。因此,回归树本质上构成一个函数,在给定输入数据和特征的情况下,输出一个连续值的预测结果。常用的一种算法是M5P。
M5P是对Quinlan的M5算法的重构。Quinlan的M5算法是用于实现回归模型的归纳树,在翻译质量估计任务中取得过最好的成绩。据研究,和SVR相比,M5P回归树在训练过程中不容易出现过拟合问题(overfitting)。
上述各种回归分析的算法实现在scikit-learning8、Weka9和MATLAB等机器学习工具软件包中都有可直接利用的模块,因此这里介绍得比较简略,一般用户可以不必关注学习模型的实现细节,直接根据说明训练自己的评估模型即可。
二、无监督的方法
一定规模的机器译文质量人工标注数据是有监督的学习模型训练的前提,代价较高。为了节省人工成本,Moreau & Vogel(2012)尝试了基于相似度特征的方法估计机器译文的质量。没有人工的质量评分数据,但是不能没有合法的文档作为评测的依据。在他们的研究中,需要准备和译文语种一致的参考语料资源。注意,这里的参考语料并不是原文的人工译文,可以是任何的语料,只要语料具备一定的规模和具备正常语言语法语义的合理性即可,文献中使用了欧盟的数据和Google books。
无监督方法直接比较机器译文和参考语料的n-gram相似性,相似度高的质量排名靠前。研究者指出,这里的相似性不具备绝对比较的意义,只用于翻译质量的排序。主要采用的相似性特征有:
· n-gram:长度从unigram到6-gram
· 标点特征:二值特征,有无标点
· 大小写特征:二值特征,大写或小写的相似
· 句子边界特征:二值特征,句子前面和结尾是否有边界符号
相似度指标主要有两项:(1)计算机器译文和参考语料的余弦相似度,其中译文和参考语料向量表示用了类似TF-IDF的加权方法Okapi BM25(Jones et al.,2000)。(2)多级n-gram匹配的相似度:首先在参考语料中检索较长的n-gram,不匹配时降低一个数值再检索,并且增加一个小于1的惩罚项,这样可避免简单匹配造成二值结果。
在实验数据集上的结果表明,无监督的方法的DeltaAvg得分可以达0.40(关于DeltaAvg指标在第4章介绍),接近有监督的评估方法的0.45的DeltaAvg分值。整体上,无监督的评估结果仍低于有监督的评估方法。