7.2 网页简介文本的质量评价
现代网络搜索引擎架构已十分复杂。搜索引擎通常由多个子系统构成,包括网络爬虫、索引、词汇处理、网页排序、网页文摘、元数据处理等(Turpin et al.,2007),如图7-1所示:
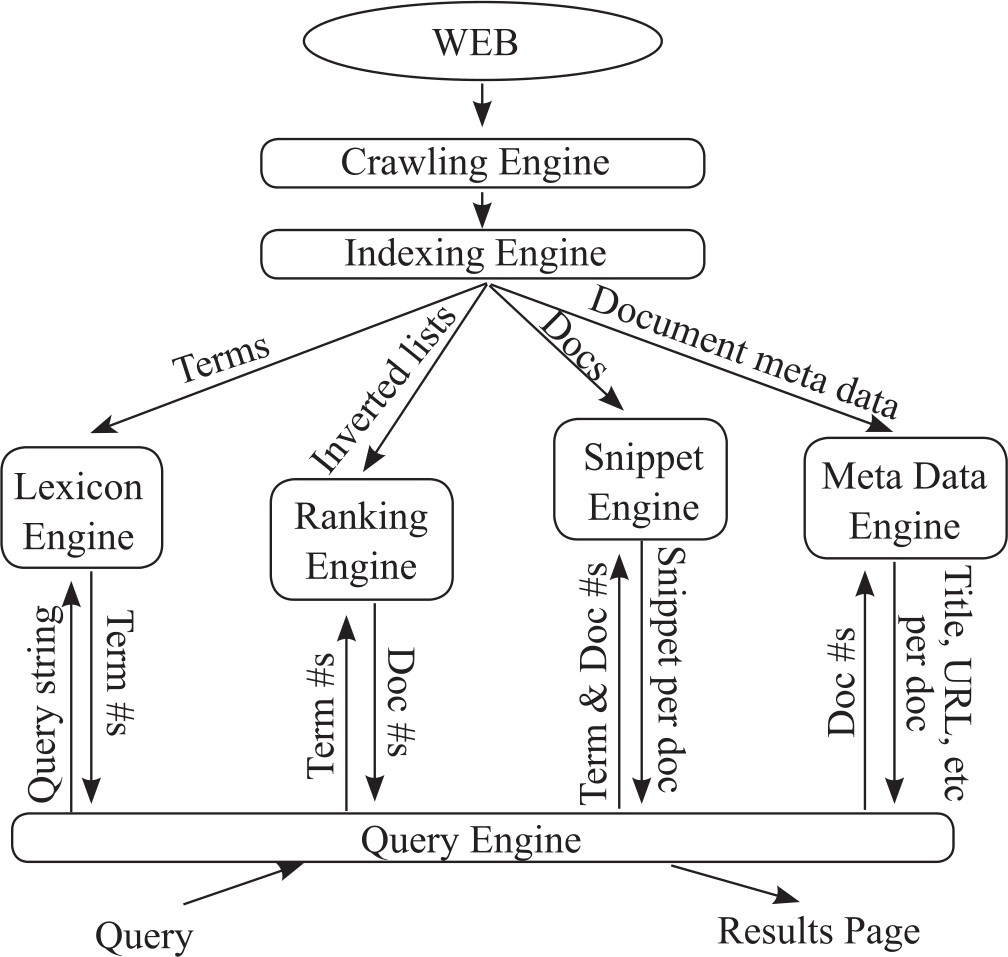
图7-1 现代搜索引擎的架构
搜索引擎中,网页检索返回结果中都包含一段短文本来描述网页的主要内容,称为page snippets。snippet一般自动从网页文档中截取片段,并把用户的检索词突出显示。当然也有人工为网页做摘要的,这种做法实用性不大,代价很高。网页摘要的作用是方便用户判断该网页和检索需求之间的关联性,以便决定是否打开网页浏览。
网页摘要和一般的文本摘要生成有相似之处,也存在很多特殊性:首先,网页上无法预知领域特性,网页内容纷繁复杂,各种内容都涵盖,而一般的文摘可以使用领域的特征;第二点,网页由于动态性和变化性,其内容不便于进行语言预处理,如句法分析等;第三点,网页文摘不便使用有监督的机器学习方式进行训练学习,网页文摘的速度要求很高;最后一点是网页内容的复杂性,有的网页尽管含有文本,但是并不含有连贯性的句子,可能只有些标题和短语,有的网页中含有图片、音频、视频多媒体信息,摘要中也应给予体现,而在普通文本摘要中,这些问题都不存在。
网页文摘中最常见的研究是提取网页中含有关键内容的句子,而这些句子中一般要包含用户检索的关键词。因此简单的生成网页文摘的方式就是从网页中抽取含有关键词的句子,并根据关键词等对这些句子打分并排序,将排在前面的两个或三个句子作为文摘的内容。
影响句子排序的因素很多,除了依据句子在文档中的自然顺序以外,Turpin et al.( 2007)还提出了其他排序的方法,如:
(1)根据词频计算句子的重要程度,一篇文档的词频fd,t的计算考虑到了文档中句子的数目,计算式如下:
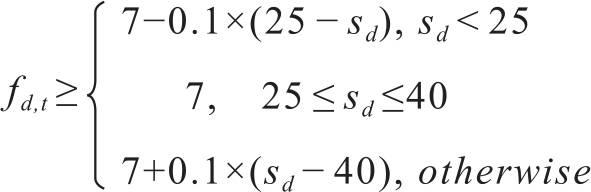
上式中,sd表示文档中句子的数目。当一个词的词频fd,t满足上面的要求时被视为重要的词。一个句子含有重要的词越多,得分越高,排序也靠前。
(2)根据查询日志可以得到热点关键词,热点关键词尽管数目不多,却占据了最大多数的查询。一个句子中含有热点查询词越多,得分越高。当然热点词频数目还需要除以该句子的长度进行归一化处理。在统计热点词频时,可以对多次出现的相同的热点词只计一次,防止某些词因多次重复而影响句子的得分。
把含有主要内容的句子提取出来形成网页文摘的研究相对较成熟,网页文摘的难点是如何形成语义连贯的句子,使得文摘具有较好的可读性,而不是简单地将含有关键词的句子拼凑在一起。理想的网页文摘应该能够在给定检索关键词的条件下,充分且流畅地描述网页文档提供的信息内容,用户以此为参照可以选择是否打开网页进行浏览。Savenkov(2011)研究了几个主要影响网页摘要的信息度和可读性因素,并将其作为自动评价摘要质量的变量,包括(1)通用因素:高亮词的数目、检索关键词在摘要中出现的比例、高亮词的分布密度和方差、高亮词出现在标题中的比例等;(2)网页文摘中的不可读字符的比重,如@、#、^、<、>等符合都是不可读字符;(3)只含有标题的空文摘的数目。依据这些因素对网页文摘自动排序,排序结果与人工排序结果的Kendall τ相关系数如表7-1:
表7-1 网页自动文摘与人工文摘相关度有关的变量
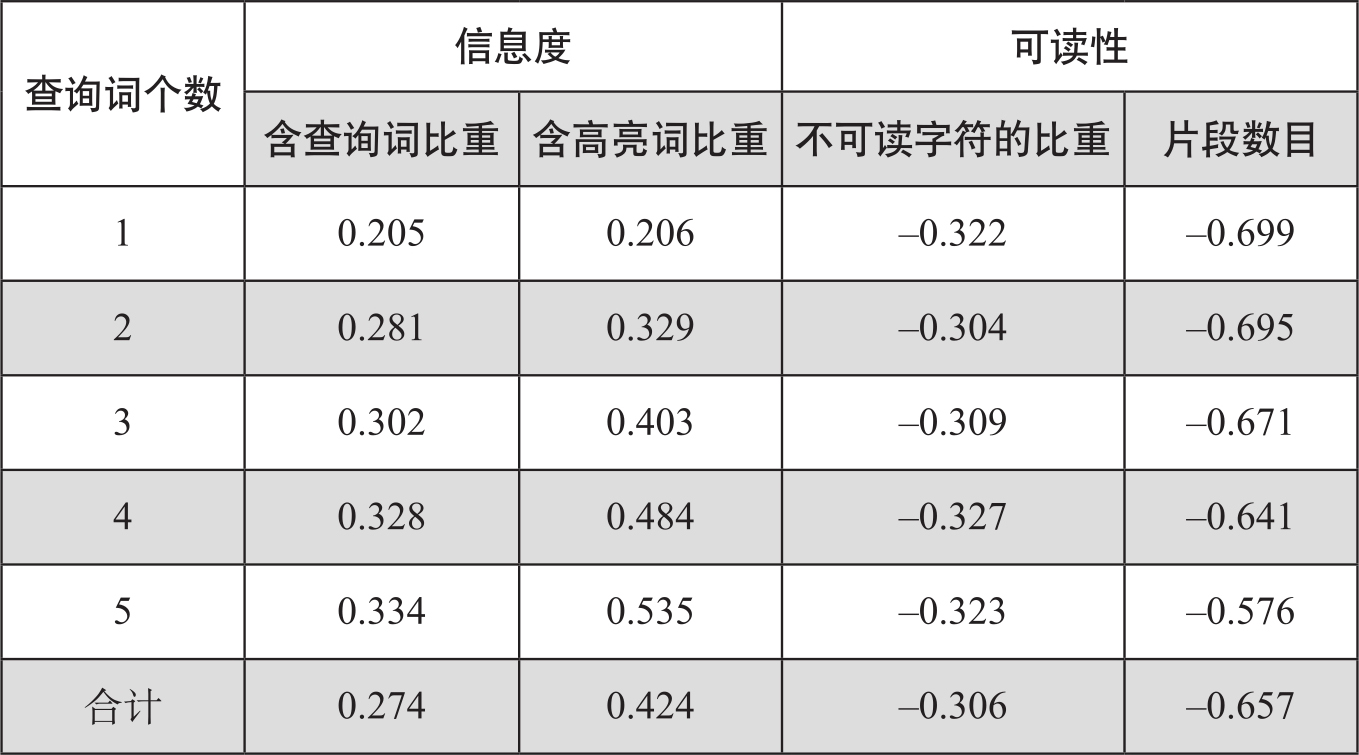
表中数据表明,查询词和高亮词与文摘的信息度正相关,而原文档中的非句子的片段和不可读的字符在文摘中出现越多,越影响文摘的可读性。针对网页文摘质量的评价很少。网页摘要和信息检索的准确率密切相关,人们往往根据网页文摘判断检索的网页是否满足要求。Savenkov(2011)的文献中提及的评价网页文摘质量的一些变量可为自动译文评价提供一些启发。