3.1.4 译后编辑率
机器译文目前在一定程度上可用,或部分译文可直接采用,还有一部分需要人工修改后可用。这样,译后编辑率就成为衡量机器译文质量的一个指标。通过计算对译文进行后期编辑要付出的工作量大小来间接反映译文的质量。译后编辑率越低,译文质量越高,否则就越低。译后编辑评价方式有两个常见的计算指标:一是时间,即将一个译文修改为可接纳的正确译文所付出的时长,时间越长说明译文质量越差。时间指标与编辑人员有关,不便于掌握;二是翻译编辑率,也是通常所说的译后编辑率。
一、TER
翻译编辑率(Translation Edit Rate,TER)是2006年Snover等人提出的一种自动评测译文质量的方法,指的是将一篇机器译文人工修改为可接受的译文需要做的最少编辑次数,包括插入、删除、替换、调整次序等的总次数。这里并不对编辑的内容予以区分,不同的编辑操作视为等价操作,每做一次编辑操作计1,不设置编辑的权重。调整次序时可以是多个连续的词一起调整,一次调整操作也计1,不管调整块包含的词数。标点符号的编辑也计算在内,单词大小写的编辑也计1次。TER的计算如式3-6:
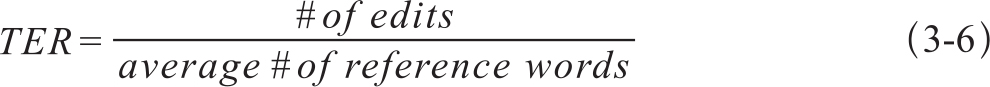
TER和前面介绍的WER的差别在于,TER的编辑操作包括了次序调整,WER则不包括。可以通过下面的例子来进一步熟悉TER的计算方法。机器译句和参考译句如下。
机器译句:
THIS WEEK THE SAUDIS denied information published in the new york times
参考译句:
SAUDI ARABIA denied THIS WEEK information published in the AMERICAN new york times
将机器译文修改为参考译文需要的编辑操作包括:1次插入、2次替换、1次调序。参考译文包括13个词,因此可以得到TER的值为4/13。
TER算法只能基于单篇参考译文进行评价,如有多篇参考译文也只能多次重复执行两两比较算法,不能综合利用多篇参考译文。和WER相比,TER增加了调整语序的编辑操作,要调整顺序的词或词组可通过穷尽式搜索得到,同时也有对调整内容的一些约束条件。
但是最优求解编辑距离也是个NP-完备问题。Snover(2006)提出的基于完全匹配的编辑距离近似求解方法大致包括两步:首先利用动态规划算法计算插入、删除和替换的次数,然后再用贪婪匹配的思想求调整的次数,重复所有可能的调整方法,如果某种调整将减少插入、删除和替换的次数,就保留本次调整,直到尝试所有的调整方法,使得调整后没有使得编辑次数降低为止。算法实现的伪代码如下:

通过译文之间的编辑距离来衡量翻译质量的方法可以部分克服n-gram匹配对匹配长度的限制,但仍然很机械,不能真正反映译文之间的语义关系。
二、HTER
人工干预的翻译编辑率(Human-mediated TER,HTER)被认为是比人工评价译文的流利度和准确度一致性更好、粒度更细的指标(Snover et al.,2009b)。HTER是一种半自动的、需要人工参与的评价方法,即人工将机器译文修改后得到一个和机器译文最接近的、符合原文含义的、合理流畅的译文需要的步骤,并不对机器译文进行直接的评分。编辑同样包括插入、删除、替换和移动四种操作。这里编辑时没有标准译文可以参照。
HTER的计算方法是以最少的编辑步数除以可接受译文的单词的数目。根据HTER可以统计出机器译文的错误情况,但是HTER中每一次修改都是等价的,也就是不区分修改的内容是缺失了主语,还是缺失一个冠词或其他。人工修改后形成的这个译文能够作为BLEU、NIST、TER等算法评测中需要的参考译文使用。可见,这个评价方式比评价准确度和流利度付出的时间更多,代价更大。
HTER目前作为美国国防高级研究计划局(Defense Advanced Research Projects Agency,DARPA)中GALE(Global Autonomous Language Exploitation)项目的官方评测指标。WMT在MTurk平台上也尝试译后编辑的众包方式,将一个机器译文通过最少的编辑修改步骤,使之成为和人工译文意义相同的合理译文。HTER也是计算机辅助翻译(Computer Aided translation,CAT)所使用的指标,用来衡量机器翻译多大程度上能替代人工翻译工作。同时,人工对机器译文的编辑修改能够生成两个十分有价值的集合,一个是正确译文的集合,另一个是机器译文错误的集合,从而能进一步促进机器翻译的研究和自动评测工作。
三、TER-Plus
TER-Plus是对TER的扩展(Snover et al.,2009a),简写为TERp,它将构词法、同义词和重述(paraphrase)等加入到TER的计算中,不同类型错误的评价代价设置为可调整的,根据TERp的值能对人工判断之间的差异给出解释。
在对齐待评译文和参考译文过程中,不仅使用严格匹配的方法,还考虑了是否具有相同的词根或是否为同义词、近义词等因素,并利用基于概率的短语对齐方法。概率值的运用使得编辑的代价不再是常数,而是和人工判断相关度最大化的一种优化参数。所以,TERp除了一般的编辑操作如插入、删除、替换和调整之外,还增加了词根匹配、同义匹配和短语置换等操作。词根匹配是对单词进行还原(stemming)后再匹配,同义匹配则利用了外部资源Wordnet来判断是否为同义词,短语置换是依据一个事先建好的短语对应表来判断能否进行互换。
单词匹配、词根匹配和同义匹配的编辑代价都为0,插入、删除、替换和短语置换的编辑代价需要基于训练语料而定,最终确定的这些编辑代价能够使得算法与人工判断的相关度最大化。除了短语置换之外,其他编辑的代价都为正数,且对任何词汇都相同。短语置换的编辑代价是两个短语成为重述短语的概率以及编辑代价(不含短语置换的代价)的函数。设两个短语为p1、p2,其短语置换的编辑代价函数为:
cost(p1,p2)=w1+edit(p1,p2)*(w2)log(Pr(p1,p2))+w3(Pr(p1,p2)+w4)
式中w1、w2、w3、w4是可变的参数,edit(p1,p2)是对齐p1、p2的编辑代价,也就是p1变为p2需要进行的除短语置换外的所有编辑代价。Pr(p1,p2)是根据短语对应表p1、p2构成重述关系的概率。该表借助一个双语语料,利用枢轴原理(pivot-based)计算出单一语言中的短语重述关系。这里不再具体介绍这个短语对应表的提取方法,只介绍一些结论。
根据Snover et al.(2009a)在NIST的MTEval 2006阿拉伯语到英语的翻译数据集上对TERp中11个参数的优化结果,得到如表3-2所示的各种编辑代价参数:
表3-2 TERp中的编辑代价

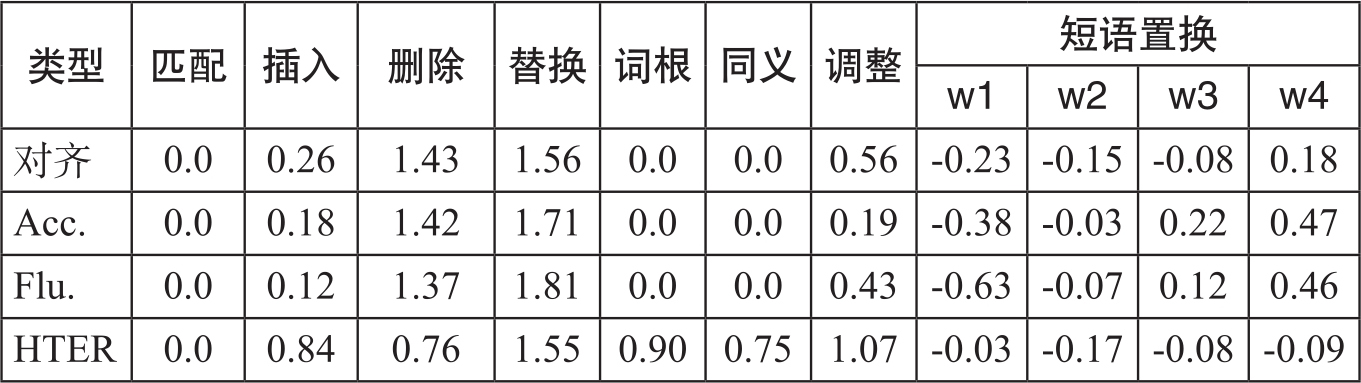
研究还对应人工评判的不同类型优化了TERp的参数。人工评判类型包括译文的准确度Acc、流利度Flu、对齐率和HTER得分等。这里一并列出在表3-3中,供读者参考利用。目前TERp已成为机器翻译评测中一种重要的自动评测方式,其代码也是开源的,下载地址:http://www.umiacs.umd.edu/_snover/terp/
表3-3 不同类型的TERp中的编辑代价
上述都属于译后编辑率评价译文质量的方法。译后编辑时可以为编辑人员提供参考答案,也可以仅仅参照原文进行编辑。研究结果表明,有参考译文的译后编辑评价的一致性优于没有参考译文的一致性(Cettolo et al.,2015),但也容易受参考译文的影响,偏向和参考译文一致的译法。