3.1.3 基于词汇错误率的评价
检查待评译文的错误率也是评价其翻译质量的方法之一。常用的错误率主要包括词汇错误率(Word Error Rate,WER)、位置无关错误率(Positionindependent Error Rate,PER)和翻译错误率(Translation Error Rate,TER)。根据错误匹配的数目作为评测译文质量优劣的依据。三种方法略有不同,下面分别介绍。
一、WER
词汇错误率WER(Nieβen et al.,2000)最早提出来时主要用于自动语音识别任务,计算方法是求测试文档和参考答案之间的基于词汇的莱文斯坦距离(Levenshtein distance),也就是编辑距离(edit distance)。编辑距离表示将测试文档变为参考文档时需要进行的修改次数,次数越多,说明两个文档之间的差距越大。在语音识别中,不同的词就意味着识别错误,词汇错误率和识别的准确率成反比。注意这里的编辑操作仅包括:词汇的插入、删除和替换三种,不包括调整次序的操作。每进行一次操作都计1,汇总所有编辑总次数edits,并用参考文档的句子长度refer_len归一化,就得到词汇错误率,如式3-3:

在WER中,如果遇到词序不同时,只能先进行删除操作,然后插入词序不匹配的单词。WER用于译文质量评价时,就是衡量待评译文和参考译文的编辑距离。尽管和参考译文不同的词并不代表就是翻译错误,但WER还是可以在一定程度上反映出译文之间的差异,用1减去编辑距离就可以作为译文的质量得分,如式3-4所示。
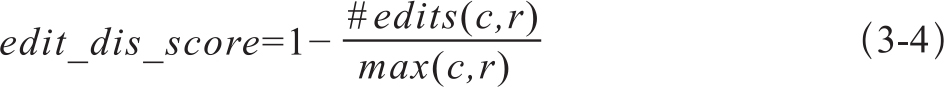
其中c、r分别表示待评译文和参考译文的长度。通常的比较都是两两比较,如果有多个参考译文,可以将与不同参考译文的编辑距离的平均值或者最小值作为待评译文的最终得分。
二、PER
位置无关错误率PER的计算方法是,统计待评译文和参考译文相同的词,但不考虑词出现的位置,只要在参考译文中出现就认为是正确的匹配,每正确匹配一个词计1;然后用1减去正确匹配的次数比例。计算公式如式3-5:
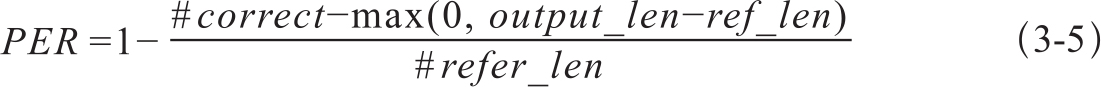
下面用一个例子说明WER和PER的计算方法。已知参考译文和两句系统译文:
参考译文:Israel officials are responsible for airport security.
系统A译文:Israeli officials responsibility of airport safety.
系统B译文:airport security Israeli officials are responsible.
根据公式,系统A译文和参考译文只有3个词是匹配的,系统B译文和参考译文所有词都匹配,但词序不同。可以得出,系统A和B的PER和WER值如表3-1。
表3-1 例句的WER和PER的得分

翻译错误率TER是对WER和PER的改进,关于TER和TER的改进版TER-Plus,将在下一节译后编辑率中介绍。