6.1 机器翻译错误语料库
机器翻译错误语料对研究机器翻译和翻译质量自动评价有着重要的意义,尤其是标注了错误和翻译质量的数据,是有监督机器学习模型训练的基础。但是标注翻译错误需要付出大量时间和劳动,因此目前构建的机器翻译错误语料库的规模都比较小。我们将目前公布的部分机器翻译错误标注语料汇总在下面的表6-1中。
表6-1 机器翻译错误标注语料库
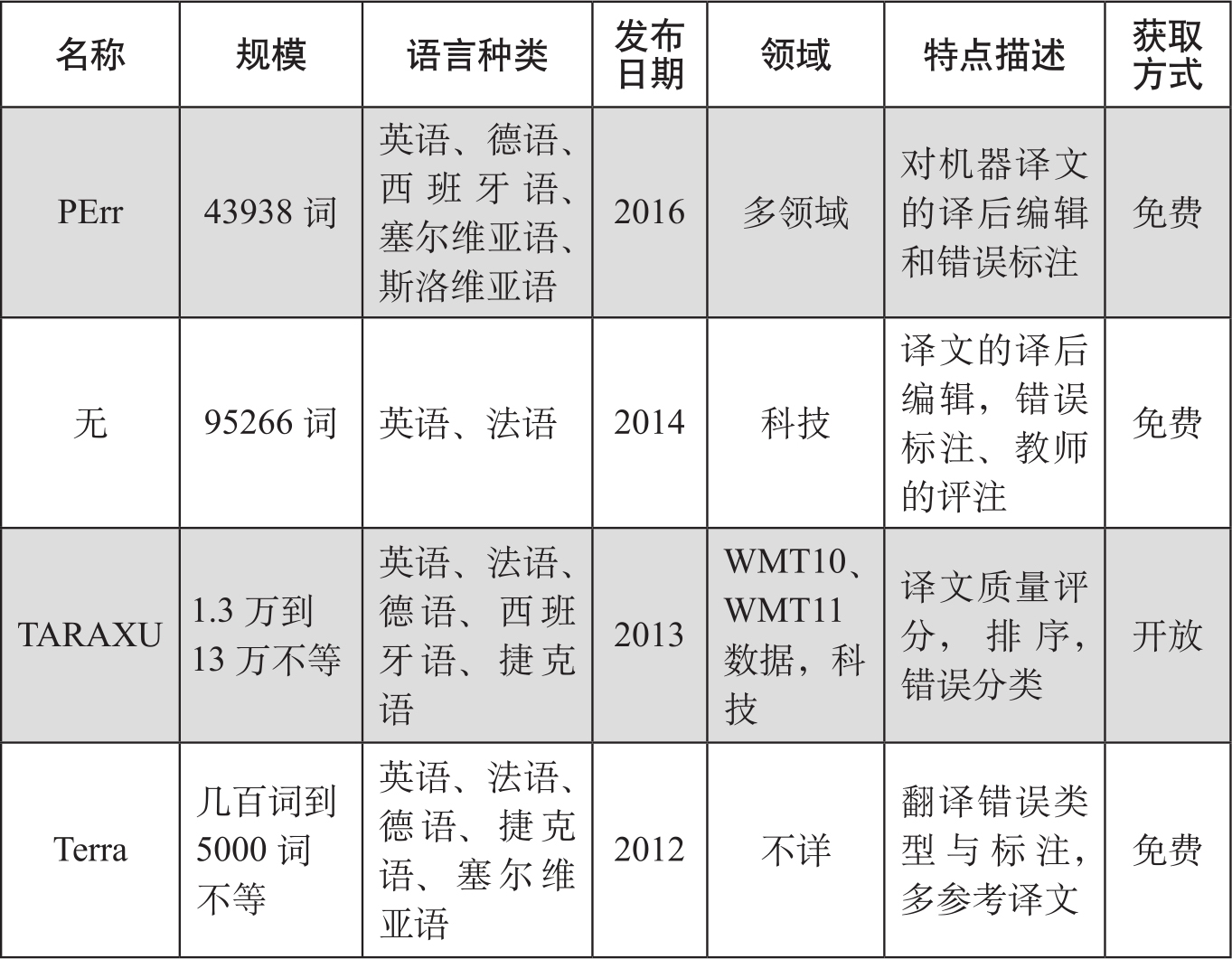
还有很多小规模、涉及个别语种的翻译语料,这里不一一列举。表中的几个语料库具体说明如下。
PErr语料库是欧盟的一个项目(Popović & Arcan,2016),原文的数据来自不同的领域,共有2896个单元、43938词,涉及英语、德语、西班牙语、塞尔维亚语、斯洛维尼亚语五种语言,标注了翻译错误且人工进行了编辑,有相应的正确的译文。读者根据要求填写相应文档后,可免费获取语料,语料的网址为http://nlp.insight-centre.org/research/resources/pe2rr/。
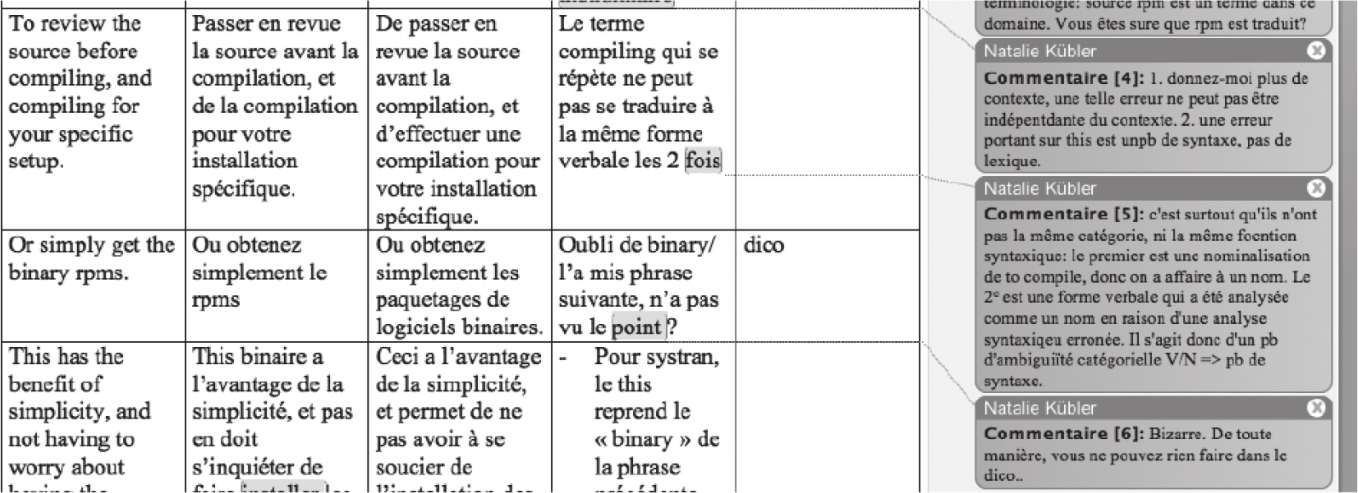
第二个语料由Wisniewskietal et al.(2013)构建。原文来自语言专业学生翻译的练习作业,主要为科技论文、技术文档、维基百科中的文档等。库中包括原文、机器译文(由基于规则的翻译系统翻译)、学生对机器译文的译后编辑、教师对错误的更正和详细分析等。语料规模不大,共4854个原文句子,95266个单词。语料可以免费下载,地址为http://perso.limsi.fr/Individu/wisniews/ressources。下面是该语料的部分样例:从左到右各栏分别是原文、机器译文、译后编辑、错误描述,最右侧为教师的标注。
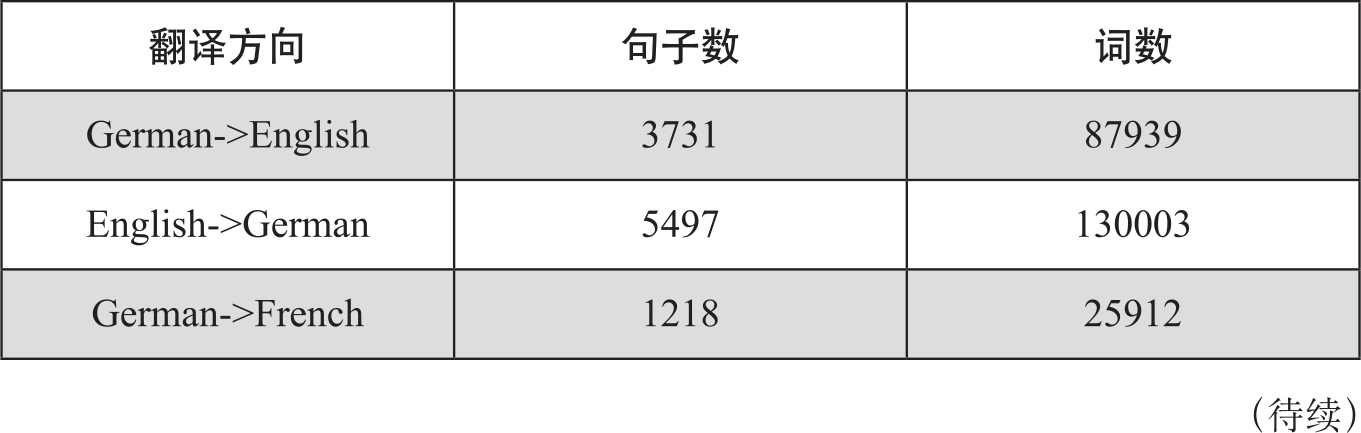
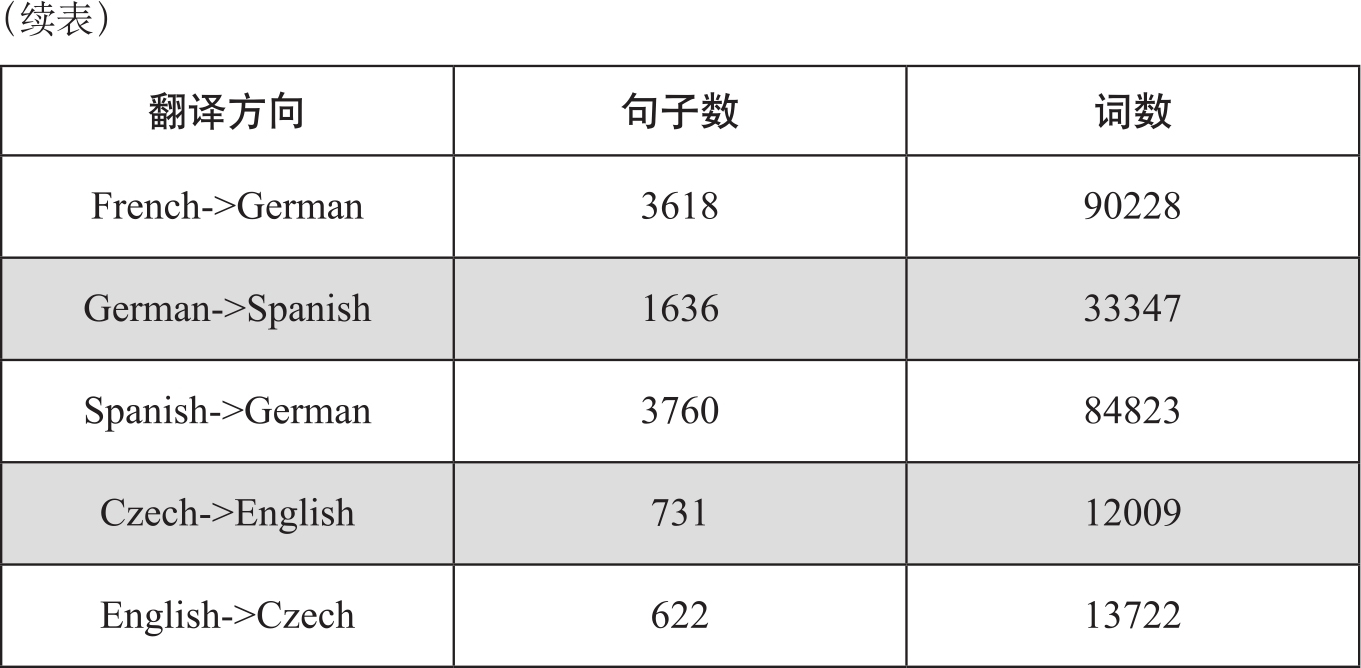
TARAXU语料库涉及多个语种和翻译方向(Avramidis et al.,2014),表6-2中给出了各个方向数据收集的规模。机器翻译系统用了六个不同翻译原理的系统,包括基于统计的翻译(如Google translator)、基于规则的翻译系统(如LUCY)、基于记忆的翻译系统(如Trados)等。对机器译文标注了质量得分和质量排序结果,从粗、细两个粒度标注了译文词汇的错误。语料库也是开放的。
表6-2 TARAXU语料库的翻译统计数据
Fishel et al.(2012)构建的带有错误标注的机器翻译语料集Terra,包括英语、法语、德语、捷克语、塞尔维亚语五种语言机器译文及错误标注,是研究机器译文错误常用的实例集。其错误分类方法根据Vilar et al.(2006)的方案制定。虽然语料规模也较小,一般只有几百个句子,几千个单词,如英语到捷克语的原文有200个句子,法语到德语的原文有252个句子,由于涉及多个语种,还是很难得的。该语料库同样可以免费下载,下载地址为http://terra.cl.uzh.ch。