3.1.6 基于依存元组的相似度
n-gram一般指句子中连续n个词构成的序列。基于n-gram匹配的方法并不能真正从语义层面反映出待评译文与参考译文的相似度,而且包含了大量无明确语义的元组,像are one of the,to a等由功能词构成的序列。合理译文往往在用词、结构等方面存在丰富的变化,因此由连续单词构成的n-gram方法面临严重的数据稀疏(data sparseness)问题。为进一步从较深层面作比较,一些研究探索了待评译文和参考译文在词汇功能语法(LFG)、句法(syntactic)、成分分析(constituent parsing)和依存关系(dependency relation)等层面的相似(Owczarzak et al.,2007;Ye et al.,2007;Liu & Gildea,2005),从较深层面挖掘译文之间的相似性。
值得注意的是,机器译文往往是不完美译文,在句子结构、词汇选择和语序等诸多方面可能存在问题,甚至可能包含没有译出的原文的部分内容。上述研究都运用了目前尚不成熟的句法分析器(syntactic parser)处理待评译文,因此获得的句法分析结果中存在很多错误,也就是说,较深层的语言分析反而给自动评价任务引入了严重的噪声,甚至无法实现待评译文和参考译文在句法层面的比较。这也是目前深层预处理后自动评价性能提升并不显著的主要原因。
心理语言学通过眼动仪研究人阅读时对每一个词汇的注视时间(gaze duration),结果表明,人在阅读时并不是等同地关注句子中每一个词,而是对主题词和低频出现的词更加关注。类似地,每一个词也不是同等程度地影响人对译文质量的判断。可以设想,如果一个机器译文能够涵盖反映句子语义的核心内容,将有助于人对整个译句的理解,从而也将获得比较高的人工评分。基于心理语言学的结论,我们认为,译文质量自动评价时可以只依据句子中包含核心语义的元组,这样不仅可以更有利于抓住重点,还大大降低了对无意义元组的处理。我们认为关键元组是利用依存关系分析参考译文得到的合理译文中相互依存的词汇或短语(下文称之为依存元组〈dependency n-grams〉)。近年来Google就基于句法分析构建并开放了句法元组(syntactic n-grams)资源,作为机器学习特征应用到自然语言处理任务中,并取得了很好的效果。
基于依存元组的评测方法和已有研究的不同在于:依存分析只针对参考译文进行,而不分析待评译文;依存元组可以进行变形和扩展,作为译文质量评价的关键点;根据待评译文中包含依存元组数目的累加和来判断译文质量,并将待评译文的长度和依存元组的最高发生次数等因素融入到最终得分计算公式中。
一、依存分析
依存语法认为,一个句子的基本单位之间以各种关系相互依存,共同形成一个结构体,一般动词是句子的核心。是否存在依存关系并不以词的相邻和次序为依据。依存关系由头词(head)和依存(dependent)两部分构成。我们利用了斯坦福大学公开的依存分析工具CoreNLP2,该工具可分析出50种语法依存关系,如论元依存关系有nsubj(名词主语)、csubj(从句主语)、dobj(直接宾语)、iobj(间接宾语)、pobj(介词的宾语)等,修饰依存关系有tmod(时间修饰)、appos(同位修饰)、det(限定词修饰)、prep(介词修饰)等。依存关系分析的优势有两点:一是能够根据一个词很好地预测和它依存的词,二是适合处理那些词序相对灵活的语言。
例如对句(2):
(2)Executive Committee of FIFA also announced some reform measures.
依存关系分析后的线性结果为:
[['root', 'ROOT-0', 'announced-6'],['nn', 'Committee-2', 'Executive-1'],['nsubj', 'announced-6', 'Committee-2'],['prep_of', 'Committee-2', 'FIFA-4'],['advmod', 'announced-6', 'also-5'],['det', 'measures-9', 'some-7'],['nn', 'measures-9', 'reform-8'],['dobj', 'announced-6', 'measures-9']]。
把线性分析结果转换为图形结构,如图3-3所示:
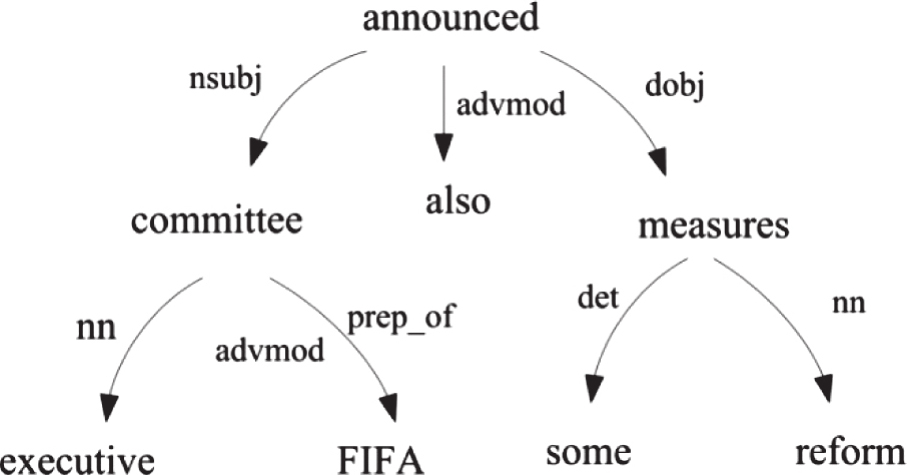
图3-3 句(2)的依存关系分析结果
依存分析已被一些研究应用到译文质量评价中。通常对参考译文和机器译文分别进行依存分析,再比较二者的相似。第一种方法是,比较核心词构成的词是否相似,即以每一个依存关系的头词起始的二元组。比如,根据这种方法,句(2)中提取的核心词链有:announced committee,announced measures,announced also,committee executive等。核心词链反映了具有依存关系的词链,但核心词链并不一定符合译文的语序。如果待评译文没有相同的分析结果就不计分。除了依存词链,Ye et al.(2007)还进一步比较了依存关系的类型,他们研究了5种类型的依存关系。Owczarzak et al.(2007)还尝试了第三种方法,即通过词汇功能语法LFG来获得依存关系三元组(关系类型、关系词1、关系词2)。上述研究尽管在一定程度上提升了评价性能,但并不十分显著。下面我们以一个具体的例子简要解释原因。例句来自实验数据集,我们找到和句(2)的原文对应的一个待评译句(2'):
(2')The international institutions federal executive committee also announced a number of reform measures.
用相同的依存关系分析工具分析后得到的依存关系如图3-4:
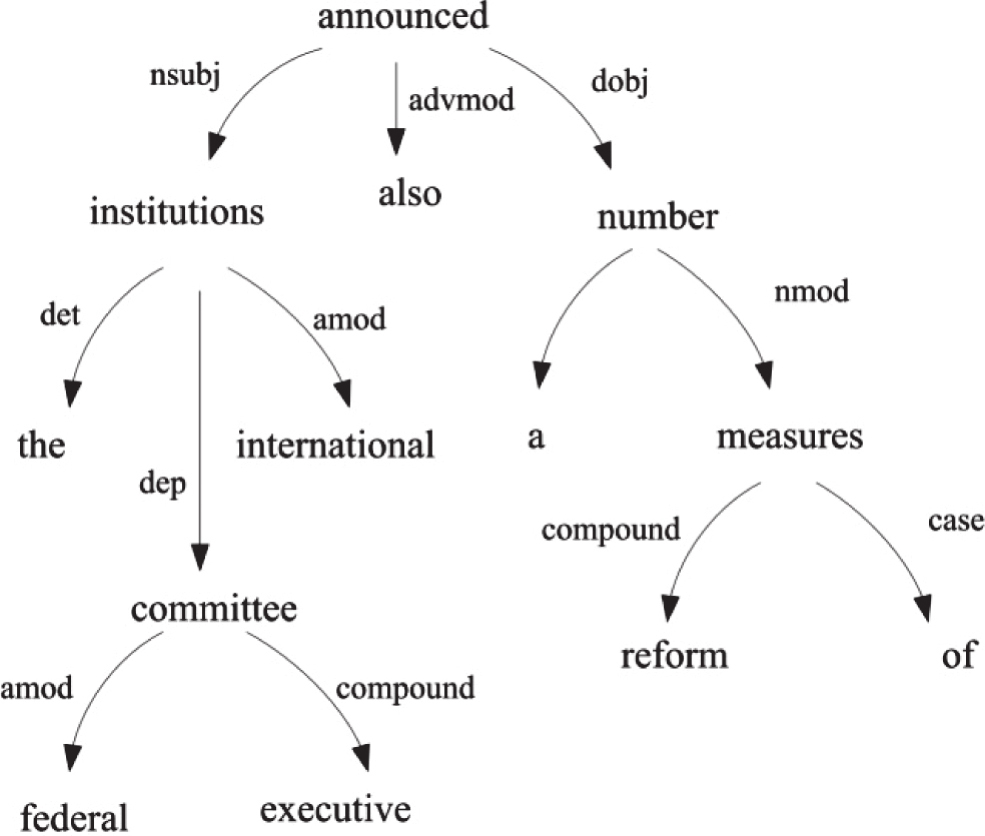
图3-4 句(2')的依存关系分析结果
句法分析器对该机器译文的依存分析结果和人工译文句(2)的结果大相径庭,二者能够匹配的依存关系类型和依存词链很少,可见,依据类型和词链匹配的数目对该译文的评价结果和译文的真实质量并不符合。尽管我们希望通过对待评译文和参考译文进行较深层的语言分析来获得更接近语义相似的比较,但问题是,目前依存分析器的性能还不成熟,尤其是对存在错误的、甚至含有乱码的机器译文的分析结果更差,造成大量噪声的引入,严重影响了评价性能。另外,依存词链在实际语言中并不是由连续词构成,依然采取传统n-gram机械匹配的方法缺乏灵活性,失去了其优势。
二、依存元组
我们仅对合理的参考译句进行依存分析并提取包含核心语义的依存元组。依存元组是具有依存关系的单词构成的元组,元组中单词的语序和原文一致。为了区分元组单词连续还是不连续,我们用…连接不连续出现的依存词。例如从句(2)提取的依存元组有:
announced,Executive Committee,Committee … announced,Committee … FIFA,also announced,some … measures,reform measures,announced … measures
虽然依存关系是二元关系,但依存元组和传统的二元组不同。首先,依存关系的单元不仅可以是单词,还包括短语和多词表达(MWE),因此依存元组可能由2个以上单词构成。
其次,依存元组的单词在句子的位置不要求连续,中间允许有多个单词,可反映长距离相依关系。如some…measures就可以匹配some reform measures和some improvement measures等多种可能的译法。基于依存元组的匹配模式较灵活宽松。
再者,依存元组来自依存分析结果,是和译文意义更相关的关键点,可避免传统n-gram引入的大量无意义的元组,更有助于抓住句子的核心内容。
另外,便于对依存元组进行有意义的扩展。例如,依存分析中介词of构成的短语结构,如句(2)的[‘prep_of’,‘Committee-2’,‘FIFA-4’],根据语言规则,Committee of FIFA还可以变为名词定语形式FIFA committee。我们初步研究了基于语言规则的扩展方法。除了of短语结构外,其他扩展规则有:
· 并列关系中删去连词:如big and honest -> big … honest
· 并列关系中交换词序:如ski or snowboard -> snowboard … ski
· 带有限定词的名词短语删去或修改限定词:如the man -> man, a man
· 被动和主动关系:如defeated -> was defeated
可见,这样扩展出的n-gram是有意义的,有利于捕捉到更多合理的翻译表达方式。
三、基于依存元组的评价方法
基于依存元组评价译文质量的步骤是:首先对参考译文进行依存分析,从中提取初始依存元组,进行词形还原和扩展后得到用于质量评价的依存元组,构建匹配模式,再根据待评译文中共现的依存元组的数目计算召回率(Rec)和准确率(Pre)等指标。上例中针对句(2)扩展后的依存元组共16个,而机器译句(2')匹配了12个依存元组,召回率为12/16。准确率以匹配的词数为单位计算,为6/13。对句(2)的两个人工评分分别为3分和4分(满分5分),同依存元组方法评价结果十分接近。而BLEU算法由于有大量无关元组没有匹配造成得分很低。如果同时对机器译文也进行依存分析,那么除了根节点和参考译文相似外,其他主要依存关系都没有匹配上,因此依据依存关系的类型和词链的匹配的方法也将大打折扣。
考虑到译文长度对译文质量的影响,在计算得分时我们也增加了对过短译文的罚项;考虑到元组在参考译文中的最高出现次数,统计匹配数目时也采取了钳位数的做法,即匹配依存元组的最高数目不超过该元组在所有参考译文中出现的最高次数,这两点和BLEU算法相似。综合起来,基于依存元组的译文得分计算方法如式3-12:
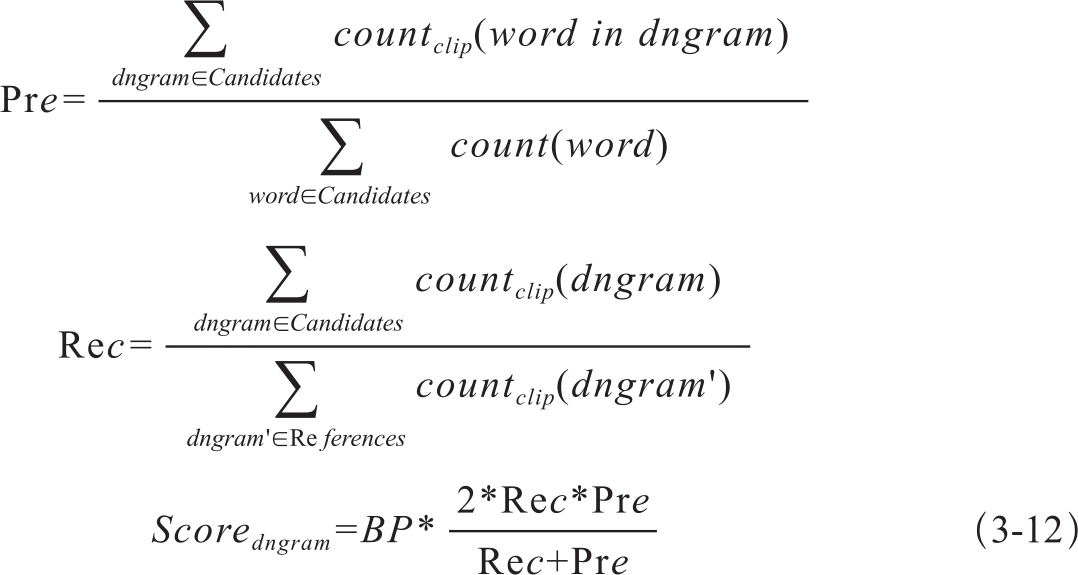
其中BP同式BLEU中BP的计算方法式(3-1)。
四、实验结果
由于代价昂贵,带有人工评分的机器译文集很少,因此本实验只选取了两个LDC公开的汉译英评测数据集进行:MTC-P2(LDC2003T17)和MTC-P4(LDC2006T04)。每个数据集各包括100篇原文,每篇原文有4篇人工参考译文,共1797个句子。两个数据集共9个机器译文:P2-E05、P2-E09、P2-E14、P4-E09、P4-E11、P4-E12、P4-E14、P4-E15和P4-E22,每个系统译句有2-3个人工评分,评分从流利度(Flu)和准确度(Acc)进行,分为1-5五个等级。实验中将人工评分取平均值后作为每一个译句的标准得分。但是数据集中人工评分之间的一致性并不好,这更增加了自动评价的难度。
首先利用CoreNLP对参考译文进行离线依存分析。基于依存分析提取和统计依存元组,再根据依存关系和语言规则对依存元组进行扩展,构建匹配模式。然后输入待评译文,统计宽松匹配的依存元组的匹配数目,结合长度罚项和元组的钳位数根据式(3-12)计算译文得分。
(一)基于依存元组的评价
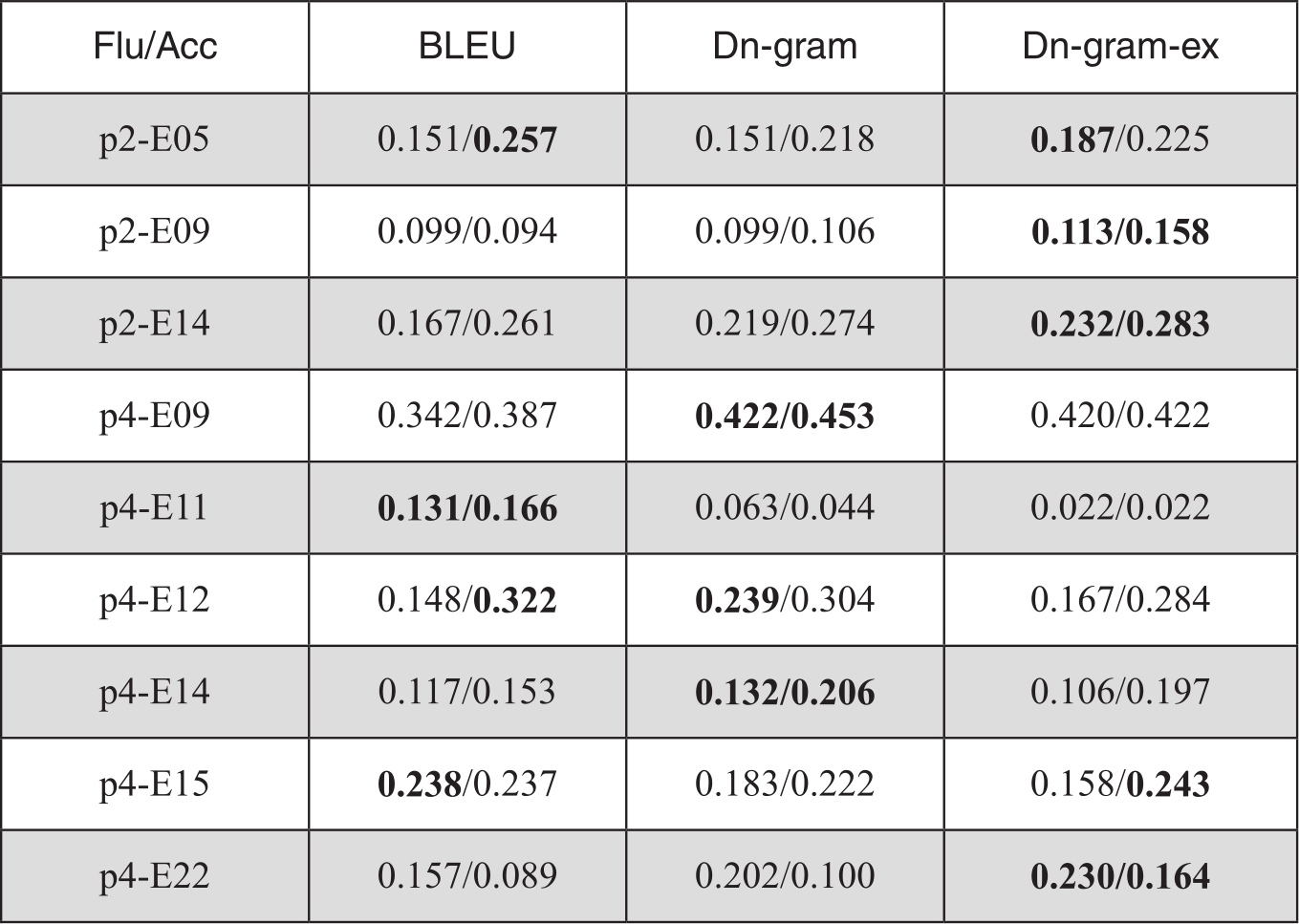
实验从三个层面即系统级、文档级和句子级进行。计算基于依存元组的评分Dn-gram(Dn-gram-ex表示扩展依存元组)和人工评分的Pearson相关度。BLEU和NIST得分由WMT公开的评测工具得到3。系统级评分和人工评分的相关度如表3-4.
表3-4 系统级评价的性能
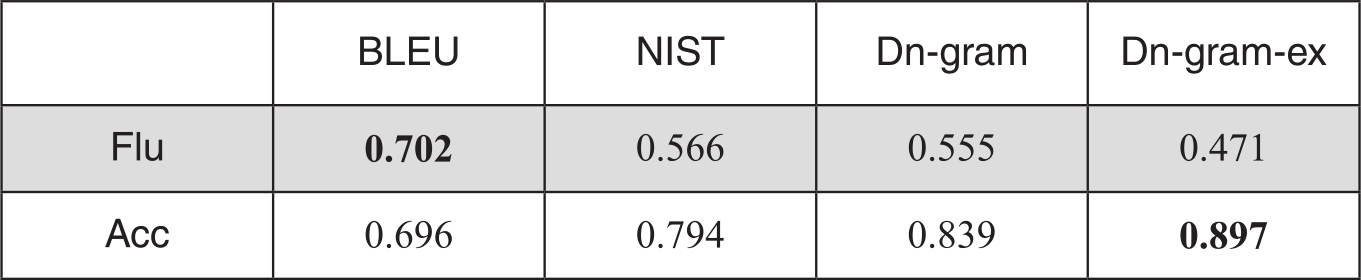
Dn-gram和Dn-gram-ex得分在准确度评价上均显著优于两个基准指标,比BLEU高出28.5%,比NIST高出12.6%。在流利度评价上,Dn-gram和NIST相当,但明显低于BLEU算法。原因是,Dn-gram评价中元组数目远远低于传统n-gram。BLEU和NIST算法中的n取值为4,而Dn-gram中很多是由两个词构成的元组。在系统级评价时数据稀疏问题不算严重,待评译文中连续多个词与参考译文共现时更容易反映流利度指标,因而BLEU和NIST的流利度评价较好。Dn-gram和Dn-gram-ex则更注重了核心语义内容的转换,宽松的匹配模式降低了译文流利度的评价性能。
文档级的评价结果如表3-5。结果说明文档一级Dn-gram和Dn-gram-ex在对9个系统900篇文档的评价中优势依然明显。
表3-5 文档级的评价性能
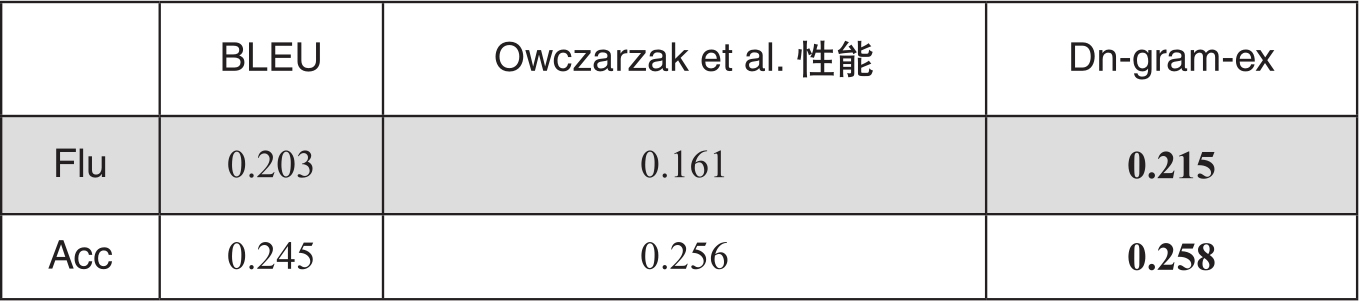
同系统级和文档级相比,句子级的评价相关度最低。对1797个句子评价的平均性能,Dn-gram-ex仍显著优于BLEU算法。Owczarzak et al.(2007)利用依存分析方法在相同数据集也进行了实验,我们将基于依存元组的方法和他们的研究进行了对比,结果表明Dn-gram-ex在准确度和流利度评价上都具有的优势,如在表3-6中,由于BLEU在句子级评价中的数据稀疏非常严重,Dn-gram-ex方法在句子级流利度的评价上反而超过了BLEU。
表3-6 句子级的评价性能
(二)参考译文数目的影响
从有限数目的参考译文中提取依存元组来评价一个译文的质量,数据稀疏问题难以避免。实验中参考译文有4篇。为此,我们在实验数据上分析了参考译文数目对依存元组评价方法的影响;分别考察了参考译文数目为1-4篇时,基于依存元组评价方法的性能变化。参考译文数目小于4篇时采用了交叉验证的方法,取平均相关度值。图3-5反映了文档级评价性能随参考译文数目的变化情况。由图可见,参考译文数目对评价译文的准确率影响很小,对流利度评价方面影响也不显著。说明增大参考译文数目,并不会明显提高对译文质量的判断,基于一篇参考译文和基于多篇参考译文的依存元组评价性能相当,依存元组评价方法对参考译文的数目不敏感,这一点和Doddington(2002)的研究结论类似。
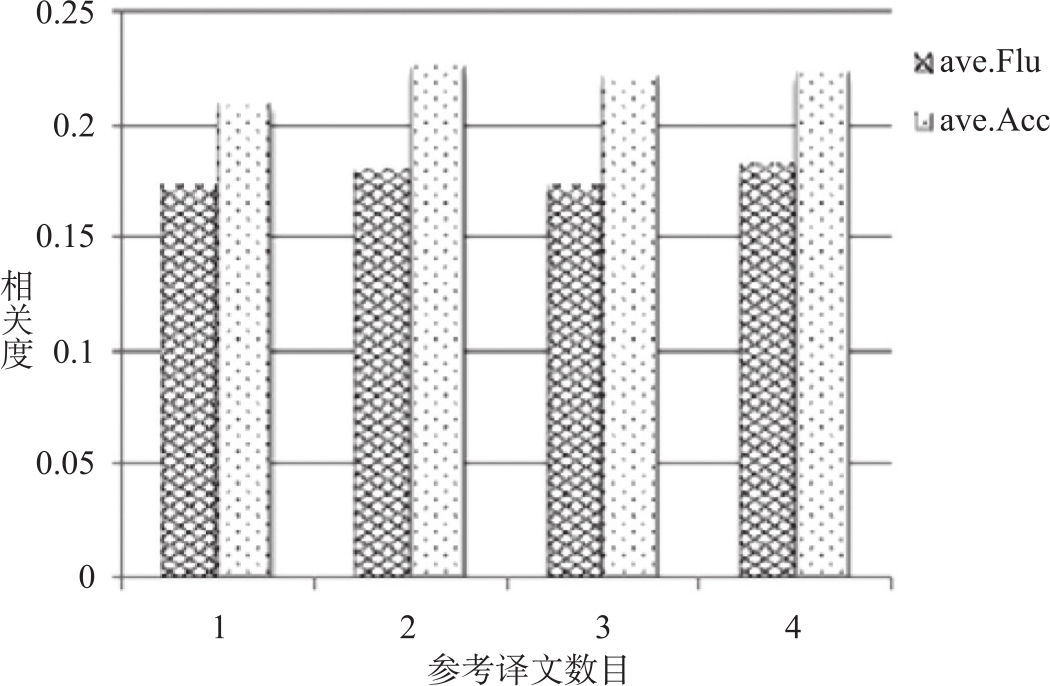
图3-5 参考译文数目对依存元组评价性能的影响
基于对参考译文进行依存分析后提取依存元组并进行扩展,构建宽松的匹配模式,根据机器译文中依存元组的匹配数目计算准确率和召回率,并结合译文长度和钳位数,将带有惩罚因子的F1值作为译文的最终得分。和传统n-gram算法相比,大大降低了无意义元组的比较;和相关研究相比,避免了对不完美译文进行依存分析引入的噪声。基于依存元组的评价性能有显著提升,而且对参考译文数目的变化不敏感,有利于降低有参考译文评价中的人工代价。