7.1.1 自动文摘的方法
自动文摘的研究内容十分广泛。根据来源文档的数目不同,自动文摘分为单篇文档的文摘和多篇文档的文摘两类。根据需求的不同,文摘可分为通用文摘和以查询为核心的文摘两种。通用文摘不必考虑特定的用户或特定的信息需求,仅仅从文档中提取重要信息即可;以查询为核心的文摘又称主题文摘,或用户文摘,则要和用户的查询需要相对应,常见的应用就是人机对话系统。根据语种分类,自动文摘可以分为单语种和多语种两种,显然,多语种的自动文摘难度更大。下面简单说明基于单一语言的单篇文摘和多篇文摘的研究方法。
一、单篇文档的自动文摘
一般对于单篇文档的文摘而言,关键问题是内容的选择,即提取哪些句子构成文摘,至于如何安排提取的句子,通常简单地按照原文的次序排列就可以,也不需要对句子进行增删处理。单篇文档文摘的研究方法有基于无监督学习的方法和有监督学习的方法两类。
(1)基于无监督学习的内容选择
内容选取被视为一个二分类任务,也就是标注文档中的句子“重要”还是“不重要”。那些重要的句子就是要提取的句子。
简单的无监督方法选择重要句子时,根据一个句子中包含重要(salient)的或信息量大(informative)的词汇的数目而定。得分大于一定阈值的词被认为是重要的词。
词汇重要性的判定指标最常用的是TF-IDF(Salton & Buckley,1998)。TF是词频(term frequency),表示一个词在文档中出现的次数;IDF即倒排文档频率(inversed document frequency),是一个词出现在不同文档中数目的倒数。二者相乘作为TF-IDF的值。因此那些在某一篇文档中高频出现而在其他文档中较少出现的词被赋予较高的权重,这些词被认为和某篇文档的内容关联较大。
也有研究表明,用对数似然比(Log-likelihood ratio,LLR)比TF-IDF的性能更好些(Manning & Schutze, 1999)。似然比是基于一个外部语料资源来估计一个词的重要性,定义为两个概率的比值,一个概率是假设词w在输入文档和外部资源具有相同分布时的观察概率,另一个概率是输入概率和外部资源具有不同分布时词w的概率。两个概率相比再取对数值就是LLR。如果一个词w的似然比值记作λ(w),计算句子中每一个词的二值权重如式7-1:
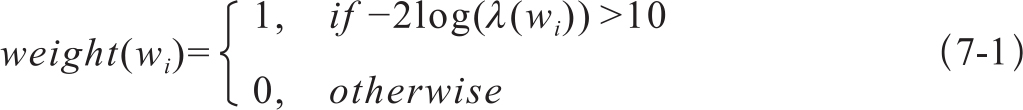
一个句子的重要性得分就是句中所有非停用词的平均权重。对文档中所有的句子根据重要性排序,排在前面的句子就是要提取的组成文摘的句子。这种方法称为质心文摘法(centroid-based summarization)(Lin & Hovy,2000)。
另一种和质心文摘相似的方法是中心位置(centrality-based)法。不是根据含有重要词的多少来计算句子得分和排序,而是计算每个候选句子和其他句子的距离,选择平均距离更近的那些句子。这种考虑句子之间距离的方法可以用TF-IDF加权的向量表示句子,再计算向量的余弦夹角,和其他句子的平均距离作为该句子中心距得分,中心距最小的句子通常认为可以代表其周围的句子,或者作为典型句而被提取出来作为文摘句。
除了考虑句子中重要的词汇来选择文摘句,语篇信息比如语篇的连贯关系(coherence relation)对文摘也十分重要。根据修辞结构理论(Rhetorical structure theory,RST)分析语篇,得到语篇单元(通常为段落)之间的RST关系。RST关系由核心(nucleus)和随体(satellite)构成。核心单元更合适作为文摘内容。
利用语篇分析器(discourse parser),可得到语篇结构树。树中每个节点的突显性可以递归定义为:
基本情况:叶节点的突显单元是本身。
递归情况:中间节点的突显单元是它直接核心子节点的突显单元的结合体。
根据这个定义,得到语篇单元的突显性并排序。
(2)基于有监督方法的内容选择
除了根据句子的重要词汇选择文摘关键句以外,还有很多其他线索可以利用,比如:句子的中心位置、PageRank的方法、句子在文档的位置(开始还是结尾)、句子长度等。而有监督学习方法的优势是可以将多方面的线索结合在一起。
有监督的方法需要有人工标注好的训练语料进行学习。比较著名的语料是Ziff-Davis语料,其中文摘句被标注为1,非文摘句标为0。也就是构建句子的二分类器可以进行文摘内容的选择。有监督方法常用的语言特征有:
· 句子在文档中的位置:段落的起始句、结尾句等往往都是很重要的句子
· 线索词或短语:比如英文中in summary、in conclusion等短语引导的句子都有总结性的信息,另外上文中提到的计算词汇重要性的各种值也都可以标记线索词或短语
· 句子长度:一般选择较长的句子,很短的句子往往不适合作为摘句
· 内聚性(cohesion):贯穿文档的一组相关词汇形成一个词汇链可体现句子的内聚性。一个句子包含词汇链中的词汇越多,越能反映连续的主题,也就越值得提取(Barzilay & Elhadad,1997)
有监督方法需要已经对句子作了标注的训练文档。人工对文档的每一个句子进行标注可能费时费力。有些文档,比如科学论文,本身就带有人工的摘要。要获取自动文摘的标注文档,可以利用此类文档,再借助对齐方法来发现原文中的句子作标注。但问题是,人工的摘要并非直接从原文提取的句子构成,这对提取方式形成文摘并非十分适合。对齐文摘句和正文内容的算法有:不包括停用词的最长公共子序列匹配法、最小编辑距离法等,以得到最相近的正文句子。
(3)句子简化
简化提取出来的句子,去掉一些形容词修饰语、同位语、属性子句,不包含专有名词的介词短语以及句子开始部分的副词等,再作为文摘句。简化句子时,一般要进行句法分析或部分句法分析处理。
二、多篇文档的文摘
从多篇文档中生成文摘常用于网页内容的综合,或者从多篇文档中查找一个复杂问题的答案。多篇文档文摘一般先对要做文摘的文档进行聚类,然后再进行文摘的三个步骤:提取内容、组织信息、句子实现。
相比单篇文档的文摘,多篇文档中冗余信息更多。文摘的句子虽然来源于不同文档,但应该是同一个主题,但又不能是相同的句子。因此,多篇文档文摘的算法重点是,向文摘中添加一个新句子时,要保证不能和已有的句子有太多的重复。避免重复的一个方法是增加一个重复因子,计算待加入的句子和已有句子之间的相似度,如果太相似则进行惩罚。另一个方法是将文档中的句子进行聚类,每一个类型只选择一个句子加入文摘中。
句子简化操作不仅可以在句子实现阶段加入,在内容提取阶段也可以进行。一般的做法是,利用各种简化规则对提取的句子进行简化,得到各种简化版本,再利用冗余信息的惩罚项判断各个版本中最适合加入文摘的版本。
选择了句子之后,组织提取的句子在多篇文档文摘中要更重要些。如果是故事类文档,可以按照时间顺序组织,但是这样组织也会缺乏连贯性。而保持内容的一致性(coherence)更是信息组织的难题和关键。
可以看出,多篇文档文摘要比单篇文档文摘困难得多,还有很多问题没有得到有效解决。自动文摘的质量评价就显得尤为重要。