3.1.5 基于词汇语义的相似度
基于词汇相似的评测中最有代表性的是METEOR算法,其主要思想是统计待评译文和参考译文的词汇相似度,并能够利用Wordnet等外部资源增加同义和近义词的匹配几率,从而部分反映词汇语义的相似情况(Banerjee & Lavie,2005)。METEOR算法先将待评译文和参考译文进行词对齐操作。如果多个连续词汇匹配,则构成一个组块(chunk)。当然,如果匹配的数目相同,其中的chunk越大,译文将和参考译文愈相似,有理由认为其翻译质量更好些。为此,设置了一个基于匹配chunk数目的系数以调整METEOR的分值。根据待评译文和参考译文对齐的结果分别计算准确率P和召回率R,再综合为F_mean值,同时针对不连续匹配的情形增设一个惩罚项Penalty,得到METEOR的最终得分。
最早版本的METEOR中P和R以固定权重综合在一起,得到F_mean:

在后来的改进版本中,P和R的系数变为根据实际训练样本来确定,而惩罚项的计算变为匹配的词组数目与单词数目的比率,另外还增加了一个经验系数,形如式3-8:
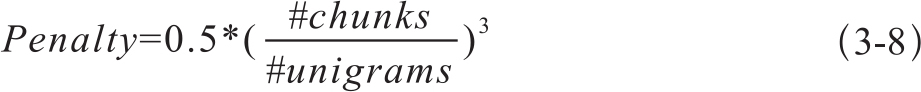
最终METEOR的得分为F_mean和Penalty的综合,形如式3-9:
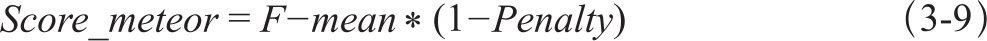
METEOR评测程序分为若干模块,包括单词完全匹配的模块、英文词形还原模块和基于Wordnet的同义词处理模块等,这些模块可以任意组合在一起使用,也可单独使用。
根据文献,METEOR的评测结果在测试数据集上明显优于基于n-gram的BLEU和NIST算法,与人工评测的相关度也更高。因此在WMT自动评测中,METEOR同BLEU和NIST得分一起称为事实认定(de facto)的自动评测得分。
对METEOR算法也有持续的改进研究,从F_mean中调和平均的系数设置、罚项的设置、英语以外的其他语言、可视化等方面进行了改进。在最新的版本METEOR1.5中,实词和功能词被赋予不同的权重,并可以适应不同语言调整权重设置(Denkowski & Lavie,2014)。其中F_mean的表达式变为式3-10:

惩罚Penalty项也变为式3-11:

匹配的连续词越多,译文的质量一般越好,因此,匹配的组块数目越少,惩罚力度越小,式中ch为匹配的组块数目,m为匹配的单词数目。上两式中,α,γ,β都是可以根据语料训练得到的可变参数。最终译文的得分表达式仍然是F_mean和(1-Penalty)的乘积。
TESLA(Liu et al.,2010)也是对METEOR的改进版本:对n-gram加权,加入了词序相似等。还有一些算法是融合METEOR和其他算法得到的,在柔性匹配基础上,更考虑了对齐词之间的距离因素。
目前METEOR的多个版本都是开源的,可以下载。其中METEOR 0.4.3(Perl版本)的下载地址为:http://www.cs.cmu.edu/~banerjee/MT/METEOR/。最新的METEOR1.5(Java版本)的下载地址为:http://www.cs.cmu.edu/~alavie/METEOR/。