3.1.9 神经网络学习的应用
按照神经生理学突触修正学派的观点,人脑的学习和记忆过程实际上是一个在训练中完成的突触连接权值的修正和稳定过程。其中,学习表现为突触连接权值的修正,记忆则表现为突触连接权值的稳定。突触修正假说已成为人工神经网络学习和记忆机制研究的心理学基础,与此对应的权值修正学派也一直是人工神经网络研究的主流学派。神经网络学习即学习过程中对人工网络节点联结权值的调整的过程。其中以基于纠错原理的有监督学习方法为主。
有监督学习的基本思想是:利用神经网络的期望输出与实际输出之间的偏差作为连接权值调整的参考,并最终减少这种偏差。最基本的误差修正规则为:连接权值的变化与神经元希望输出和实际输出之差成正比。其连接权值的计算公式为:
wij(t+1)=wij(t)+η[dj(t)-yi(t)]xi(t)
其中,wij(t)表示时刻t的权值;wij(t+1)表示对时刻t的权值修正一次后所得到的新的权值;η是学习因子;yi(t)为神经元j的实际输出;dj(t)为神经元j的希望输出;dj(t)-yi(t)表示神经元j的输出误差;xi(t)为第i个神经元的输入。
最近几年基于神经网络的深度学习在语音、图像领域的表现突出让研究者们对其在自然语言理解和处理领域应用的信心大增,纷纷探索,并且也取得了较大的进展。比如在词汇语义类比研究中,基于词向量表示(word2vec转换法)就得到了一些有趣的词向量类比关系(Mikolov et al.,2013a),如:
VBerlin-VGerman+VFrance=VParis
词向量表示词汇语义的出发点是,词汇语义可以由其上下文共现的词来体现,即语义相近的词出现的语境也相似,以此可以反映词汇语义差异或类比关系。但是由词汇扩展到句子级的语义表示还存在很多问题。句子模型中最简单的是基于词兜的神经模型(Neural Bag-of-Word,NBoW),模型一般包含一个映射层,将词汇、亚词单位或n-gram等映射到高维空间,实现词嵌入(word embedding)。但是NBoW忽视了词之间的顺序关系,对句子中词序的改变不敏感。递归神经网络(Recursive Neural Network,RecNN)可以利用句法分析的结果,在句法树的每个节点上,将其左侧上下文和右侧子节点组合为一层,逐渐递归,在顶层节点输出句子的表示。循环神经网络(Recurrent Neural Network,RNN)可以看作是递归神经网络的一个特例。由于RNN在学习输入序列过程中能够保存内部状态,因此可以输入任意长度的序列,这个特点使得长度不同的句子语义编码成为可能(Pascanu et al.,2013),理论上能够解决自然语言中长距离相依的问题。句子语义建模的最新发展是卷积神经网络(Convolution Neural Network,CNN)。在句子相似度分析中,He et al.(2015)利用CNN在没有任何外部资源的条件下达到和超过了目前句子相似分析的最佳性能。
神经网络学习的最大优势是模型训练学习中的特征不需要人工设计,节省了大量领域相关的劳动付出,因为神经网络模型可以自主获得分类的特征,从而提高了模型的可移植性。下面我们首先简单介绍词嵌入和相关神经网络结构的原理,再介绍目前神经网络学习在翻译质量自动评价中的应用研究。
一、词嵌入模型
词向量实现的是将词的上下文信息以低维实数向量的形式表示出来。词嵌入模型是基于词向量表示构建的词汇语义模型,主要有两个模型结构:CBOW模型和Skip-gram模型,对应的经典文献分别是(Mikolov et al.,2013a;Mikolov et al.,2013b)。
CBOW模型即连续词兜模型(Continuous Bag-Of-Words Model)。在该模型中,当前词出现的概率由其上下文的词决定,并且假定上下文所有词对当前词出现概率的影响是一样的。模型示意如图3-7:
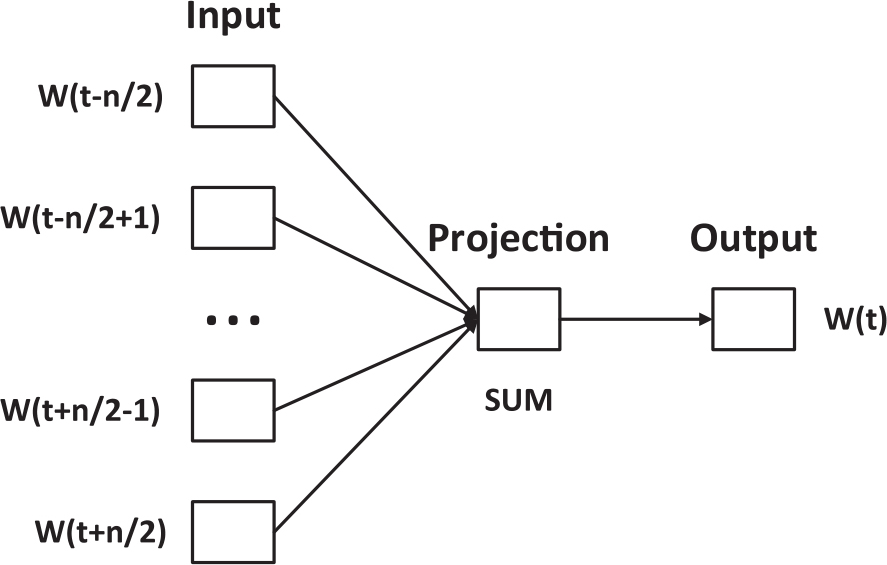
图3-7 CBOW模型
CBOW模型可以基于上下文context(w)预测当前词w(t)的出现概率。输入层接受w(t)的上下文中的n个词的词向量输入,即图中w(t)前面和后面的n个词:
w(t-n/2),w(t-n/2+1),…,w(t+n/2-1),w(t+n/2)
经过投射层(projection)实现n个词向量的累加,输出层是一棵哈夫曼树(Huffman tree),这棵树的叶子节点是训练集中出现过的词,权值是每个词在训练集中出现的次数。对投射层的结果用随机梯度下降(SGD)算法进行预测,使p(w|context(w))值最大化,其中,context(w)是指词的上下文中的n个词。模型训练完成时可得到全部词的向量表示w。CBOW模型的训练复杂度Q为:
Q=N*D+D*log2V
其中,N表示输入层的窗口长度,D表示投射层的维度,V表示训练集中不同词语的数目,该公式的主要计算量在D*log2V的计算上。
Skip-gram模型与CBOW模型相反,是基于当前词来预测其上下文的发生概率。该模型如图3-8:
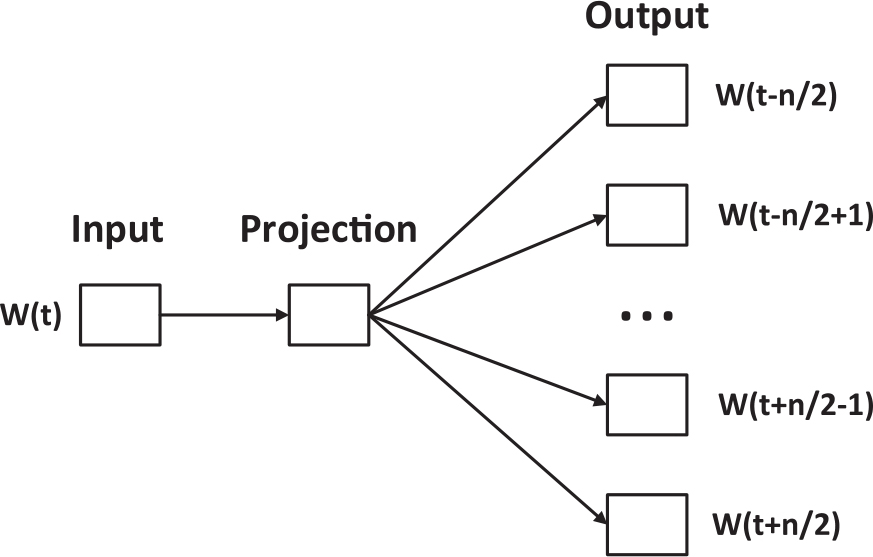
图3-8 Skip-gram模型
Skip-gram模型的训练目标是使得式3-13取得极值:
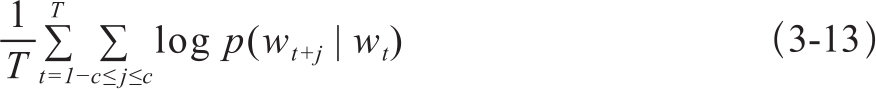
其中,T是训练集的大小,c表示最大词之间距离,即n-Skip-gram中n的大小。
该模型的计算复杂度正比于下面的表达式:
Q=c*(D+D*log2V)
式中,D同样代表投射层的维度,V表示训练集中不同词语的数目。可以看出,Skip-gram模型比CBOW模型的计算复杂度更高。
二、循环神经网络RNN
循环神经网络(Recurrent Neural Network,RNN)能够在节点内部储存历史信息,因此RNN更适合处理节点存在相互关联的问题。RNN节点是重现的,展开节点的RNN结构如图3-9:
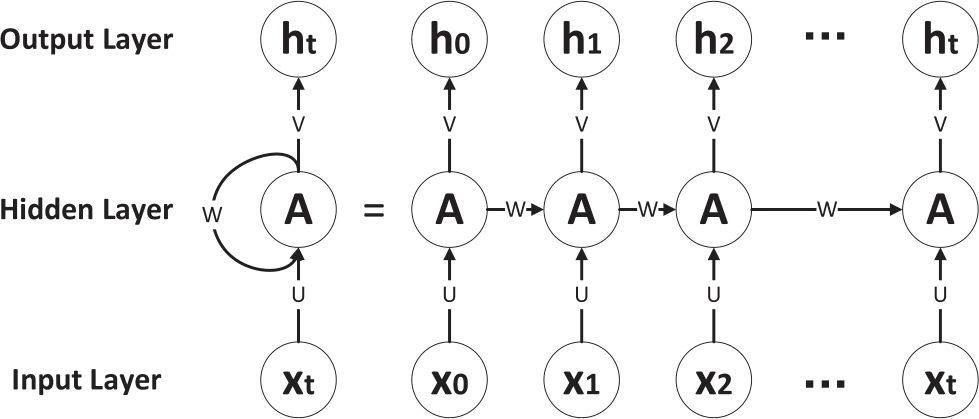
图3-9 RNN节点展开结构
图中U、W分别表示连接输入层和隐层、隐层和输出层之间的权值矩阵。隐层节点具有相同的参数设置,也就是说,经过网络结构的序列中的每个元素都得到同样的处理。输出节点和附近节点独立,不依赖前面的计算结果。
三、长短时记忆网络LSTM
长短时记忆网络(Long Short-Term Memory Networks,LSTM)将RNN中隐层的简单节点扩展为具有更复杂结构的单元(cell)(Hochreiter & Schmidhuber,1997)。cell包含若干个门(gates),随着序列不断输入,门可以控制保留或者删除已经记忆的信息。cell的结构如图3-10:
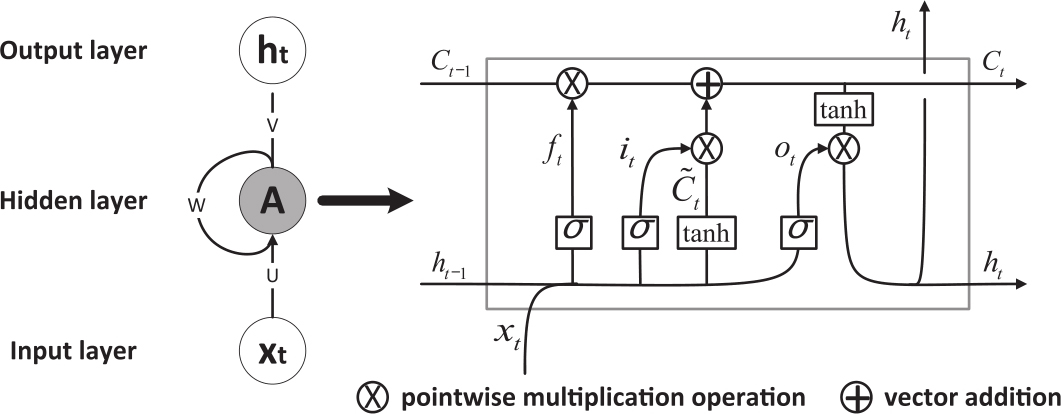
图3-10 LSTM中的cell结构
LSTM中有多种门,如遗忘门和输入门。遗忘门的输入是前一个cell的输出ht-1和当前输入xt,并考虑到前一个状态Ct-1来决定多大比例遗忘掉某些信息。遗忘门的输出结果依据以下的函数计算:
ft=σ(Wf·[ht-1,xt]+bf).
输入门用来决定在当前输入xt、新候选值t和前一个状态ht-1的情况下,什么值应该更新。更新后的结果由下式计算:
it=σ(Wi·[ht-1,xt]+bi)
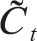 =tanh(WC·[ht-1,xt]+bC).
=tanh(WC·[ht-1,xt]+bC).
Ct=ft*Ct-1+it*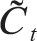 .
.
而当前输出ht用输出门计算,函数的输入包括Ct、ht-1、xt三部分,如下所示:
ot=σ(W0·[ht-1,xt]+b0)
ht=ot*tanh(Ct).
研究还表明,LSTM的另一个优势是可以避免门结构训练过程中梯度消失(vanishing gradient)的难题。
四、卷积神经网络CNN
卷积神经网络(Convolutional Neural Networks,CNN)也广泛地用于自然语言处理任务中5。CNN是将若干层带有非线性激活函数的卷积作用到输入信号上的一种网络结构。传统的前馈网络的结构是每一个输入神经元和输出神经元实现完全的互连。在卷积神经网络中,只利用输入的卷积计算得到输出。每一层都可以加入过滤器,并把过滤后的结果组合在一起,这个过程称为池化(pooling)。训练过程中,CNN网络根据特定任务学习到过滤器的参数。后一层利用的是前一层处理后的高级特征,最后一层分类器则在高级特征基础上完成分类。
CNN的框架结构主要包括四部分:输入层、卷积层、池化层和激活层。各层可以有多种参数或方式选择,如图3-11所示:

图3-11 CNN网络框架和参数选择
Zhang & Wallace(2015)将CNN用于句子分类任务,给出的网络结构如图3-12:
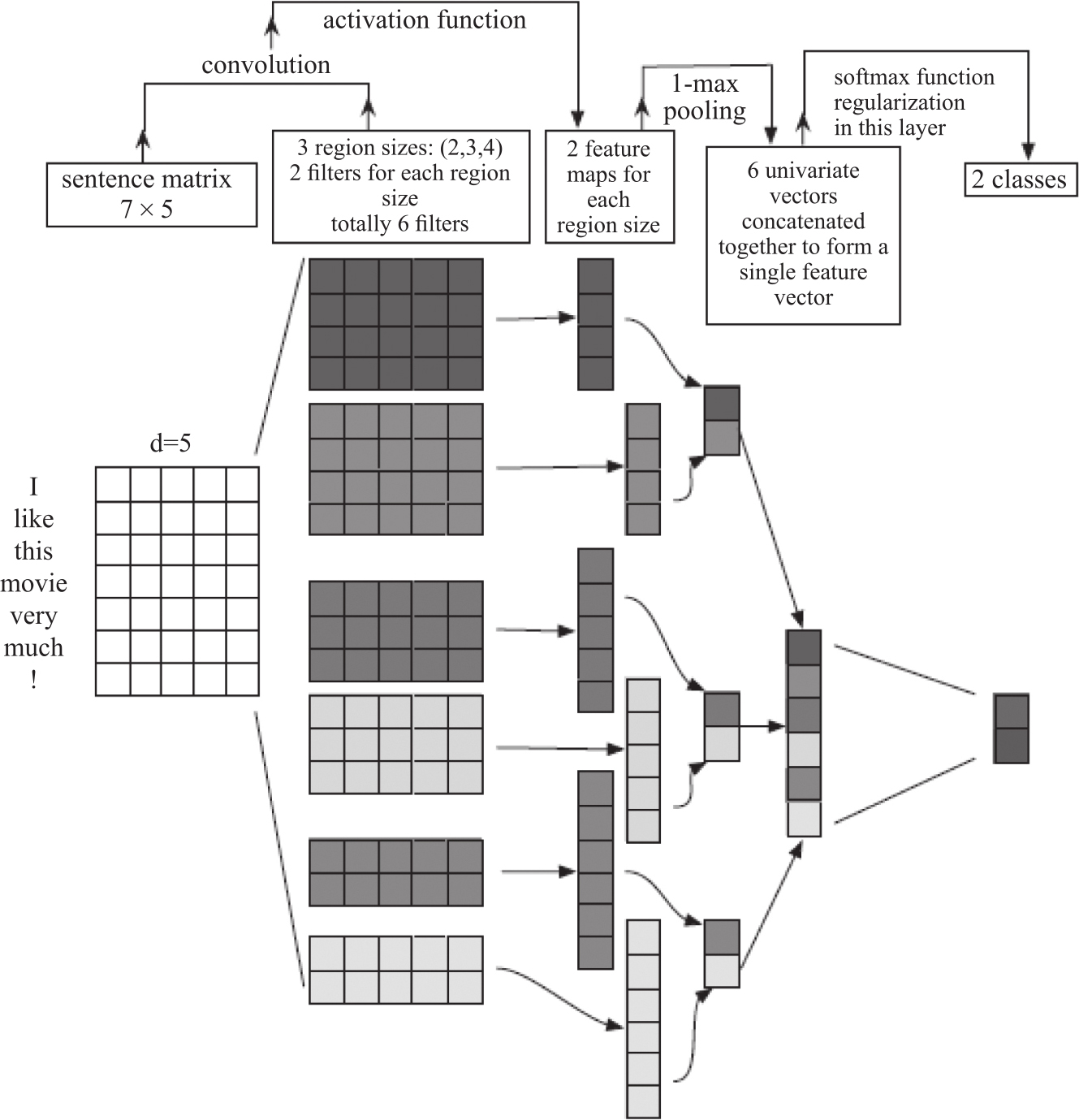
图3-12 CNN用于句子分类的框架
这个网络结构实现的是句子分类任务,同时也为译文质量的评测提供了参考结构。
五、神经网络用于机器翻译评价研究的探索
深度学习网络应用到翻译质量评价中的研究还处在探索阶段,还没有收获显著的性能。Guzmán et al.(2015)研究了基于一篇参考译文的两个机器译文比较的神经网络结构,能够判断哪一篇英文机器译文质量更高,但不能用于单篇译文的质量评分,不能基于多篇参考译文进行评价,可用于对比两个译文的质量。翻译质量排序系统结构如图3-13:
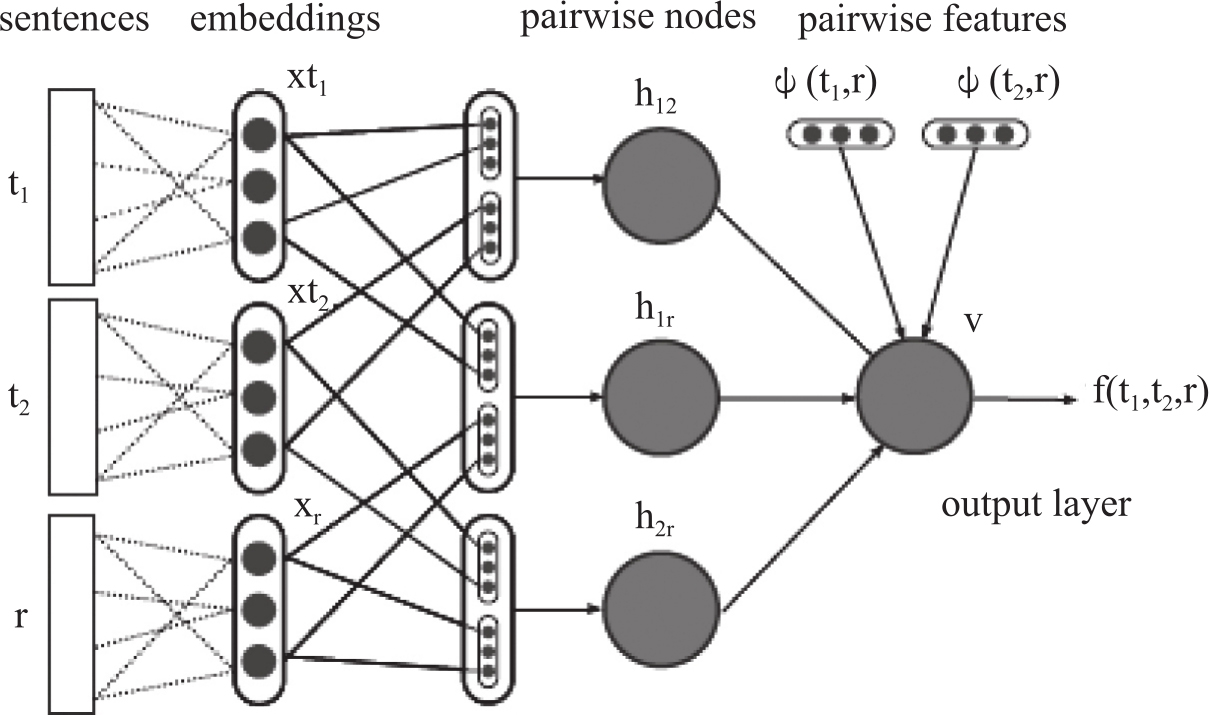
图3-13 基于神经网络的翻译质量排序系统结构
图3-13中,t1、t2表示两个机器译文的句子,r表示参考译句。首先把t1、t2、r利用句法和语义的词嵌入表示成固定长度的向量[xt1,xt2,xr],作为神经网络结构中输入层的输入。其中句法词嵌入利用的是神经网络句法分析器中的句法向量,得到的是一个25维的向量;语义嵌入利用的是现成的词向量工具,基于维基百科等外部资源得到的固定长度的词向量(维度为50维)。将句子中所有词的词向量的平均值作为句子的向量表示。再把t1、t2、r句子的向量表示两两连接,得到x1r=[xt1,xr],x2r=[xt2,xr],x12=[xt1,xt2],再通过一个非线性激活函数g(.)完成转换,形成评价网络结构的3个隐层节点h12、h1r、h2r。节点的表达式为:
h1r=g(W1rx1r+b1r)
h2r=g(W2rx2r+b2r)
h12=g(W12x12+b12)
W∈RH×N是输入层和隐层之间的权重矩阵,b表示相应的偏置量。
同时模型中还加入了一些外部特征,包括机器译文针对参考译文的BLEU得分等。加入了外部特征后,输出层的输出表达式为:
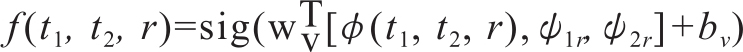
即根据符号函数的输出判断机器译文t1和t2哪一个质量更好,输出两种结果:结果为1说明参照译文r,t1的质量优于t2,结果为0说明t2优于t1。代价函数选择的是log-likelihood。网络参数的训练采用Theano神经网络学习模块中的随机梯度下降(SGD)算法,并结合adagrad更新策略。
在WMT12数据集的实验结果表明,这种两个译文质量排序的网络结构可以有效区分两个句子的质量,Kendall tau的指标可达29.70。
但我们看到,研究中的还有很多问题,比如,该评价结构不能利用多个参考译文,没有利用原文的特征,也没有考虑到句法分析器引入的噪声,并且对领域语义的依赖性较强。
在2015年的WMT评测中,性能最好的自动评价系统也用到了神经网络中循环神经网络RNN(Gupta et al. 2015)。Gupta et al.利用了密集向量空间(dense vector spaces)和树形LSTM网络结构(tree Long Short Term Memory networks),并结合外部资源构建了翻译质量评价系统。
树形LSTM网络结构是对简单LSTM的改进,简单LSTM结构只能处理序列(sequence)信息,树形LSTM可以接受句子句法分析的树形数据结构。图3-14是两种结构的简单对比:
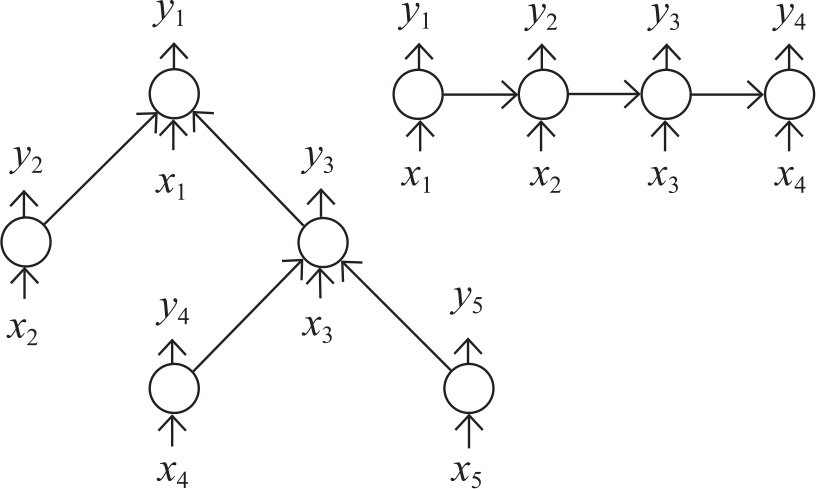
图3-14 树形LSTM和简单LSTM网络结构的对比
他们将参考译文和机器译文分别用依存树形LSTM表示出来,基于网络结构预测机器译文和参考译文的相似度得分,预测主要利用了机器译文向量htra和参考译文向量href的距离、角度信息,表达式分别为:
h×=href∘htra
h+=|href-htra|
hs=σ(W×h×+W+h++bh)
估计概率分布向量: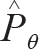 =soft max(Wphs+bp)
=soft max(Wphs+bp)
输出估计值: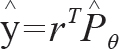 ,其中rT表示排序矩阵的转置。
,其中rT表示排序矩阵的转置。
代价函数利用的是概率估计分布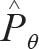 和实际分布p之间的KL距离,表示为:
和实际分布p之间的KL距离,表示为:
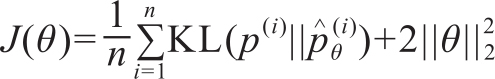
在WMT15的评测数据集上,该系统与人工结果的Pearson相关度和Spearmam相关度在系统级评测中是最优的,达0.976,但在句子一级的评测中表现一般。
综合来看深度学习译文评价模型的构成,主要包括两个部分:句子语义表示模型和质量差异估计模型。
句子语义表示模型实现句子语义编码。句子语义隐藏在句中词汇、次序、语法等复杂特征之后。在深度神经网络学习的句子编码模型中,输入变量有词汇、词序关系、词汇极性、语法结构等不同粒度和层面的语言信息,终结点处输出句子语义向量表示。句子语义要求神经网络学习能够根据句子词汇输入序列不断完善语义表示,记忆内部状态的改变,并且对词汇次序不同带来的语义变化敏感。句子语义向量表示是深度学习尚未解决的难题。
质量差异估计模型用于计算待评译文的语义向量与参考译文语义向量的距离,并结合语言形态的合法性对机器译文质量给予评价。语义距离反映的是机器译文的充分性指标,从语言形态角度评判的是流利度指标。
我们认为,基于深度学习模型的译文质量评价系统框架应该具有以下的框架结构,如图3-15,更多利用深度学习研究翻译质量的方法还在探索中。
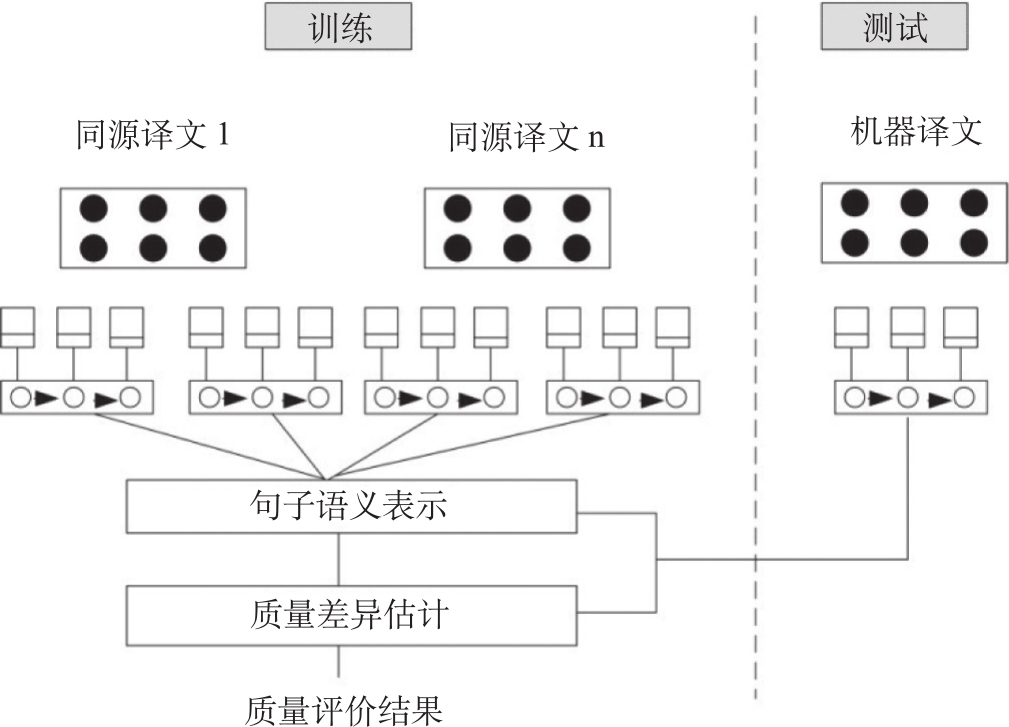
图3-15 基于深度学习的译文质量评价模型