8.1.1 语篇的划分
很多类型的文本都有特定的结构,比如研究论文一般有摘要、引言、方法、结果、结论、参考文献等部分组成,新闻类的一般包括导言、正文等。自动语篇划分(discourse segmentation)的任务就是识别这些语篇结构,将文档依次划分为若干子话题(subtopic)。这种划分也称线性划分(linear segmentation),用来和层次语篇划分(hierarchical segment)相区别。如果从语篇层面评价译文,需要评价系统能够区分语篇的不同部分,但是语篇划分是一项没有很好解决的难题,从算法上分,可以分为有监督和无监督两类。
一、无监督的方法
无监督方法划分语篇依靠的是内容的衔接(cohesion)。衔接是利用语言连接文本各部分的手段。词汇衔接(lexical cohesion)通过不同部分的词语之间的关系得以反映,强调的是不同部分的连接方式。
例如:英文写作中展开话题或转换到新的话题时,常用短语有:Regarding
X,As regards X,In terms of X,In the case of X,With regard to X,With respect to X,As far as X is concerned等等。而表示对比和比较时,常用的短语有:In addition,On the other hand,However,Despite this等。这些词汇或短语成为联系不同内容的纽带,也是研究语篇结构的重要线索。
Textiling(Hearst,1997)提出了一种基于衔接划分语篇的方法。算法包括三个步骤:断词(tokenization)、词汇打分(lexical score determination)、边界识别(boundary identification)。断词就是将单词和附属的标点分开,转换为小写形式,进一步获得单词的词根,去除停用词。随后将还原后的词每20个一组,构成一个个的伪句子。接下来通过词汇的连贯性得分计算伪句子间隙的距离。通过间隙前后两个伪句子中词汇平均相似度来计算连贯性得分。通常k个伪句子组成一块,利用向量的余弦距离反映两块之间的距离,也就是用i-k到i的伪句子块和i+1到i+k+1的伪句子块的相似度作为第i个间隙的大小。最后计算每个间隙的深度得分,深度得分是从相邻的峰顶到谷底的距离和。而深度超过设定阈值时就识别为边界。可以将平均谷深–标准差(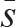 -σ)作为阈值判断边界。更新的方法是利用分裂聚类(divisive clustering)来判断(choi,2000;choi et al.,2001)。
-σ)作为阈值判断边界。更新的方法是利用分裂聚类(divisive clustering)来判断(choi,2000;choi et al.,2001)。
二、有监督方法
有监督的方法需要有人工语篇边界划分的语料。带有语篇边界的语料部分已经存在,比如不同的新闻片段,自然形成了语篇的边界。
有监督的方法划分语篇任务被视为序列标注问题,这样,分类器像SVM、HMM、CRF等都可以用于边界识别和标注。而在无监督方法中所采用的划分依据,也都可以用作有监督学习的特征,比如衔接词汇、词汇的余弦相似度、LSA、共指特征、词汇链等。还有一种特征是语篇线索词(cue words),这些词(有时是短语)反映了语篇的结构特点。一般情况下,线索词和领域有关。比如新闻中开头词汇,“据新华社报道”“记者某某”及时间等,甚至有时标点符号也可作为划分语篇的线索词。收集特定领域的语篇划分的线索词,然后在语料中检索线索词是否出现来作为划分的依据,也可以训练分类器自动识别哪些词能够很好地表征语篇边界的线索词汇。