3.1.10 多篇参考译文的作用
在基于参考译文的评价方式中,还有一个被普遍忽略的问题:由于针对同一原文的合理译文是多样的,并没有唯一确定的译法。多种译法在词汇选择、句子结构等多方面存在着变化,因此简单机械地采取和某一篇参考译文匹配的评价方式难以反映出译文合理译法的多变性。在上面各节介绍的基于参考译文的评价方式中,多数声称可以在算法中基于多篇参考译文进行评价。匹配时,只统计匹配的数目,并不区分与哪一篇参考译文匹配,数目越多,待测译文的质量越好。这是对译文实际情况的简化处理。实验结果也表明,当单纯增大参考译文数目时,并不能再进一步提升自动评测算法的性能(Doddington,2002)。对这个问题的研究可以从两个角度进行,一是进一步扩充参考译文的数目,二是挖掘多篇译文的共性。
一、机械扩充参考译文的数目
自动评价中依据参考译文的方法根本思想是比较待评译文和参考译文的相似度,但是某一个参考译文仅是多种译法中的一种方式,如何能从形式表达的相似性挖掘到深层语义是否相似呢?多少篇译文才能涵盖同一个原文的全部译法?
为此,Dreyer & Marcu(2012)利用标注工具,根据给定的参考译文用软件自动生成了指数级的类似的句子,形成参考译文集合,然后计算机器译文和参考译文集合的最小编辑距离,作为机器译文质量的得分。该系统称为HyTER自动评测系统。研究发现,大规模扩展参考译文的数目可以在一定程度上提高评测性能。
Dreyer & Marcu形成参考译文的方法是比较机械的,就是把人工给定的一篇参考译文进行短语划分,然后从语料中检索这些短语的替代短语,再把所有可能的替代短语排列组合为“语义等价”的句子,存储为递归转移网络(Recursive Transition Networks,RTNs)结构(一种类似FSA有限状态机的结构),以便于查询匹配,最终从某一个句子可以生成指数级数目的相似句子。
尽管他们的研究证实了多篇参考译文对基于比较的评测算法的重要性,但是,他们也发现,即使用自动方法生成几亿级个“语义等价”句也难以覆盖所有合理的译法,而且覆盖率还十分令人失望,一些人工译法仍然不能涵盖。我们认为,Dreyer & Marcu在用替换方式生成句子时并没有考虑到上下文语境、语序、词汇形态的变化等因素,简单地通过排列组合生成的句子,不仅计算量非常巨大(是个NP完备问题),而且难以成为流畅的、容易被人理解的句子,和人工译文相距甚远,毕竟机器生成的译文缺乏语法和语义约束,不一定是合法的译文。参考译文的质量不高,从而影响了评测的准确性,这是问题的根本。另外,他们对不同语种的译文生成也没有考虑语言的差异性问题。
二、探索多篇参考译文的共性
在我们看来,人工多篇参考译文(下文称同源译文)不能简单地视为所有n-gram的集合,位于某一篇参考译文中的n-gram是和它所在的上下文密切相关的,和不同的参考译文匹配上的n-gram组合在一起,并不一定能流利准确地反映出原文的语义。
目前能利用多篇参考译文的算法有BLEU、NIST、METEOR等。为此,我们对如何有效利用多篇参考译文进行了探索,修正了BLEU、NIST和METEOR算法。
(一)改进的基本思想
如果针对同一原文有多种译文,那么每一译文均可以组成特定的语义空间,有各自的特点。但基于同一原文的译文基本语义又必须受到原文的限制,因此必然存在语义空间的重叠部分,这个重叠的语义空间就表现为有一些词汇或短语是相同或相近的。这是我们基于多篇译文改进评测算法的基本思想。
我们先通过一个实例观察多篇译文中重叠内容的特点:
原文:枪手被警察击毙。
参考译文1:The gunman was shot to death by the police.
参考译文2:Police killed the gunman.
参考译文3:The gunman was shot dead by the police.
参考译文4:The gunman was shot to death by the police.
机器译文:Gunman is shot dead by police.
在来自不同译者的4篇参考译法中,有三个词“the,gunman,police”和一个标点符号是完全一致的;单词“shot”和“by”出现了三次,而“dead”只出现在一篇参考译文中。显然,在多篇参考译文中,出现次数多的单词传递了原文句子的主要含义。对于上面的机器翻译结果,一共有6个单词和全部参考译文匹配,其中“gunman,police”是所有参考译文中都出现的单词。但是一般的评测算法,如BLEU,却同等地对待这样的单词,在NSIT算法中,甚至是因为多次出现而被置于很低的信息值(具体读者可根据NIST的计算式自行计算),比只出现一次的“dead”的得分低。不难根据前面已经介绍的BLEU和NIST得分算式计算得到,该机器译文的BLEU得分为0,因为没有3-gram匹配,平滑后的BLEU得分也仅为0.3217,NIST得分只有2.8867。然而人工评价该机器译文的流利度和准确率得分分别为4和4.7分(人工评分范围为1-5分)。因此,我们如果将n-gram在多篇译文中的出现频次考虑进去,对那些被多篇参考译文“共享”的n-gram增大权重,将有助于把握原文的核心语义信息,从而更准确地评价机器译文质量。
多次出现在多篇参考译文中的n-gram当然不仅仅是承载核心语义的实词,还有一些功能词,增大权重不能对功能词实施。
(二)基于多篇参考译文的n-gram权重的修正方法
n-gram在多个参考译文中的出现次数毋庸置疑地成为计算参数。但是,简单地用频次和参考译文的数目相除,结果又和直观分析不符,因为出现在4篇参考译文的n-gram的重要性不一定就是只出现在1篇译文中的4倍。为此,我们将比值取了对数。又考虑到对数值为0的情况,这样n-gram的权重调整表达式变为式3-14:

其中M表示n-gram在多少个参考文中出现过,refno表示参考译文的总数。
但是初步实验结果表明,基于上面的修正权重后的BLEU和NIST算法性能没有明显的提升,因为,在基于句子的翻译中,不同译法中公共n-gram最多的是功能词,也就是说,大部分时间我们错误地增大了功能词的权重,违背了我们基于多篇译文修改n-gram权重的初衷。只考虑n-gram在不同参考译文中的频率特征不能充分体现我们的设计思想。为此,我们又进一步考虑了n-gram的散度(divergence)。
我们先通过一个例子介绍散度概念。下面是同一句原文的三种译文:
a. At this time, the police have blocked the bombing scene.
b. They have now sealed off the spot.
c. The police has already blockade the scene of the explosion.
通过观察不难发现,这三句译文意思相同,但几乎没有相同的词,译句形式的差别非常大。另外一个角度也说明,原文的语义被不同的译者理解为差距较大的意义表达方式,翻译的难度较大。而如果是功能词的话,由于功能词较少,一旦译者使用,将有更多的机会重叠。为此,我们定义一个新的变量——n-gram的散度,用来衡量n-gram在多篇参考译文中的聚合程度。
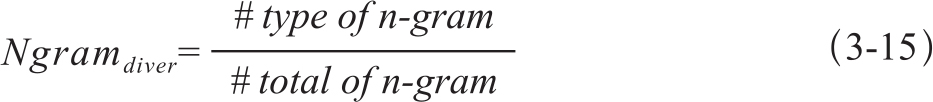
分子表示不同n-gram的计数值,分母是n-gram的总数。这个参数有些类似于语料库研究中常用的形符/类符比(type/token ratio)。
匹配的n-gram中n的值越大,相同的语块越长,译文质量也越高,因此我们又把n-gram的n值纳入到对数表达式中。再和n-gram散度值结合起来,得到基于多篇参考译文n-gram权重的修正因子如式3-16:
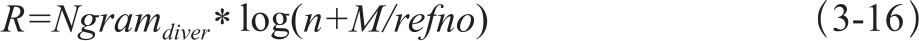
除此之外,削弱功能词的方法还可以利用齐夫定律的思想(Zipf's law)。作为对比研究,我们又构建了另外一种n-gram的修正因子R',表达式如下式3-17:

增加了修正因子后,BLEU和NIST的得分分别变为如下形式:
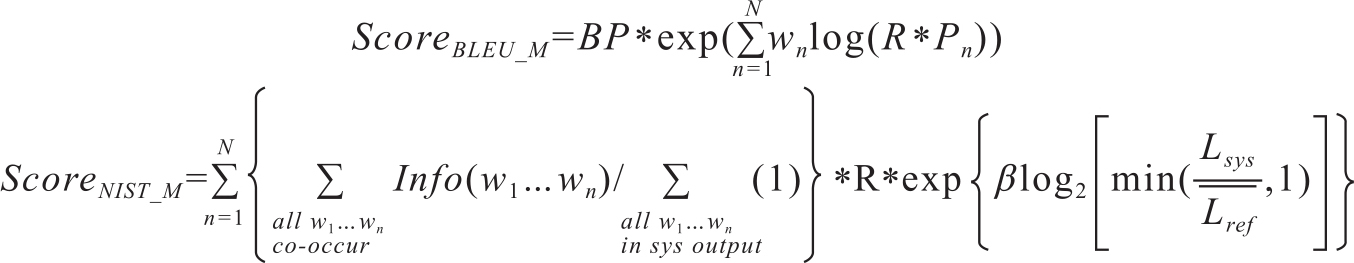
式中的参数含义可参见前面介绍的BLEU和NIST算法。其中R参数也可以是R',这样就是另外一种修正因子了。
基于多篇参考译文修正METEOR算法,需要同时修正准确率Pre和召回率Rec两个指标。修正后的Pre和Rec的计算式分别为3-18和3-19:
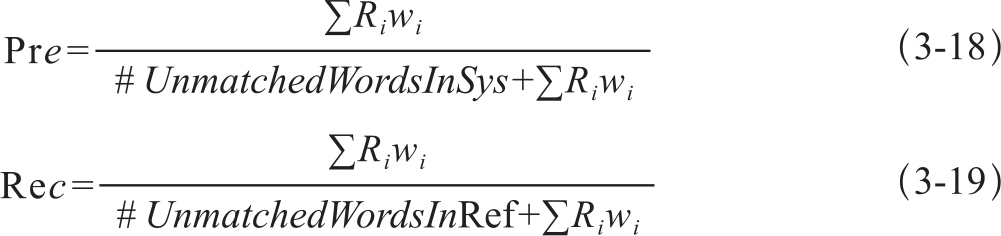
其中,Ri是单词wi依据式3-16或3-17计算的修正因子,最终METEOR的得分与惩罚因子不变(我们通过修改METEOR0.4.3版本代码进行实验)。
METEOR算法基于多篇参考译文评测时,先分别求出基于单篇参考译文的得分,然后将最高分HS作为最后得分。研究中,我们不仅修正了匹配单词的权重,还尝试了针对多个评分结果的其他处理方式,如最低分LS,求算术均值AM,求几何平均GM和调和平均HM,作为最终的METEOR得分。这几种平均的计算方式如下:
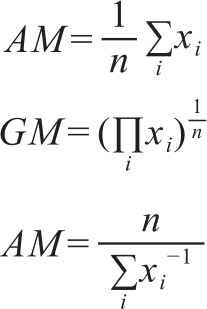
一般情况下,这几个分数之间满足以下大小关系:
HS≥AM≥GM≥HM≥LS
(三)实验结果
实验数据的介绍:由于有多篇参考译文的机器翻译评测数据很少,我们最终找到了LDC发布的两个数据集来验证我们修正因子的合理性。这两个数据集分别是:
· Multiple-Translation Chinese Part 2(MTC-P2)(LDC2003T17):每一句中文原文有4个人工参考译文。语料包括100篇新闻,每篇的字数在212到707之间,共有878个句子。每个原文对应3个机器系统译文,记为P2-05、P2-09和P2-14。每一句都有人工在流利度和准确度上的打分。
· Multiple-Translation Chinese Part 4(MTC-P4)(LDC2006T04):也是由100篇新闻构成,原文字数在280-605之间,共有919句。每一句原文对应6个机器系统的译文,记为P4-09、P4-11、P4-12、P4-14、P4-15和P4-22。也都有2-3的人工得分。
需要说明的是,这些评测数据中人工打分的一致性并不高。我们计算了人工打分的一致性系数,即Cohen's kappa系数(Bojar et al.,2014),对所有9个机器系统评价的一致性结果如表3-9所示:
表3-9 人工评分的kappa一致性
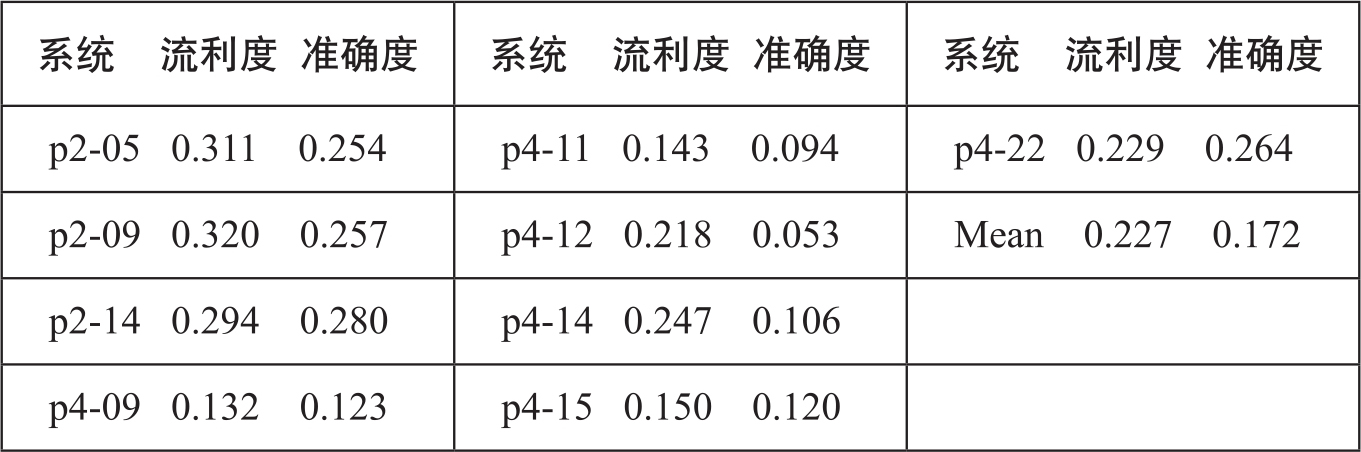
毫无疑问,较低的人工评分一致性增大了研究的难度。
我们分别在系统级、文档级和句子级测试增加了多篇参考译文修正因子的BLEU、NIST和METEOR评测算法的性能变化,结果如下各表。
· 系统级评测
BLEU和NIST修正后系统级的评测性能如表3-10:
表3-10 系统级评测性能
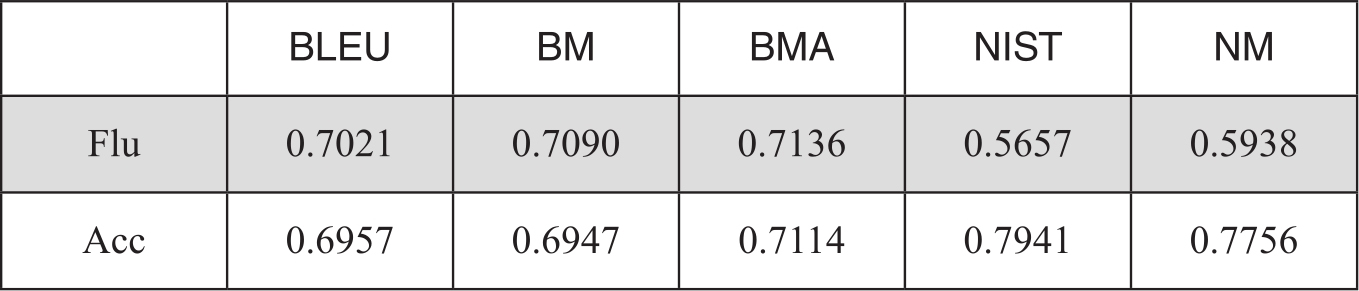
表中BM表示基于多篇参考译文的BLEU算法,BMA是用算术平均替代几何平均的多参考译文BLEU算法,NM表示基于多篇参考译文的NIST算法。数据为自动评分和人工分的Pearson相关度。
表中数据表明,在系统级流利度评测中,BMA的性能最好,比NIST评测结果高出26.14%,比原始的BLEU评测高1.64%。BM也比一般的BLEU要好些。加入了修正因子后的NM也比原始的NIST评测要优。但在准确度指标上,优势不明显,NIST的性能仍然是最好的。如果使用修正因子R',在系统级流利度与人工分的相关度为0.6926,准确度上的相关度为0.7391,在所有结果中是最佳结果。
METEOR算法由多个模块构成,可单独使用,也可组合使用。为反映同义词扩展对算法的影响,我们在待测译文和参考译文对齐时采用了两种方式,一种是进行英文词汇的词形还原处理(AS1模块),另一种则加入了基于Wordnet的同义词扩展匹配(AS2模块)。METEOR原始算法性能在各种均值处理下和不同模块的系统级与人工评分的相关度如表3-11和表3-12:
表3-11 使用AS1模块的系统级评价性能
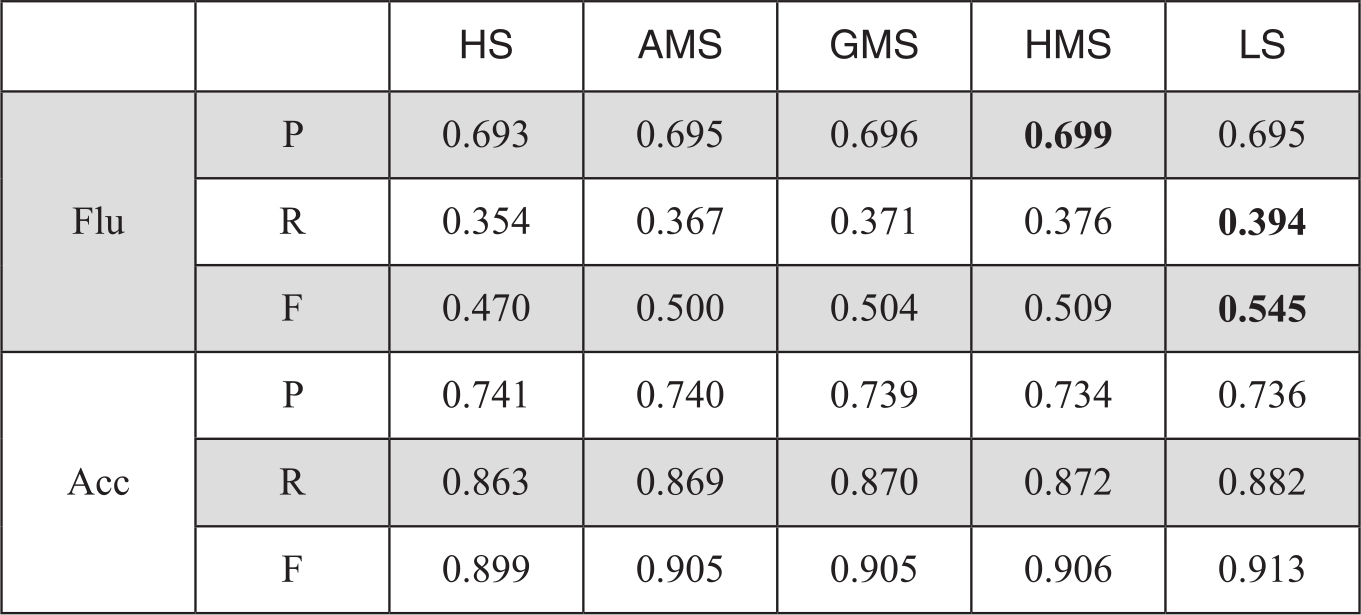
表3-12 使用AS2模块的系统级评价性能
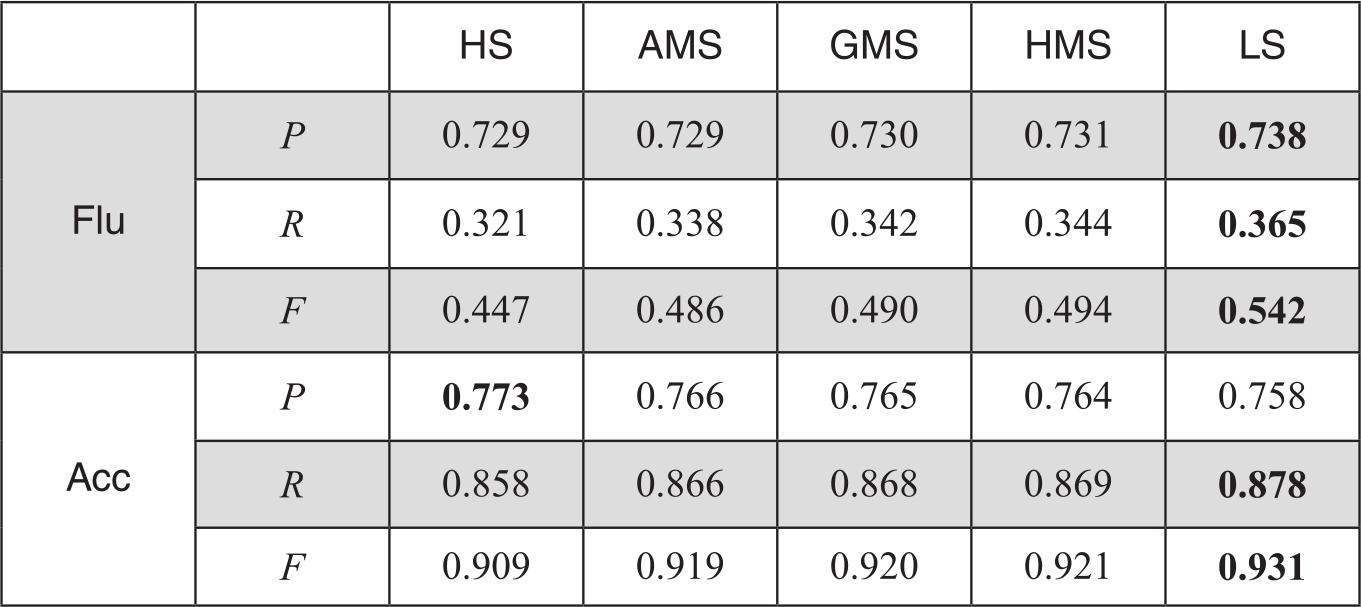
由于用AS2模块的性能更优,在下面的实验中,我们不再测试AS1模块的数据,全部都基于AS2模块进行。从多个得分上看,最佳点基本出现在取最高分和最低分上,因此,在系统级和句子级对METEOR修正算法验证中,我们只对比最高分HS和最低分LS两项。基于多篇参考译文对METEOR修正后,在系统级评测上的相关度性能如图3-16和图3-17所示:图中O表示原始METEOR得分,R表示用R因子修正METEOR,R'表示用R'因子修正METEOR的结果。
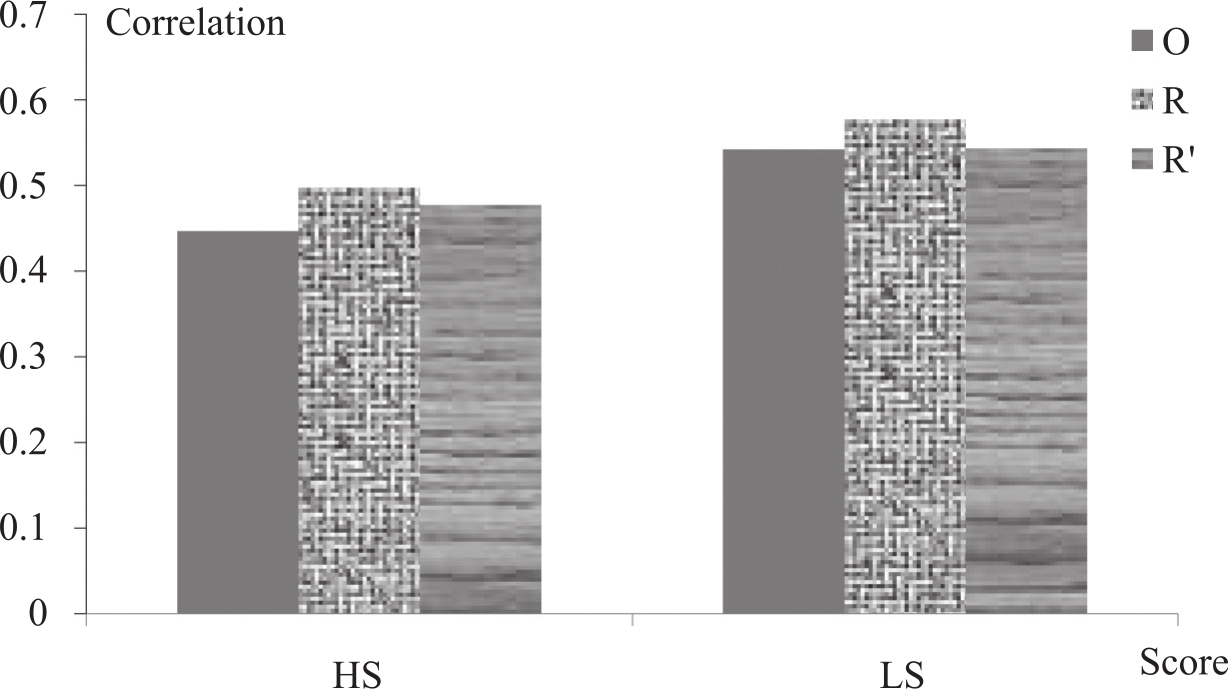
图3-16 修正的METEOR算法在系统级流利度上的评测性能
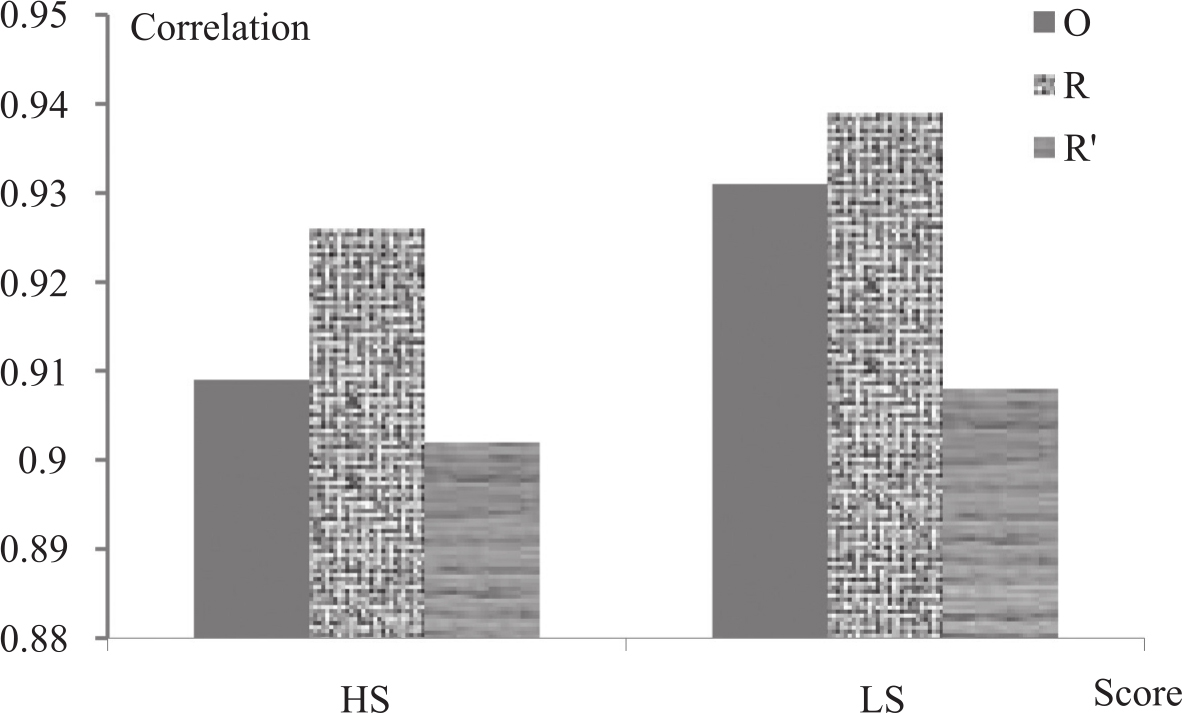
图3-17 修正的METEOR算法在系统级准确度上的评测性能
从上面两图中明显看出,加入了基于多篇参考译文的R修正因子后,METEOR性能有了较大幅度的提高。
由于我们的实验是在METEOR 0.4.3Perl版本上进行的修正,METEOR的最新版本为1.5,为此我们也将实验与最新版本的METEOR进行了对比。表3-13中v 0.4.3+表示修正版的METEOR 0.4.3。
表3-13 系统级评测多个METEOR版本的对比
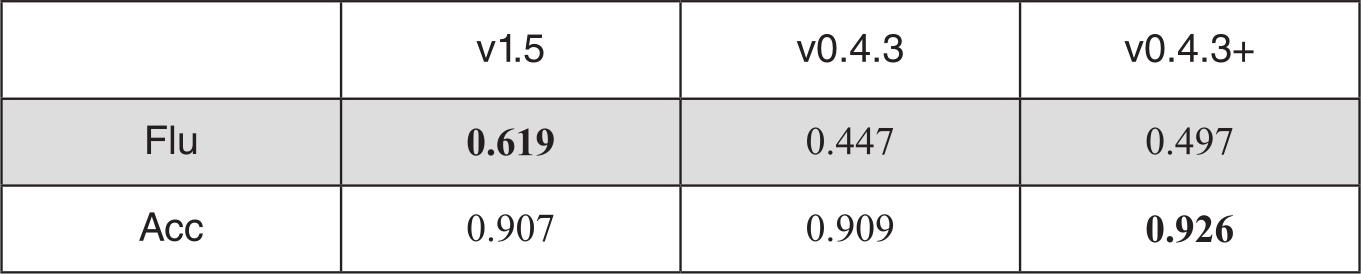
对METEOR修改后,系统级的准确率评测比最新的1.5版本高出2%,尽管在流利度上不及1.5版,但仍比原始的0.4.3版本高出0.05,充分说明了在利用多篇参考译文的公共信息上,我们提出的思想和方法是有效的。
· 文档级评测
文档级评测,修正的BLEU和NIST与原始算法的对比结果如表3-14和表3-15所示。
表3-14 BLEU和NIST文档级流利度评测对比结果
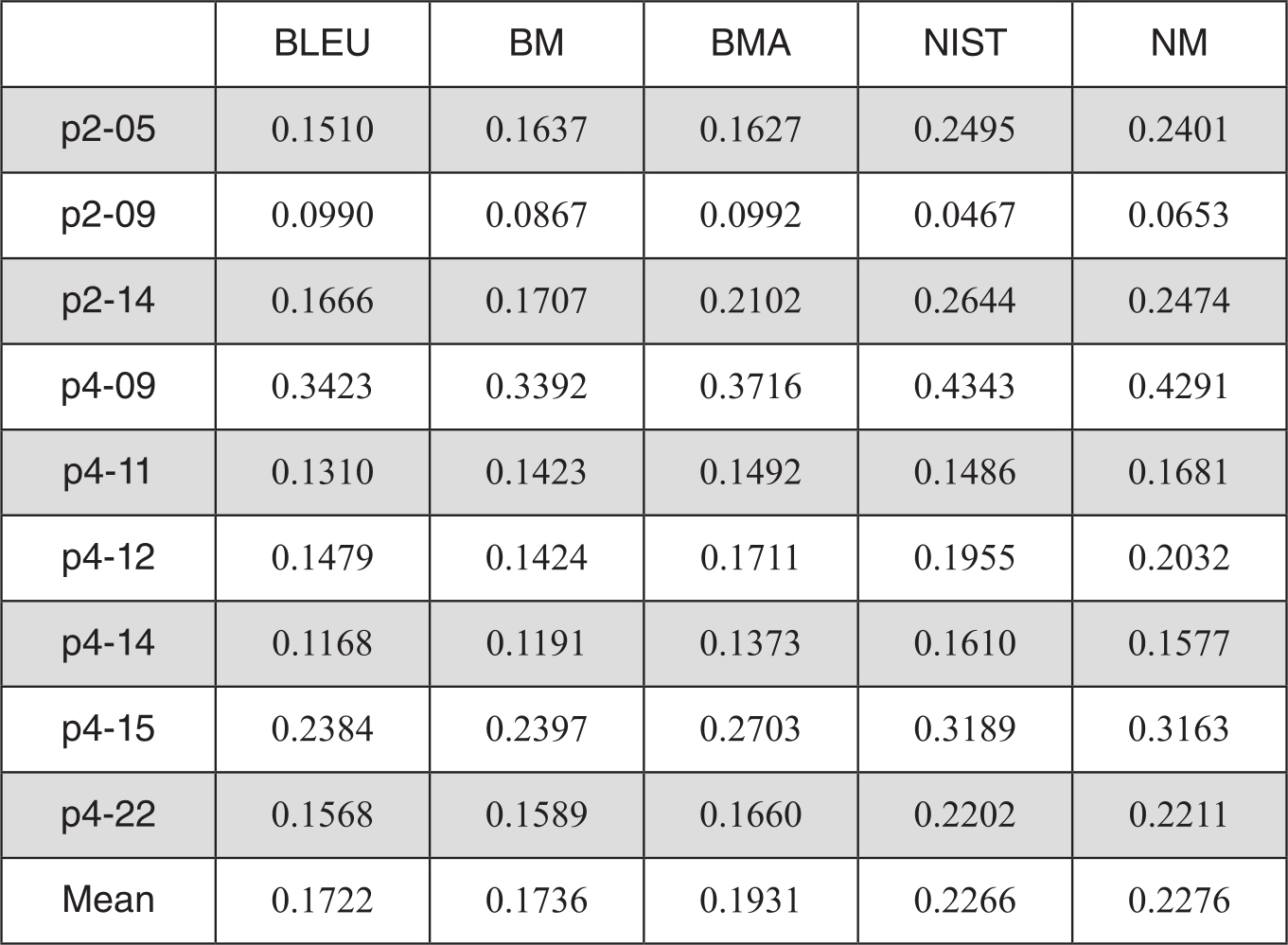
表3-15 BLEU和NIST文档级准确度评测对比结果
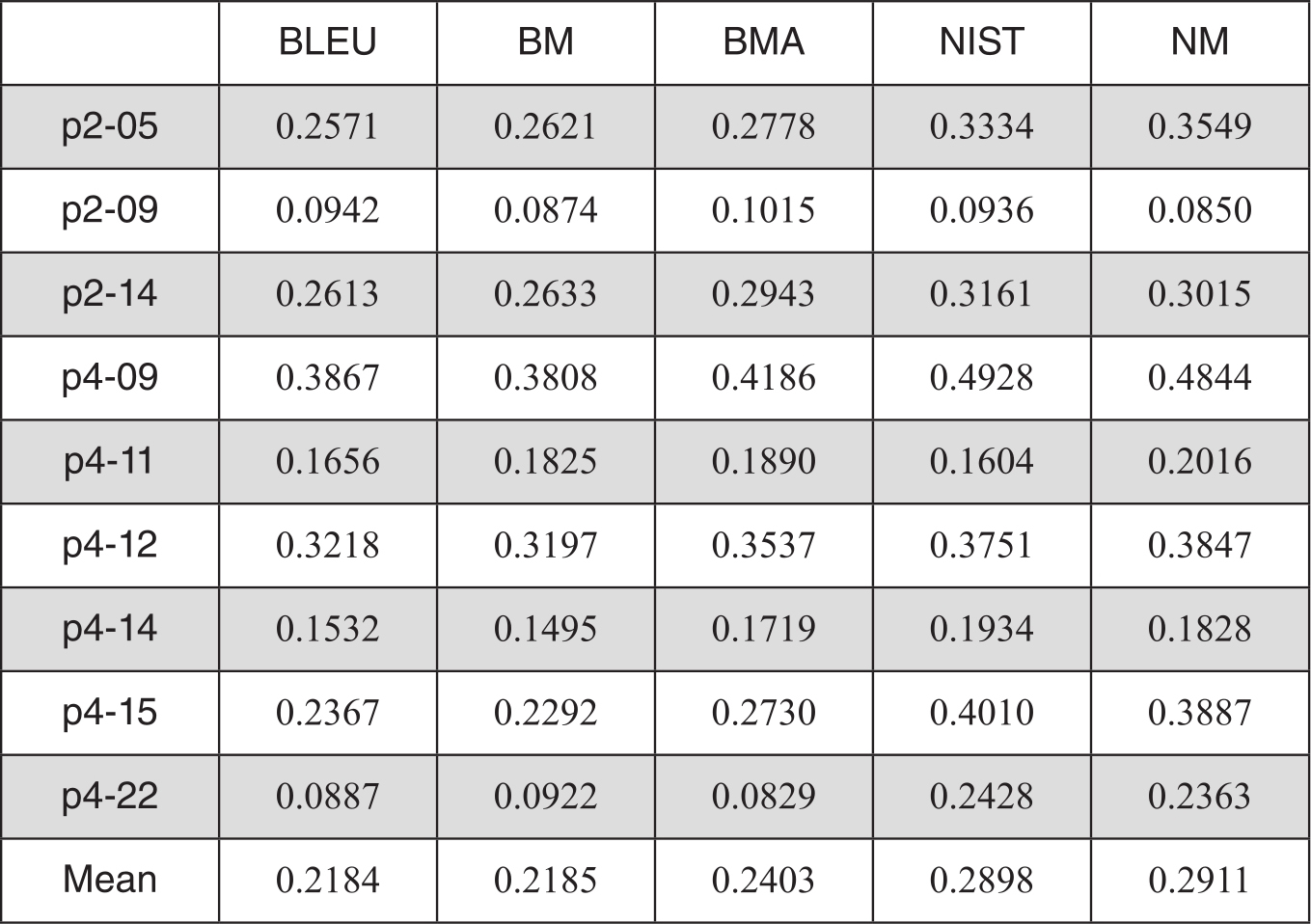
表3-14的数据显示,在流利度评测中,BM算法在9个系统中有6个优于BLEU,整体均值也优于BLEU。采用了算术平均后的BMA比BLEU优势更明显,有17.4%的性能提升。与NIST相比,BMA不如NIST。但是NM的结果比不加修正的NIST要好,说明在文档级的评测中,我们基于多篇译文的修正算法仍然在奏效。而且在所有系统中,NM在流利度评测中是最优的。
表3-15准确度评测的表中可看出,BM、BMA和NM在不同系统的评测结果波动较大,整体优势不如在流利度上的评测那么显著。但是整体上NM仍取得了最好的结果。
· 句子级评测
对BLEU和NIST的修正在句子级评测的结果不尽人意,BM的结果略低于平滑后的BLEU,相关度平均差距在流利度上为4.5%,在准确度上为2.9%。尽管NM在9个系统中的4个评测中,流利度上胜出了NIST,但整体上略低于NIST,在准确度评测中也是如此。
对METEOR的修正也存在类似结果。具体数据显示在表3-16中。其中带+号的是加入修正因子后的结果。
表3-16 句子级评测-METEOR修正后的对比性能
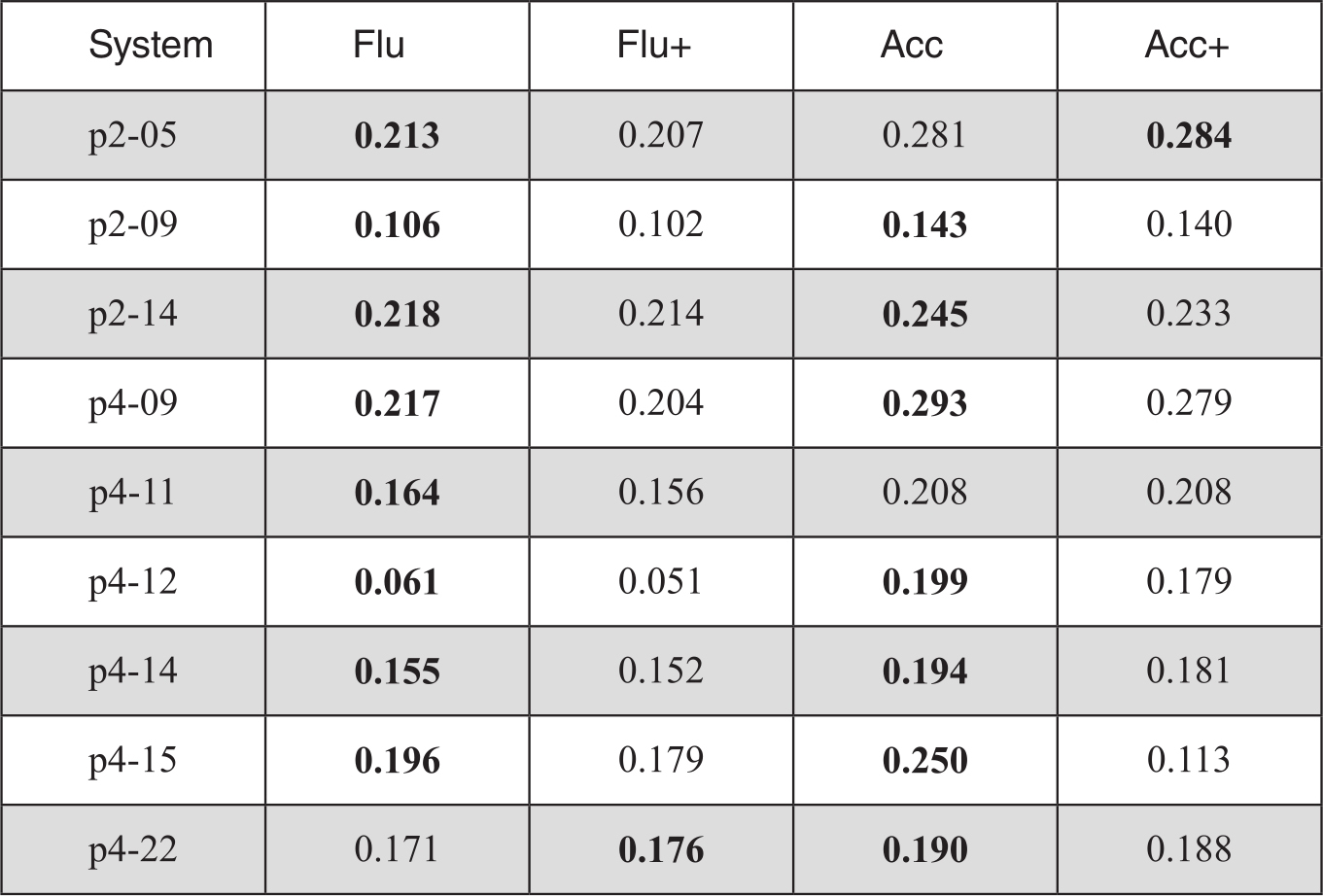
我们分析了其中的原因,可能存在多个方面:一是在句子一级的评测中,多篇参考译文的公共n-gram数目比文档级和系统级更加稀疏,修正因子并不能发挥正常的作用;二是平滑后的BLEU得分并不是基于实际匹配情况的得分,而是在没有匹配时的一种估计值,因此难以在一个估计分的基础上进行修正。三是实验的两个数据集中,参考译文的差异性很大。我们基于TER指标统计了两个数据集中的差距,发现两个数据集的TER平均值分别为0.72和0.67,说明四个参考译文之间存在较大的差异。数据稀疏问题在句子级十分严重。举例来说,“would”在四个参考译文中成为公共词的几率要大于实词“American”,因此可能被赋予更大权重的机会就较多,这与我们增大对公共实词的权重的初衷相违背。最后一点,也是十分关键的一点,实验用的两个数据集中人工评分在句子级的一致性很低,无疑也为自动评测算法的研究增大了难度。
(四)更多的讨论
· 流利度评价和准确度评价
考虑了公共n-gram在多篇参考译文出现的特征,在系统级和文档级的评测中,我们的修正因子均表现了较好的性能,比原始的BLEU和NIST的评测性能都优。其中也发现,在流利度评测性能提升似乎比准确度评测性能的提升更明显。为此,我们以MP2数据集为例,深入观察和分析了多篇参考译文中公共n-gram的情况。以一元组unigram为例,只出现在一个参考译文中的单词占48.7%,出现在两个参考译文中的单词占17.8%。随着n-gram中n的增大,被不同译文共有的n-gram数目急剧下降。公共ngrm的变化情况如图3-18所示。在四元组中,91.86%的单词出现在一篇译文中,而出现在所有4篇参考译文的只占0.24%。
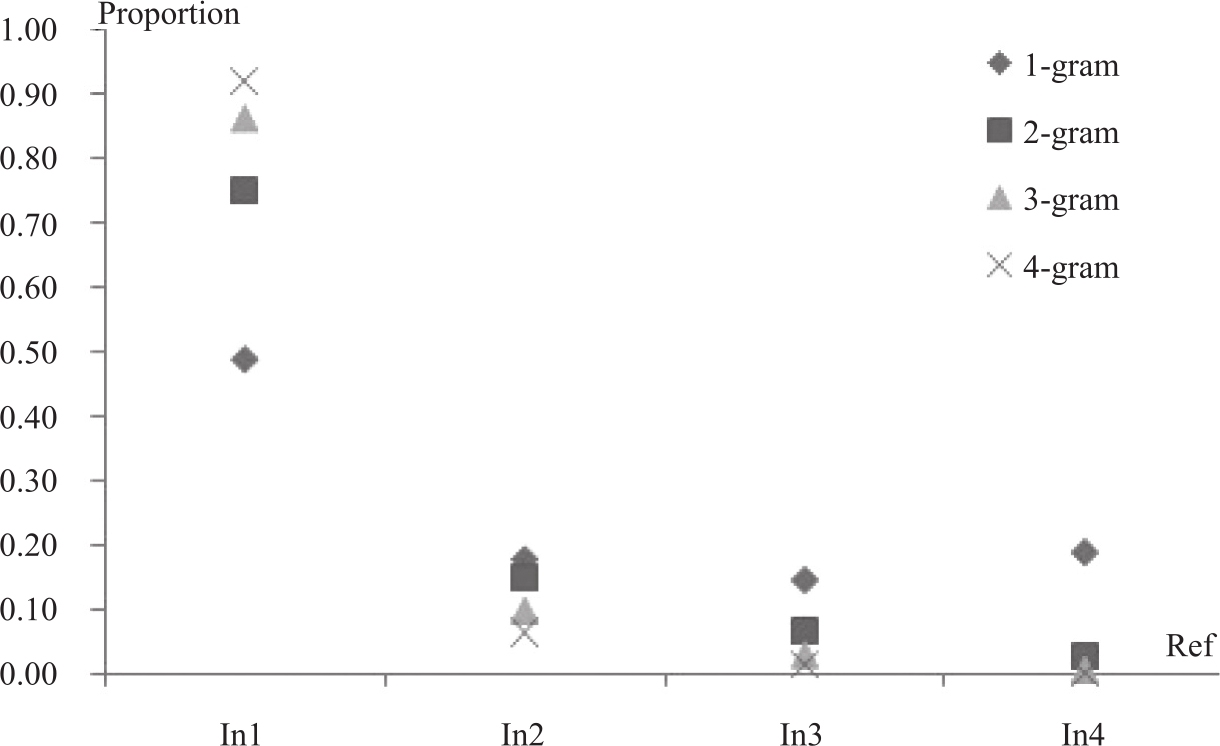
图3-18 MP2数据集中的公共n-gram
其中inX表示出现在X篇参考译文中
另外,我们还分析了机器译文和参考译文匹配上的公共n-gram的情况。以P2-05系统为例,除了一元组外,其他n-gram数目都随着参考译文数目的增长而降低。在匹配上的一元组中,20%的单词只出现在一篇译文中,17%的单词出现在两篇译文中,22%的单词在三篇译文中都出现过,而41%的单词是4篇参考译文中都出现的。图3-19显示了P2-05系统n-gram匹配率的分布情况。注意到这些数据中有个奇怪的现象,匹配的出现在所有参考译文中的unigram数目比只出现在1-3篇参考中的数目还多。仔细分析发现,这些unigram主要是英文的功能词和标点符号。也就是说,我们对于标点和功能词增加了权重,而这是不利于评价译文准确度的,尤其是在句子级的评测中。另一方面,有大量的高级n-gram出现在多于一篇参考译文中,这一点能够解释为何流利度评测性能有所提升。
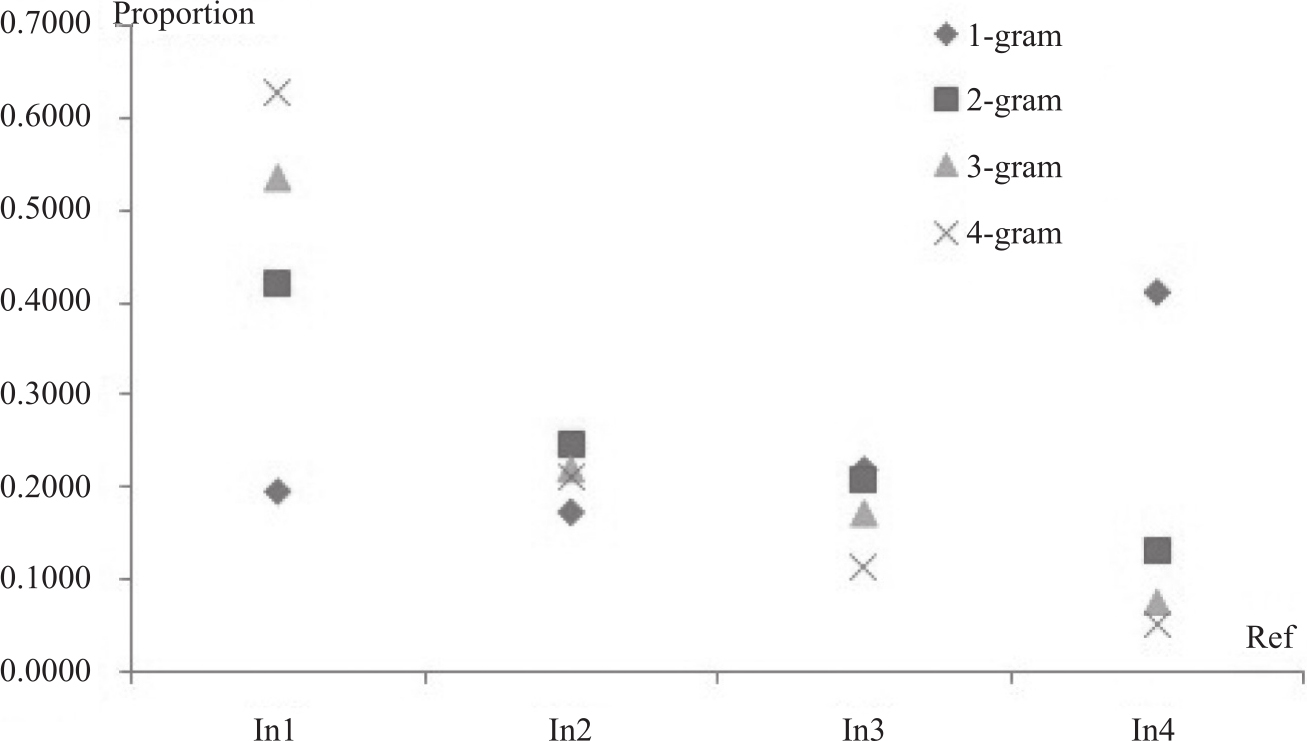
图3-19 P2-05系统匹配n-gram的分布
· 实词构成的n-gram
为提高在译文准确率评测上的性能,我们还借鉴齐夫定律构造了另外一个修正因子,以期能降低功能词的影响,增加对实词构成的n-gram的权重。在系统级评测中,这个修正因子能够提升准确率的评测性能,但在文档级和句子级评测中,性能下降严重。看起来似乎没有绝对优势的加权方法能区分功能词和实词,至少在我们实验数据集上的结论是如此。
· 参考译文数目的影响
实验中,我们选用的数据集包含4篇人工参考译文。实际上,对应同一篇原文的译文可能非常多。我们需要进一步考察修正的加权算法在更多参考译文上的表现。根据修正因子的表达式,当参考译文数目增大时,会提高公共n-gram的加权率。比如,一个二元组在10篇参考译文中出现了两次,修正因子为0.3424,如果只出现一次,修正因子为0.3222。然而,如果只有4篇参考译文,这两者之间的比率为0.3979/0.3522,比前者要小。也就是说,参考译文越多,修正的影响越小。
经过上面的研究,我们可以进一步得到以下结论:尽管不能穷尽所有正确的译法,但通过对同源译文在语法、搭配、语义结构等更抽象层面共性的分析,可以深入探索影响译文质量的内在要素,突破基于浅层比较评价译文质量的局限,研究超越语言形式的译文质量评价方法。