5.3 词汇短语的错误检查
检查译文中词汇错误一般基于词汇的后验概率计算该词的信度(confidence)。译文中词汇短语错误检查主要分为两步进行:
首先根据统计翻译系统的翻译模型和语言模型获得词汇翻译正确的有关特征,如N-best词表、词汇网格(word lattices)等。
第二步是将这些特征加入到各种分类器中,实现对单词翻译结果的分类:正确还是错误。
关于词汇翻译特征的研究有很多,Xiong et al.(2010)将两类语言特征融合到最大熵分类器中识别译文中词汇的翻译是否正确,一类是词汇特征,一类是句法特征。词汇特征主要有词汇本身和单词的词性(由自动标注工具标注)。最大熵模型中用到了当前词前面和后面的n个词的单词和词性特征。句法特征通过句法分析得到,句中不合法的句法分析部分有较大的可能性存在错误。为避免不合理的部分导致自动句法分析的崩溃,Xiong et al.(2010)利用了链语法(Link Grammar)(Sleator & Temperley,1993)分析器获得句法分析的结果。该分析器目前也是开源使用的,链接地址为:http://www.link.cs.cmu.edu/link/。
一个例子:用链语法分析句子:
A tax on income increase may be necessary
链语法分析结果如图5-5:

图5-5 链语法分析的结果
图中出现了多个“断链”,也就是存在无法正常链接的语法成分,这些断链就是可能存在语法错误的地方,如图中a tax。这种信息被作为分析译文中错词的一种特征函数的输入部分。
设单词w的特征向量表示为ψ,比如{wd,pos,link,dwpp},对应的特征函数的例子如下:

根据最大熵模型中条件概率的计算式(5-4),就可以求得给定特征情况下单词的分类结果(正确还是错误):
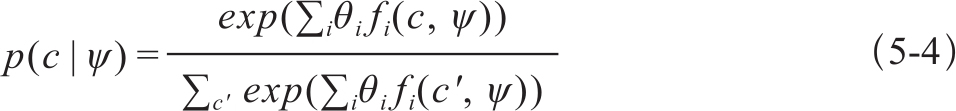
如果p(correct|ψ)>p(incorrect|ψ),单词就识别为正确的翻译,否则为错误。综合所有特征后,他们在实验数据集上的最佳词汇错误检查的准确率为59.89%,召回率78.94%,F1值为68.10%。