3.1.1 基于n-gram的相似度
一、BLEU算法
BLEU即BiLingual Evaluation Understudy的缩写,是翻译自动评价中最经典的算法(Papineni et al.,2002)。BLEU的影响是划时代的,尽管在此之前也有类似的做法。当前BLEU仍作为WMT机器翻译评测的一个基准(benchmark)指标。BLEU算法的基本假设是,如果待评译文和参考译文共现的n元组(n-gram)越多,说明越相似,译文质量就越高。算法通过统计待评译文与参考译文共现的n-gram的比重,并增加对过短译文的惩罚因子,计算出译文的质量得分。如果存在多个参考译文,待评译文的n-gram和任意一个参考译文的n-gram匹配即可。BLEU得分的计算式很简单,如式3-1所示:
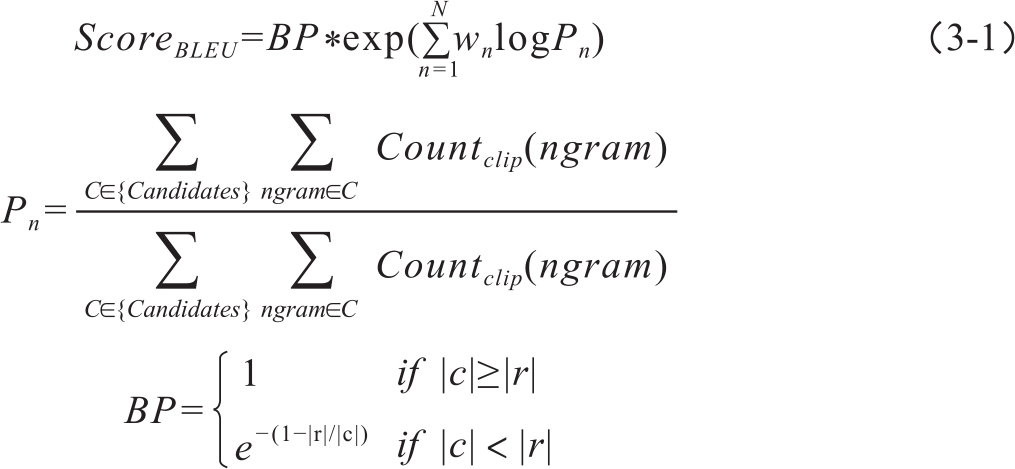
式中,wn为n-gram的权重设置,通常设为最大n值的倒数,即1/N;Pn表示n-gram钳位匹配率。钳位的意思是,匹配的n-gram的最大数目不能大于参考译文中该n-gram的最高出现次数,以防止测试译文作弊。BP是对长度小于参考译文的惩罚因子,|c|和|r|分别代表待评译文和参考译文的长度。可见,当机器译文长度小于参考译文时惩罚因子才起作用。BLEU允许基于多篇参考译文进行评测,与待评译文最接近的参考译文长度被定为公式中的参考译文长度。
举例说明BLEU得分的计算方法。下面例句(1)中Ref1-4表示4句参考译文,Sys是机器系统的译文:
(1)
Ref1: The gunman was shot to death by the police.
Ref2: Police killed the gunman.
Ref3: The gunman was shot dead by the police.
Ref4: The gunman was shot to death the police.
Sys: Gunman is shot dead by police.
根据BLEU公式,可得|c|和|r|分别为7和7.75,惩罚因子BP=0.9。n-gram的最大数取到4,也就是unigram到4-gram的权重都为1/4。最后可得本句译文BLEU得分为0.3217。
二、BLEU算法的变种
(一)平滑BLEU
BLEU采用机械的匹配策略计算系统译文和参考译文的相似性。我们知道,语言中出现连续相同的多个词汇的几率很小,译文中也存在严重的n-gram稀疏问题,尤其是匹配大于bigram的情况变得十分少见。再由于BLEU计算的是匹配n-gram的几何平均值,因此经常出现得分为0的情况。在句子一级的评测中,为0的得分更加普遍。为此产生了平滑BLEU(Smoothed BLEU)算法,可以有效防止BLEU得分为0的情况发生。平滑的方式有多种(Chen & Kuhn,2011),如:
· 小正数平滑:当匹配n-gram的数目为0时,用一个小正数替代0。小正数一般取0-1之间的一个经验值。
· 加1平滑:对于n大于1的元组,统计匹配数目时,分子分母均多加1,这样Pn都不会出现0值。
· 等比数列平滑:该方法在目前官方公布的BLEU评测程序mteval13中使用。对于匹配数为0的n-gram,依据一个初值为1/2的等比数列进行平滑,比如从二元组bigram开始匹配数为0时,依次设置二元组、三元组、四元组的匹配数为1/2、1/4、1/8……,然后再按照公式计算得分。
在Chen & Kuhn(2011)的研究中,还讨论了其他4种平滑方法用来处理BLEU得分,使之不出现为0的值。但这些平滑措施并不能从根本上改变n-gram机械方式评测译文质量存在的缺陷,只能对未匹配的n-gram给出大致的估计,不能反映实际语言的情况。
(二)MBLEU、EBLEU和AMBER
为克服BLEU的机械匹配问题,产生了很多改进研究工作。比如,MBLEU中加入了英文的词形还原(stemming)处理,并借助Wordnet的同义词信息使得匹配更加宽松,以便能发现译文和参考译文中具有相同词根的词和意义相近的词(Agarwal & Lavie,2008)。这种改进对于英语来讲,能够比较明显地提高评测的性能,但在法语、德语上的实验效果并不佳。当然对于没有词形曲折变化的语言来说,比如汉语,这个改进更不起作用。
EBLEU则是从惩罚因子方向对BLEU进行的改进(Han et al.,2013)。BLEU中仅对译文长度小于参考译文的情况采用了惩罚因子,EBLEU则对过长和过短的译文都增加了惩罚因子,修改后的惩罚因子MLP表达式为:
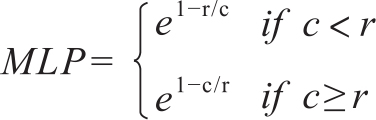
同时将匹配n-gram的准确率和召回率的调和平均值作为权重。
针对惩罚因子的改进,Chen & Kuhn(2011)更是进行了深入的探索,提出的AMBER评测方法中设置了10种惩罚因子,每一种惩罚因子人工赋予不同的权重;并且采用了包括固定间隔n-gram、不固定间隔n-gram、skip-gram等在内的四种n-gram匹配策略;有八种类型的文本作为输入,包括原文、词汇化和小写处理、词形还原、词后缀、分割词汇、长度大于4个字母的词等,可谓是对BLEU算法中惩罚因子的极致改进。
BLEU算法是一种与语言无关的评测,无论哪一种语言都可以将测试译文和参考译文进行形式比较,而且评测效率很高,允许参照多篇参考译文。这是BLEU的优势。另一方面,对BLEU的质疑也从未间断,主要包括:
(1)BLEU忽视了句子的语法结构,仅从局部内容的匹配角度评价翻译质量,而且有研究表明BLEU算法对机器译文存在高估的现象,尤其是青睐基于统计的机器翻译结果,而不能区分基于规则的、基于记忆的翻译系统以及人类译文之间的细微差别。
(2)BLEU得分的意义难以解释,因为多方面因素都会影响得分,如不同的领域、参考译文的数目、不同的语言对等等,所以,人们不清楚BLEU得分23.4意味着怎样的翻译质量,也不能肯定得分为25的译文就一定比23的译文要好。
(3)当n-gram为unigram时,匹配的词汇能更多地反映语义的相似性,当n值越大,匹配的词序列能从流利度上反映译文的质量,因此BLEU声称能从准确度和流利度两个角度评价译文质量。实际上,流利度评价比准确度评价更难,尤其是高阶的n-gram实际语言中极少重复出现,因此BLEU中利用最多的是词汇匹配。
三、NIST算法
NIST算法1与BLEU的产生时间差不多。NIST算法中认为与参考译文匹配的n-gram承载不同内容,比如虚词构成的n-gram和实词构成的n-gram对译文的质量影响就有较大的差异,因此不应给予相同的权重。算法提出了信息值(information value)的概念,增大了在译文中出现次数较少的n-gram的权值(Doddington,2002)。根据Zipf定律,虚词的频次远远高于实词,因此那些多次出现的n-gram往往携带的信息量较小。
NIST得分计算公式如式3-2:
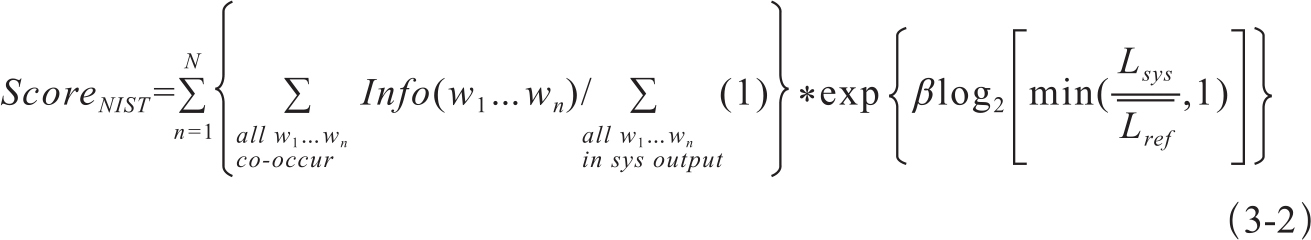
其中,
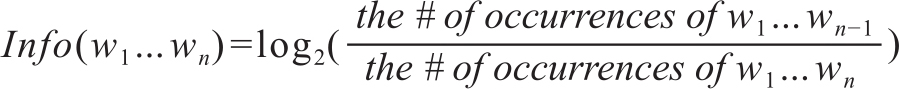
为信息值,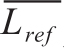 为参考译文的平均长度,Lsys为系统译文的长度,β为惩罚因子。
为参考译文的平均长度,Lsys为系统译文的长度,β为惩罚因子。
根据上式计算BLEU算法中提及的例句(1)的NIST得分为2.8867。可见NIST得分不是一个位于0-1之间的分值。另外,NIST由于对匹配n-gram采取了算术平均而不是几何平均,因而没有得分为0的问题。根据Doddington(2002)的研究,NIST在与人工打分的相关度上要优于BLEU算法。在多篇参考译文存在的情况下,简单增多参考译文并不能提高这种基于匹配策略的评价算法的性能,一般情况下,4篇参考译文就足够了。同时还指出,NIST和BLEU两种算法都不能区分译文之间的细微差别,尤其是人工译文之间的差异。
BLEU和NIST算法都有公开的评测程序可从网站下载,下载地址:ftp://jaguar.ncsl.nist.gov/mt/resources/mteval-v11b.pl。该版本为Perl语言编写的评测程序。