7.1.2 生成文摘质量的评价方法
这里说的评价是从整体上评价自动文摘系统,而不是从文摘各个步骤分别评价。评价分为外部(extrinsic)评价和内部(intrinsic)评价。以下是经典的自动文摘评价算法。
一、ROUGE-N
最常用的一个内部评价算法称为ROUGE-N(Lin,2004)。评价文摘质量的思路是通过和人工摘要比较,根据相同的n-gram数目计算文摘的得分,ROUGE-N的通用计算公式如7-2。
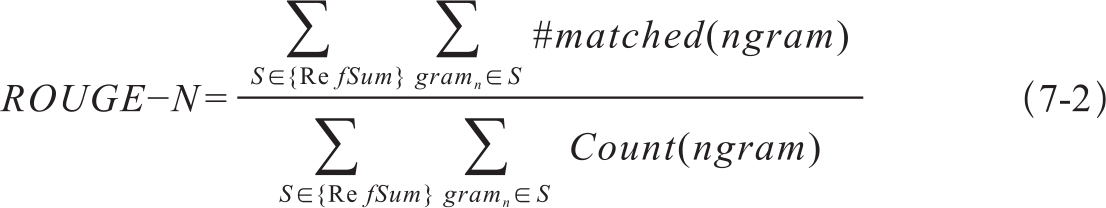
式中分母是参考文摘的n-gram数目,分子是生成文摘和所有参考文摘匹配的n-gram数目,因此,Rouge-N是生成文摘与参考文摘共现的n-gram数目之比。可见ROUGE评价指标是一个基于召回率的评测指标。n-gram的长度通常固定,如ROUGE-1比较的是unigram的相同率,ROUGE-N比较的就是长度为N的n-gram的重叠率。替换n为不同的值可得到不同n-gram的ROUGE得分,如bigram的ROUGE的计算公式为7-3:
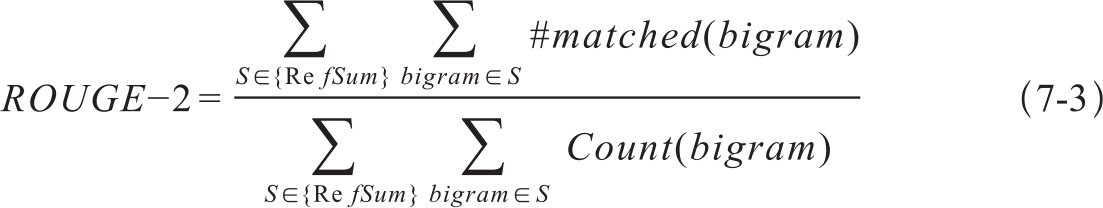
同翻译一样,针对同一篇文章的文摘也是多样的,并不唯一。ROUGE算法在针对多篇参考文摘的情况下,采取了将生成文摘和所有参考文摘逐一两两比较的方式,取其中得分最高的作为最终得分。同BLEU和METEOR算法的做法一样,ROUGE也没有考虑到多篇参考文摘的共性特征。
二、ROUGE的其他变化
ROUGE指标的其他变化还有ROUGE-L、ROUGE-W、ROUGE-S。
(1)ROUGE-L是基于最长公共子序列(Longest Common Subsequence,LCS)的匹配率计算生成文摘质量的算法。将生成文摘和参考文摘视为两个字串,生成文摘和参考文摘匹配的公共子串越长,说明越相似。ROUGE-L方法不用实现固定n-gram长度,匹配内容更加灵活。设参考文摘为X字串,长度为m,生成文摘为Y,长度为n,LCS(X,Y)表示最长公共子串长度,可计算出召回率、准确率和带可变参数β的F值:
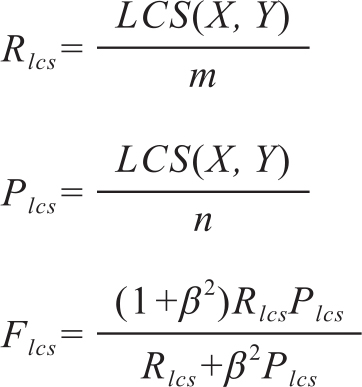
可变参数用于调整最终结果更倾向准确率还是召回率。ROUGE-L匹配LCS按照从左到右的顺序,当匹配上一种序列后,就不再匹配其他序列,而且容易忽视更短的词汇匹配,这两点是ROUGE-L的不足之处。
(2)ROUGE-W是依据LCS匹配位置信息增加权重的算法,权重由一个函数f给出。这个函数能为更长的连续匹配赋予更大的权重,也就是要满足对于任何位置整数x,y,都要满足:
f(x,y)>f(x)+f(y)
在Lin(2004)的文献中,选择了函数和反函数为封闭类的函数,如f(k)=k2,以便于结果的归一化。这样,ROUGE-W的F值计算方法为:
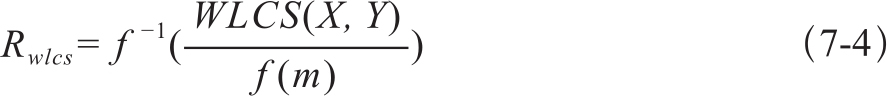
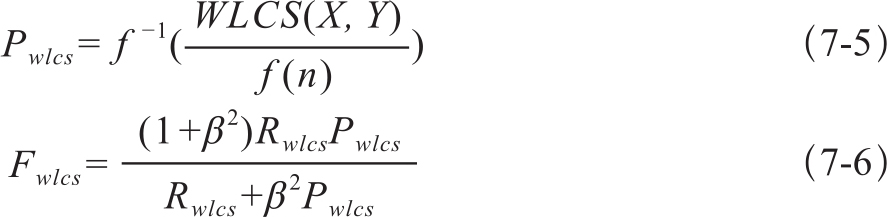
其中,两个字串的加权最长公共子串WLCS(X,Y)是利用动态规划算法求得的。
(3)ROUGE-S是基于skip bigram匹配率的算法,允许任意两个词构成的bigram进行匹配,并不要求两个词位置连续。这样ROUGE的计算式中分子部分变为了生成文摘和参考文摘中任意两个词的匹配数目,分母部分是一个组合函数。即:
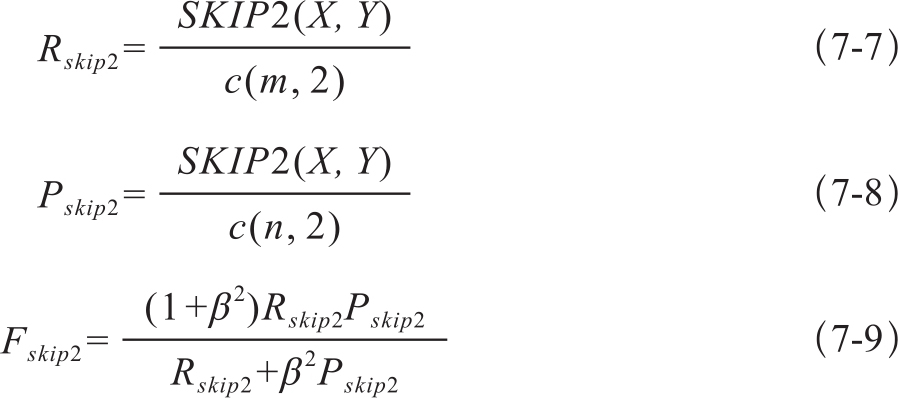
如果没有匹配的bigram,ROUGE-S的扩展版本ROUGE-SU还可以计算完全逆转后的字串匹配情况。
尽管ROUGE指标被广泛运用到自动文摘的评测中,而且和人工评测的结果也有较高的相关度,但是由于人工文摘有很大的差异性,使得自动文摘和参考文摘的匹配率很低。