第3章 译文质量自动评价方法
译文质量的人工评价是传统的衡量译文质量优劣的方式。近年来译文质量自动评价研究得到充分的重视,研究的驱动力来自机器翻译研究的蓬勃发展。在系统研发过程中,需要不断评测和对比系统输出的译文质量,而人工评价译文不仅效率低,代价高,而且存在难以避免的主观性问题,评价者内部一致性和外部一致性都普遍较低。这些不利因素促使了自动评价方法的研究。
译文自动评价通过运行评价软件得到译文的质量评测结果,具有快速、廉价、客观的特点。自动评价在快速发现译文中的错误、调节翻译系统的参数、对比系统性能等方面具有人工评价不可比拟的优势。图3-1形象地描述了翻译评价在机器翻译开发周期中的位置和作用。
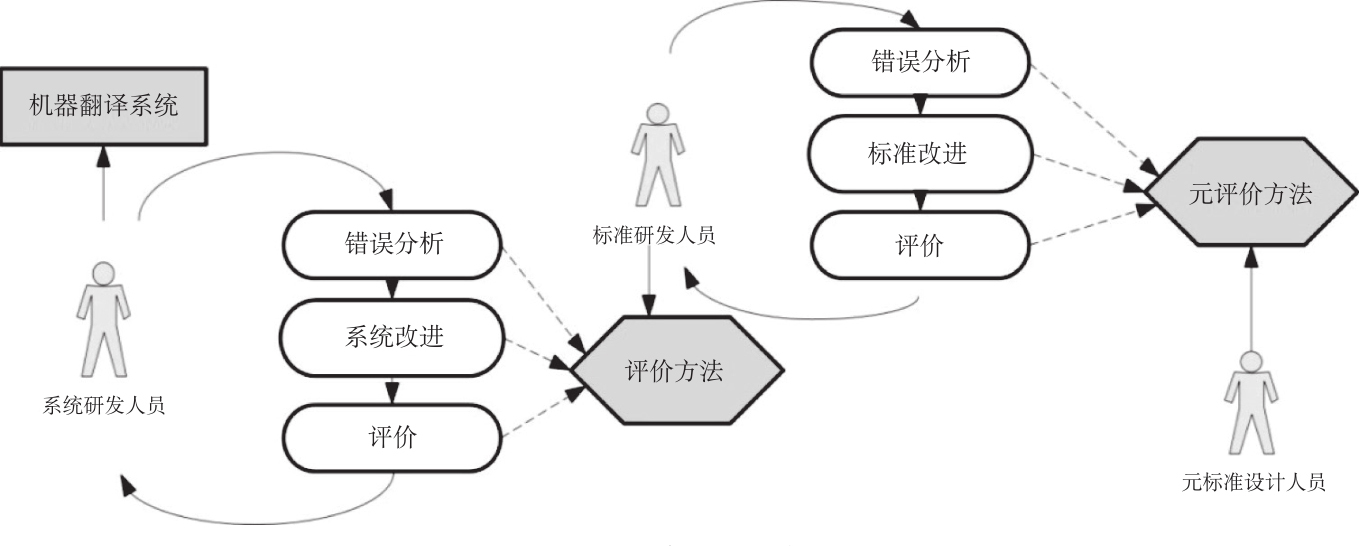
图3-1 机器翻译开发周期图
2010年,计算语言学协会(Association for Computational Linguistics,ACL)首次将翻译评价标准(metrics for machine translation)、机器翻译、系统整合一起列为机器翻译研讨会议WMT的三大任务,为各国在共同的平台上研究自动评测方法提供便利。
整体上,自动评价研究尚处于“诸子百家”的时代。先后出现过几十种算法,也有很多开源的评测工具,但是自动评测和人工评测的相关度还不够高,WMT中最终翻译系统的性能仍依赖人工的评价。
机器译文自动评价出现过三类评价方式:质量评分(scoring)、诊断性评价(diagnostic evaluation)和质量排序(ranking)。从实现评价的思路上看,也主要有三种:一是将机器译文和人工参考译文比较,基本观点是:与参考译文越相似的机器译文质量越高,这也是最广泛采取的做法。二是不依赖人工译文的质量估计,通过提取译文的各种特征,结合机器学习模型,判定机器译文质量优劣的信度,这样质量估计就被视为了分类任务,用分类器进行译文质量的预测。三是通过关键语言点的翻译情况评测译文的质量。译文评测的形式主要是质量打分和优劣排序。
本章将对已有的三类自动译文评测方法进行全面详细的介绍。