7.3 图像描述文本的质量评价
图像描述文本生成是机器视觉(Computer Vision,CV)研究的一个方向,属于多模态(multimodal)信息处理任务的一种,将图像识别和自然语言生成(Natural Languge Generation,NLG)技术融合在一起(kuznetsova et al.,2012)。
NLG是把非文字表述的内容转换为人类可读的文本的技术,通常包括三个实现步骤:首先是表达内容的选择(content selection),然后是内容的组织(content planning),最后是言语形式的实现(surface realization)。
机器自动生成的描述图像内容的文字主要有两类,一个是生成图像的标题(Vinyals et al.,2015),另一种是用一个句子描述图像表达的主要内容。如果是句子描述就有是否流利和符合语法表达习惯的问题,也需要对描述文本进行质量评价。人工评价图像生成文本的质量,通常采取分级表格(likert scale)的形式,在不同规模的测试组和测试数据集上设计包含类似下面内容的问卷,并分为若干级别。
· 该文本准确描述了图像的内容
· 该文本语法正确
· 该文本没有不正确的信息
· 该文本结构正确
· 该文本与人工描述类似
和代价很高的人工评测方式相比,近年来的自动图像文本质量评价方式也成为新的热点研究方向(Bernardi et al.,2016)。2015年在MS COCO Captions Challenge大会期间组织了第一届大规模图像描述文本评测。除了利用经典的BLEU、NIST、ROUGE和METEOR评价图像描述文本的质量外,也有视为信息检索任务而利用排序、准确率和召回率等指标的,也有CIDEr(Vedantam et al.,2015 )、SPICE(Anderson et al.,2016)、Word Mover's Distance(WMD)(Kusner et al.,2015)等针对图像描述文本而构建的评测方法。测试中也发现,BLEU、NIST、ROUGE这些评测方法和人工评测的结果相差很大,而且波动性大。图像描述文本的质量评价有其特殊性,如不同人给出的描述文字内容可能有较大的差别,完全相同的词较少,而同义词和近义词较多,词序变化较大等。
下面以CIDEr为例介绍图像生成文本的质量评测方法。CIDEr(Consensusbased Image Description Evaluation)(Vedantam et al.,2015 )是一种图像文本质量的一致性量度,衡量自动生成的图像描述文字和人工给定的文本的相似度,包含了语法、显著性、重要性、精确性层面的相似度比较。算法如下:
设图像数据集合为I,第i个图像Ii∈I的生成描述句子为ci,si={si1,si2,…,sim}是人工给的参考文本集。所有的词汇进行了词形还原处理,得到词根部分。每一个句子表示为n-gram集合ωk,文献中n值取到4。算法统计生成的描述句子和参考描述之间共现的n-gram,同时考虑到在多个描述句子中都出现的可能是功能词,因此借用了TF-IDF的思想为共现n-gram加权。n-gram ωk出现在参考文本句sij中的次数记为hk(sij),出现在生成句中的次数记为hk(ci),那么ωk的权重计算式如7-10:
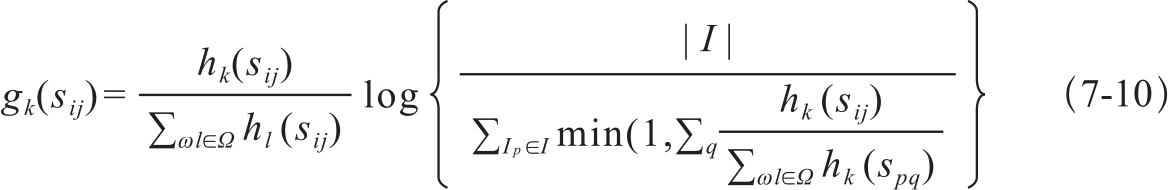
式中,Ω表示全部n-gram的集合。通过TF-IDF的加权,TF部分可以对多次出现在参考文本句子中的n-gram增大权重,同时IDF又可以削弱多次出现在数据集中其他参考文本句子中的n-gram。CIDErn的得分为7-11:
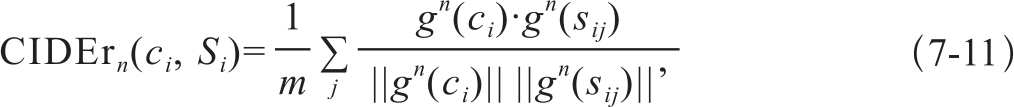
其中,gn(ci)是一个由所有长度为n的n-gram对应的gk(ci)构成的向量。||gk(ci)||是向量gn(ci)的大小。最后加权综合各级n-gram的结果得最终CIDEr得分如式7-12:
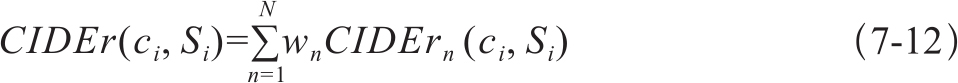
他们构建的包含50个参考描述句的两个测试数据集,性能明显一致优于ROUGE和BLEU,精确度达84%。这种对n-gram的加权做法可以借鉴到译文质量评价中。