8.2 基于语义的质量评价
对原文的理解是人工翻译的第一步,首先要更准确地把握原文的语义才能对译文实施正确的评价。人工评价译文质量尚可以要求做到这一点。自动评价要能达到人工评价的结果,也需要从语义层面上进行。那么什么是语义?
人们对于语义的直觉理解是多方面的,比如(1)同义:两个表达方式的意思相同或相近;(2)相对:两个表达方式的含义不能同时都为真,也就是常说的反义;(3)蕴含:一个句子的意思包含在另一个句子里;(4)不合乎常规:根据常识,语义表达不清楚或者不合乎常理;(5)歧义:一种表达有多种含义,歧义可能来自词汇(多义词)、结构(对应多种句法分析结果)、范围(修饰词的修饰范围)等原因。这些语义来自人的个体感受。
语义研究有很多的视角,如参照方法(Referential approach)、表征性/心灵主义的方法(Representational/Mentalistic approaches)、社会/语用学的方法(Social/pragmatic approaches)等。不同的视角并非互不相容。自然语言理解和处理的主要任务不是探究语义的本质,而是关注如何表示文本并用于实现某些应用的目的,例如翻译、问答等。下面介绍的语义都与计算语言学相关。
一、语义的组合原理
人可以产出和理解无限多不同的句子,但这似乎不是通过记忆完成的。人是如何做到的?其中比较有影响力的说法是德国哲学家和数学家Gottlob Frege的组合理论(principle of compositionality),即:整体含义是其部分语义和组合方式的函数(The meaning of the whole is a function of the meanings of its parts and their mode of composition)。一个句子的语义是由句子中的词的语义以及词的组合方式决定的,其中一种组合方式就是句法结构。
二、语义的表示
已有多种语义表示的方法,其共性是借助一组符号和符号间约定的结构表达含义。经过特定的设计,这些符号结构和对象、对象属性、对象之间的关系建立了对应。常见的语义表示方式有:一阶谓词逻辑(First-order logic)、语义网(Semantic Network)、概念依存图(Conceptual Dependency Diagram)、框架结构(Frame-based structure)。
多数语义表示的只是字面含义(literal meaning),即一种静态语义,不反映在特定语言环境中的语义,其实就是换了一种表示知识的符号体系。目前这个变换还依靠人工完成。因此,从计算机角度来看,仍然没有独立分析语义的功能。表示可计算语义的基本要求是:
· 可证实性(verifiability):也就是能够判定表示的真伪
· 无歧义性(unambiguous):即只有一种表示。无歧义和语义模糊(vagueness)不同,模糊是因为不够具体,比如“我想去餐馆吃饭”。具有模糊性是因为不明确具体位置
· 形式规范性(canonical form):相同语义要有相同的表示形式
· 推理和变量(inference and variables):基于语义表示及知识库能够得到合理的结论,就是支持推理。推理过程包含可被替换的变量,能够满足更多表示需求
· 可表达性(expressiveness):一种语义表示体系能够表示宽泛的需要表达的语义
三、词汇语义
词汇语义是目前语义研究最集中的部分。词汇语义(lexical semantics)研究词汇的语义关系,以及每个词汇不同含义之间的联系。词义是词汇研究最复杂的部分。不同语言有着不同的词汇概念体系,这些差异既有认知层面的,也有文化差异层面的。因此,从一种语言到另一种语言的翻译过程,词汇层面不存在完全的对等关系。这种不对等不仅出现在差异较大的语种之间,像是英语和汉语,即使是一个语系的语言也有很多差异,比如英法、英德之间也有大量的不对等词汇。
词位(lexeme)是一定书写形式和音韵的结合体。词汇表(lexicon)是词位的有限集合。词元(lemma)是用于表示词位的语法形式。如词形sing、sang、sung的词元都是sing。
词汇语义研究的是lemma的含义,不是词形。词义(word sense)是某个词含义的离散表示。如下面两个句子中的bank有相同的发音和书写形式,但是具有不同的词义,记为bank1、bank2等。这种情况称为同形同音异义词(homonyms)。
I deposited the cheque at my bank.
Fishing from the river bank is prohibited.
如果发音相同,但是书写不同,一般含义是不同的,这种词称为homophones,比如be和bee。但是如果字形相同,但是发音不同,被称为homographs,比如bass(鲈鱼)/bæs/bass(贝司)/beis/。
不同应用区分这些词汇的意义不同,拼写检查(spelling correction)和语音识别(speech recognition)中,可能更重视区分find和found,区分是two、too还是to,即区分homophones很重要;但文本发音中要区分homographs,比如不同意义的bass的发音;信息检索中,区分homonyms很重要,只有进行区分才能明确用户检索的bridge是“桥梁”还是“桥牌”。
homonyms是两个不同的词条,有不同的意义。与之相近的是同一个词有多个含义,即多义词(polysemy)。区分是homonyms还是polysemy并不容易,可以利用词源学的证据(etymological evidence)来区分,或者凭直觉区分词义相关性机会的大小。
区分一个词的多个意义也有难度,属于lexicographers的研究领域。一种简单的方法是,用连词连接该词的两个不同语境,如果不合理,就代表有不同的含义。例如:
Which of those flights serve breakfast?
Does Midwest Express serve Philadelphia?
*Does Midwest Express serve breakfast and Philadelphia?
第三个句子中将serve的两个对象并列在一起,出现了无法解释的意义,说明第一个句子的serve和第二个serve的意义不同。
四、词义之间的关系
词义之间存在各种关系,主要有:
(1)同义(synonymy):判断是否同义的方法之一,就是替换。如果一个语境下,一个词可以被另一个替换而基本不改变原语的意义,则认为它们是同义词。这里并不要求在所有语境下都能替换,只要一个语境即可。
(2)反义(antonymy):很难形式化的定义反义。反义可以是一个度量的两个极端,如long、short,big、little;可以是运动的不同方向,如up、down;可以是一个二值的状态,如dead、alive;也可以是非二值的状态,如young、old,非二值状态可以加修饰语,如extremely big、very young。
(3)上位(hypernymy)和下位(hyponymy):一个是另一个的子类。如car是vehicle的下位词,mammal是cat的上位词。而表述各个概念之间关系的体系称为本体(Ontology)。
(4)部分整体(meronymy):用概念的一个方面指这个实体的其他方面或这个实体本身,两个意义之间存在有机的联系。如chicken既可以是鸡,也指鸡肉;bank可以是金融机构,也可以指银行的建筑。
Wordnet是词汇语义关系的数据库,它将概念相似的词组成synsets,不同的synset表示不同的概念。Wordnet目前有三个库:动词库、名词库、形容词及副词库。Wordnet 3.0包括了117,097个名词、11,488个动词、22,141个形容词和4601个副词。平均每个名词的词义有1.23个,动词的词义有2.16个。名词和动词的主要语义关系:
· 名词的语义关系有:
hyponym:从概念到子类划分,如meal-lunch
hypernym:从概念到上义词,如breakfast-meal
has-member:从组到组内成员,如faculty-professor
member-of:从成员到组,如copilot-crew
has-part:从整体到部分,如table-leg
part-of:从部分到整体,如course-meal
antonym:反义,如leader-follower
· 动词的语义关系有:
hypernym :从事件到上义事件,如fly-travel
troponym:从事件到子类,如walk-stroll
entails :从事件到事件涉及的内容,如snore-sleep
antonym:反义,如increase-decrease
五、词汇语义相似度
词汇语义相似度就是要计算两个词义的相近程度或者语义距离。词汇相似度问题在很多应用中都需要:在信息检索和问答系统中,需要寻找和检索词汇语义相似的文档;译文自动评分中,也需要确定译文和参考答案中相似的词。在上述语义资源建设的基础上,求词汇相似的方法有:基于同义词词典(thesaurus)的方法(如利用Wordnet)和基于词汇分布(distributional)的方法。
(1)基于同义词词典的方法
基于同义词词典的方法就是统计两个词之间连接的数目,语义越相似,距离越近。Wordnet中两个词被视为两个节点,之间的边的数目定义为两个词之间的路径。相似度定义为路径长度的倒数:
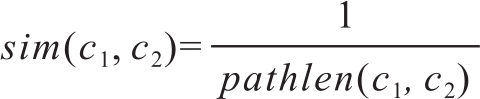
图8-1是Wordnet中一个片段,根据上式,这个层次结构词语之间的相似度如表8-1:
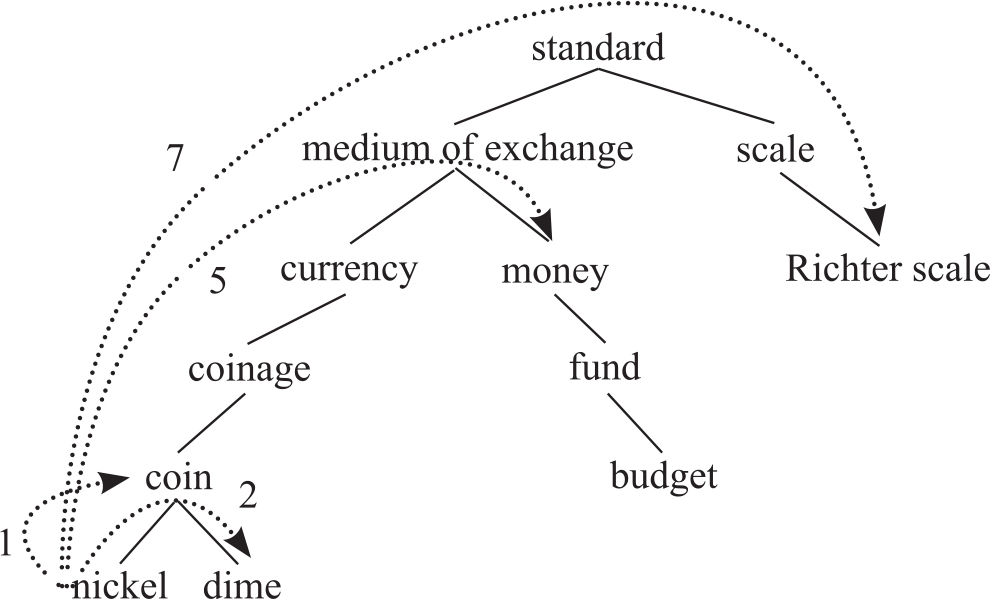
图8-1 WordNet词语之间的关系
表8-1 WordNet词语相似度
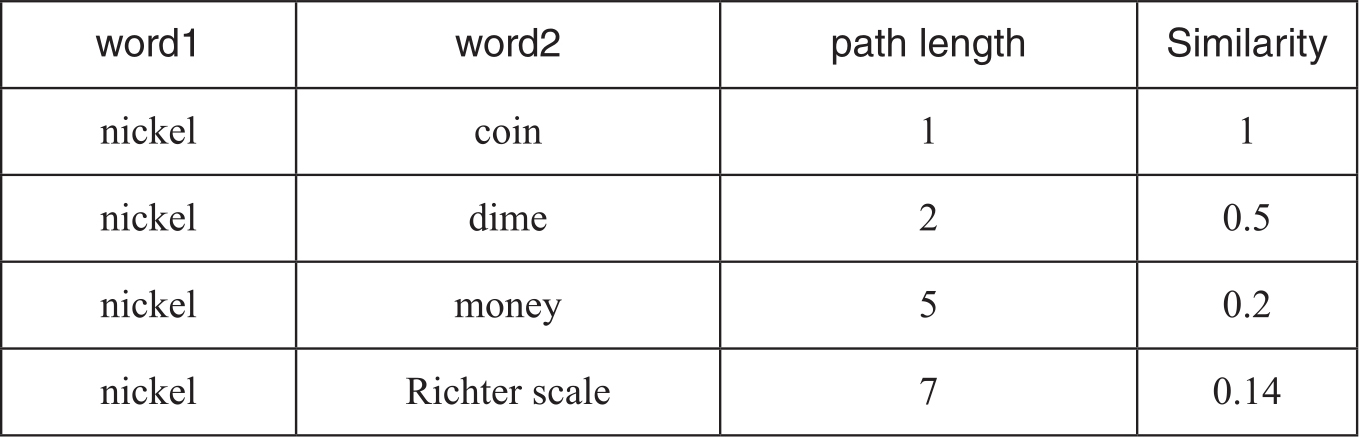
基于Wordnet路径长度计算词语相似度也有一些问题,所有边的长度都假定为1。上图中,nickel和coin似乎比medium of exchange和standard更相似,但是路径都为1。
相似度是以语义为基础的,不是词形。因此在许多应用中,计算两个词之间的相似度比区分词义更有意义,也就是在所有词义中,意义最接近的作为两个词的相似度。
(2)基于信息内容的方法
在词典中可以加入经验概率。词在语料中被看作是包含它们的概念的实例。P(c)用来代表一个词是某概念样例的概率,如式8-1。
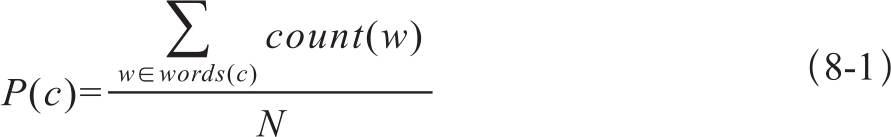
words(c)表示概念c包含的词构成的集合,N是语料中词的总数。可以得到Wordnet一个概念结构的概率如图8-2:

图8-2 Wordnet的概念结构图
很明显,越是一般性的概念概率值越高。
一个概念c的信息内容(Information Content,IC)的定义根据计算式8-2:
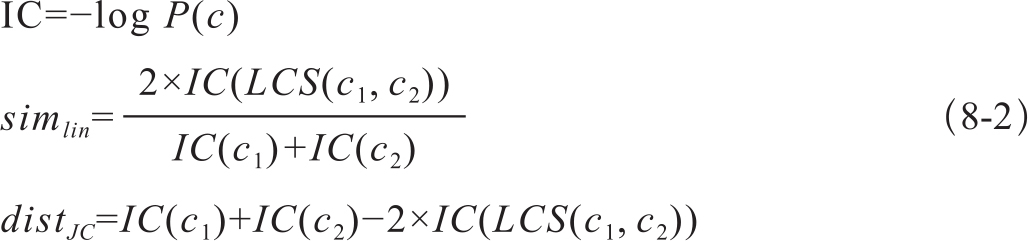
概率越大,信息内容越小。直观上认为,越是罕见的事物,其提供的信息量越大。这也正是信息论的内容。除此之外,还有多种常用的相似度计算方法,这里简单罗列供读者参考。
Resnik相似度:

Lin相似度:
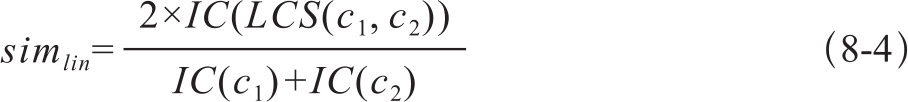
Jiang and Conrath距离:
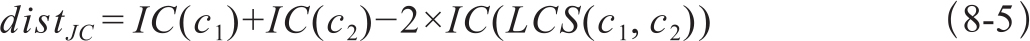
研究者们对语义的探索还在不断深入,真正从语义层面评价译文的质量的方法还在不断摸索中,第三章中我们提出的基于抽象语义表示AMR的译文质量评价方法就是其中的一项尝试。