3.2 无参考译文的质量估计
机器翻译评测中的参考译文一般都是语言专业人士给出的标准答案,这对每年进行的题材广泛的机器翻译评测任务而言,代价是昂贵的。在没有人工参考译文的情况下,为了有可以参照的翻译结果,也有研究者将若干机器译文生成伪参考译文(pseudo reference),作为质量较高的译文替代人工翻译,然后再采取有参考译文的方法进行评测。但是这样又陷入了用机器译文评价机器译文的循环中,难以保证评价的准确度和信度。
除此之外,很多领域面对大量要翻译的内容,开始利用机器翻译作为辅助翻译,或者作为前期初步的翻译结果以降低人工翻译的工作量。为此,要区分了解哪些机器译文是可以直接使用的,哪些是需要人工进一步校对的,但并不需要给机器译文一个具体的分值,只需明确机器译文是否可用就可以了。因此,费用和效率等原因促使部分翻译质量评价研究转向译文质量估计(Quality Estimation,QE)(Specia et al.,2010)。质量估计通过对译文质量的预测信度(confidence)来判断机器翻译的结果是否可直接采纳,还是需要译后编辑,或者从机器译文中快速过滤出质量较低的句子进行编辑,从而提高译后编辑的效率。当然,质量估计也可从多个机器翻译系统中选择性能最佳的系统,并挑选出质量较差的译句。这些都是译文质量估计的应用场合。
为满足上述应用需求,自WMT10开始增设了评价标准的研究平台,增加了质量估计任务。WMT13的质量估计任务包括2个子任务,一个是句子级的评测,另一个是词语级的评测。研究数据全部公开,方便比较结果。
实现QE主要利用机器学习的思想,研究也主要用有监督的机器学习。两个主要研究问题是:
一是机器学习模型的选择和对比:条件随机场(Conditional Random Fields,CRFs)、基于记忆的学习(memory-based learning)、基于径向基函数(radial basis function)的非线性支持向量机回归SVR(Support Vector Regression)等都曾用于译文质量估计中。这些学习模型均属于浅层结构学习中的分类模型和回归模型。
二是语言特征的挖掘:确定学习模型后,研究重点集中在如何尽量多地提取可能与译文质量有关的特征上。QuEst系统包括与语言无关的17个基本特征,后来发展到QuEst++,最多时提取了172个特征(Specia et al.,2015)。各类表层语言特征在学习模型中基本都被尝试用过了。
QuEst系统6是一个翻译质量评估的框架,为从源语言、待评译文和外部资源中提取多种语言特征参数提供了工具软件,并利用一个开源的机器学习工具包scikit-learn7完成评估系统的训练学习。QuEst用Java实现,提供了特征的抽象类以及有关资源,方便用户添加新的特征。包含基本特征的QuEst系统目前在WMT中作为一个基准(baseline)的QE系统。
无参考译文的质量估计任务包括训练和测试两个步骤。训练阶段是基于特定的学习模型和语言数据得到质量评估的模型参数。测试阶段则是对新的译文进行特征提取,然后输入到评估模型中得到评测的结果。整体框架如图3-20:
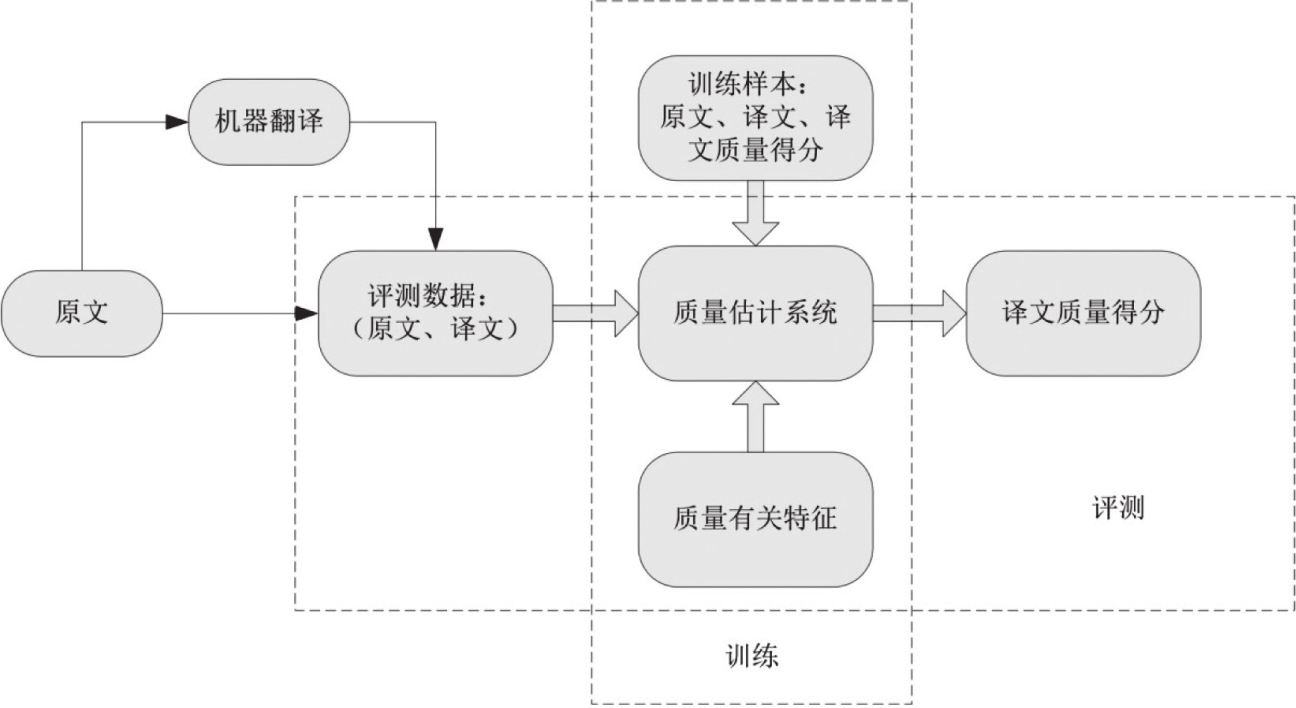
图3-20 翻译质量评估系统框架
下面我们详细讨论质量评估框架中的语言特征和机器学习模型。