5.1.3 机器翻译错误分类
分析了机器译文的特点后,Vilar et al.(2006)提出了译文错误的层次分类方法,如图5-3所示。该分类方法以词汇为单位划分翻译错误类型,第一层次的错误包括:遗漏词汇、错译词汇、未知词汇、词序和标点五类,层次最深为3层。
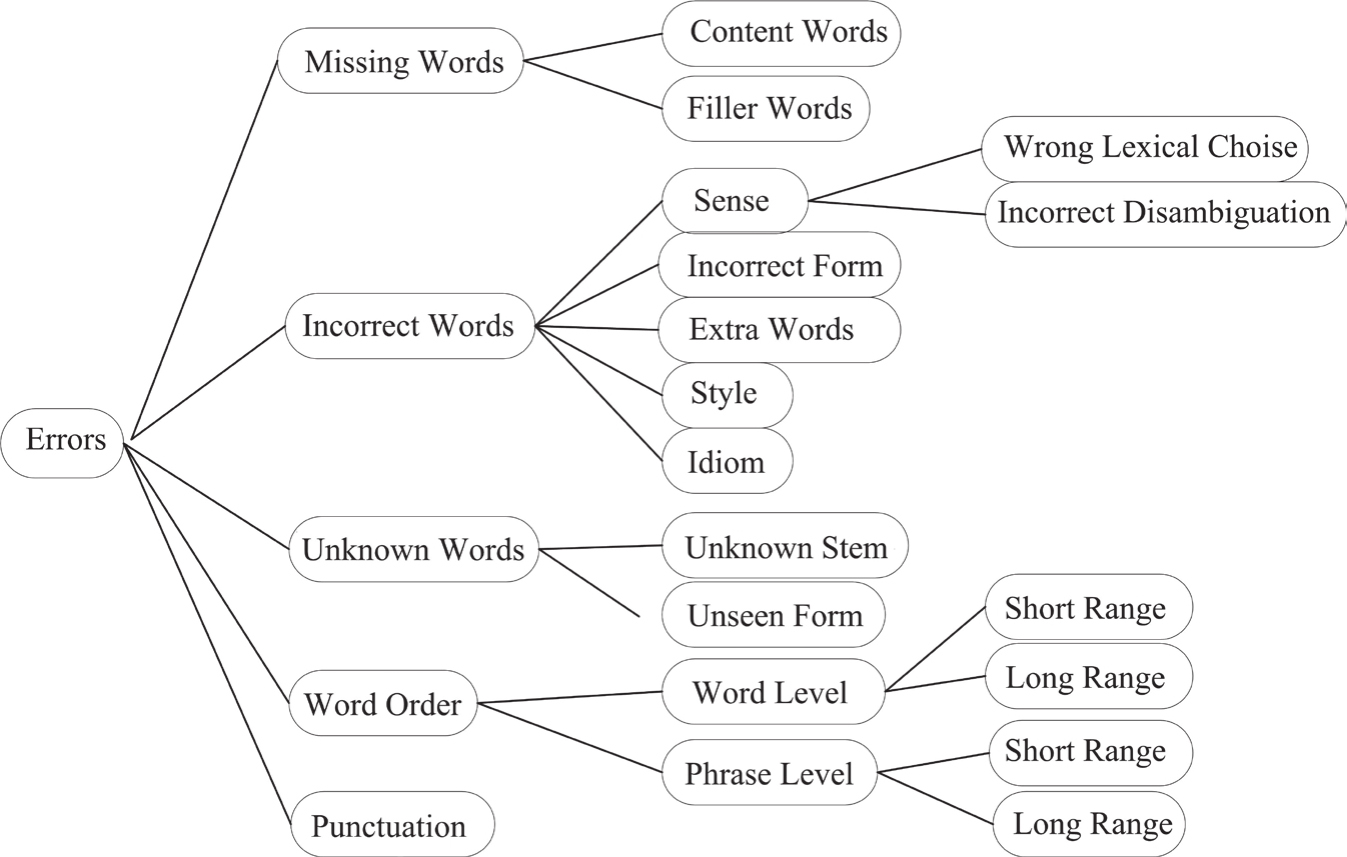
图5-3 Vilar et al.的机器翻译错误分类
QTLaunchPad3是另一项受欧盟资助的合作研究项目(2012-2014年),致力于在机器翻译研究人员和语言公司之间构建新型的系统化的研究和合作基础,借助语言技术来克服机器和人工翻译之间的壁垒。参与单位包括德国人工智能研究中心(DFKI)、都柏林城市大学(DCU)、雅典语言话语研究所(ILSP)和英国谢菲尔德大学(USFD)。项目中的多维质量标准MQM(Multidimensional Quality Metrics)是一个统一而连续的描述翻译质量的框架,提供了面向特定应用需求的翻译质量因素,从简至详分为多个层面,既有文本的整体(holistic)评价,也有涉及具体问题的分析(analytic)评价。该标准适用于人工评价、半自动评价和自动评价译文质量,对各种文本类型均适用。
框架列出的翻译问题包括一百多种,既有语言质量问题,又涉及译文对于市场的适用性等问题。每个问题又分为多个层次,便于用户选择和编制自己的评价标准。该标准是基于ASTM F2575翻译标准制定的。第一层包括准确性(accuracy)、流利度(fluency)、设计(design)(如版面和格式)、真实性(verity,是否适用于目标场合和读者)以及国际化(internationalization,源语言的内容是否适合翻译)等。
作为一个大而全的标准框架,用户通常根据实际需求在该框架基础上进行修改,以得到面向不同应用场合的评价标准。比如在机器翻译评测中的一个简化版本包括2层,15种翻译问题,如图5-4。
在国际机器翻译评测的词语一级评测中还进一步简化为一个两类问题,即一个词语是否存在准确度和流利度方面的问题(Bojar et al.,2013,2014,2015),这种简化可以为人工发现和筛选有问题的译文提供帮助。
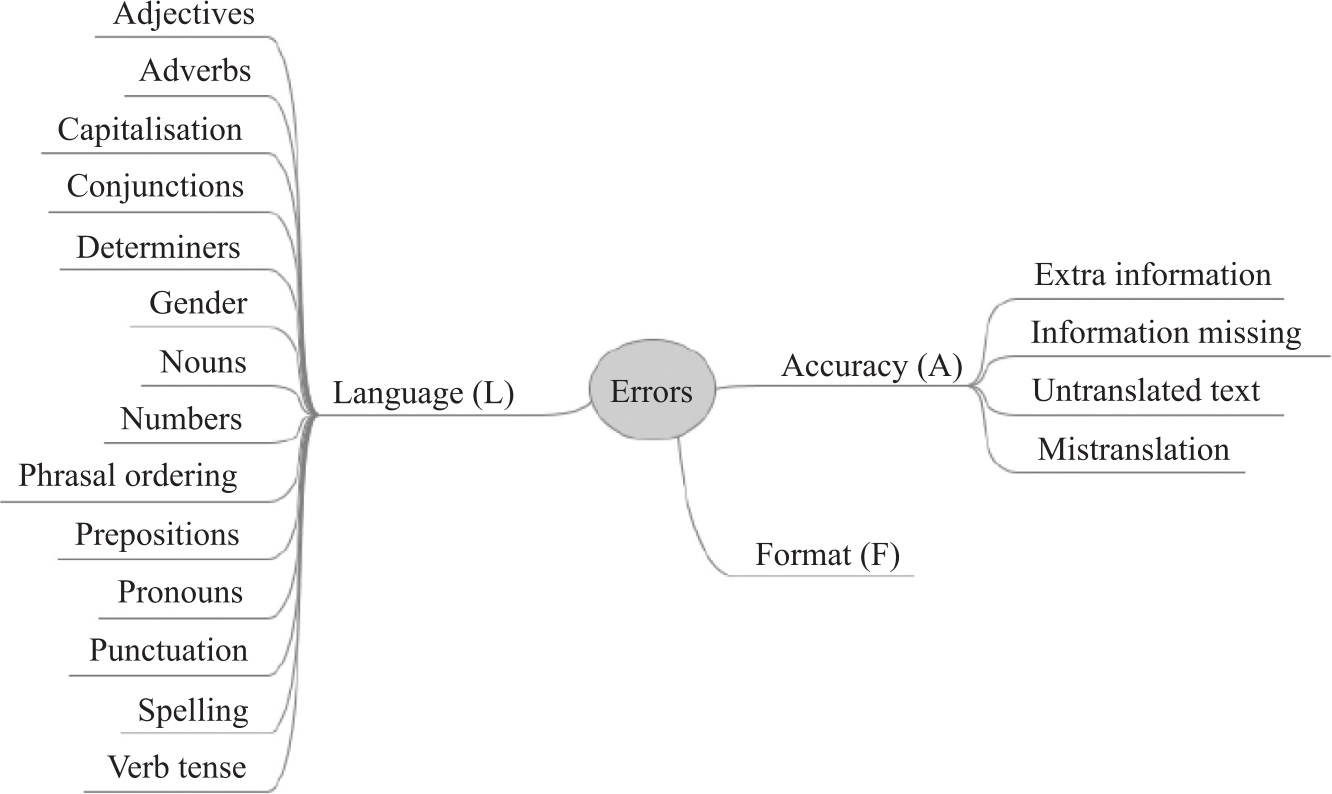
图5-4 WMT中机器翻译错误的类型划分