3.2.1 语言特征参数
译文质量评估的语言特征包括来自源语言的特征、来自译文的特征和来自双语的特征三类。这些特征有黑盒特征也有白盒特征;既有独立于语言的简单特征,也有和具体语言有关的、来自翻译系统的复杂特征。常见的黑盒特征大约有80-123个,不同翻译语言对的黑盒特征数目不同。白盒特征约有39-48个左右(Specia et al.,2013)。质量评估中特征提取的基本单位一般是句子。
来自源语言句子的基本特征有:句子的长度、n-gram特征、语言模型特征和相关语言资源的特征。来自译文的基本特征有:译文句子的长度、单词的平均出现频率、词汇语言模型的特征、词性语言模型的特征。双语对齐特征主要基于词对齐结果提取翻译概率。下面予以详细说明。
一、n-gram特征
n-gram即n元组特征。在无参考译文的译文质量估计时,QuEst系统对n-gram数目设置了阈值,只有出现频次大于阈值的n-gram才予以考虑,这样既能降低系统的负担又不至于忽视与质量有关的重要内容。另外,还可以对n-gram的出现次数进行分档。如QuEst中分为四档n-gram,前25%、前50%、前75%和剩余的部分。n值不同,n-gram的数目也不同,分档点也就不同,比如QuEst中unigram的分档频次为5、14和68,bigram的分档频次为4、6和16,trigram的分档点为3、5、10。实际分档频次应根据语料的具体情况而定,提取特征时分别确定该n-gram位于哪一档内。另外,最低n-gram频次和总的n-gram数目等特征也都可以作为特征。实际使用中,n值一般取到3或4。
二、双语对齐特征
IBM对齐模型1-5是著名的词对齐模型。IBM-1模型是对独立单词翻译分布概率的模型,直接应用EM算法得到。所谓独立单词,就是不考虑单词在文本中的位置。IBM-1模式是基于词对齐概念的翻译模型,对于每一个输入原文句子得到不同翻译概率的多个译文的模型。IBM的五个翻译模型的复杂度依次增加。IBM-1模型算法伪代码实现如下:其中条件概率t(e|f)表示给定原文词汇f,译为e的概率。

开放的词对齐工具也有很多,如用Giza++,是基于概率的双语词对齐工具。如果要对齐英汉语料,需要先对汉语进行词汇切分处理。在双语语料上对齐原文和待评译文,得到词对齐概率文件。词对齐文件的格式是:
原文词汇 译文词汇 翻译的概率
根据对齐文件,能够提取的主要双语特征包括:
· 原文和译文的单词数目之比
· 原文和译文的括号和标点符号的数目之比
· 原文和译文的数字、实词、功能词的数目之比
· 原文和译文的动词、名词等不同词性的单词数目之比
· 原文和译文对齐后,主要成分依存关系的比例
· 原文和译文句法分析后,解析树的深度差异
· 原文和译文中各种短语数目的差异,如PP/NP/VP/ADJP/ADVP/CONJP
· 原文和译文中各种命名实体数目的差异,如人名、地名、机构名等
· 不正确翻译的人称代词和所有格代词的数目
双语特征的提取避免了再次进行翻译的循环式思路来评估译文的质量。
由于Giza++计算的是对齐的概率,因此当待评译文整体上对一个词的翻译犯同种错误时,对齐将有很大的概率对齐翻译错误的词汇,也就是说翻译错误的词汇一样可以在比较高的概率下得到对齐。实际应用中,可以将和某个源语言词对齐的译入语词根据概率排序,选择概率最高的1个词汇或n个词汇用作评测特征;还可以设置词对齐概率的阈值,从而删除概率低于阈值的词汇,既能降低对内存的要求,又能提高运行速度。一个源语言词汇和满足阈值条件下的多少个译入语词汇对应也是一个特征参数。在没有参考译文的情况下,双语对齐特征是一类十分重要的特征。
三、语言模型特征
语言模型反映的是源语言翻译的复杂性,或者是对机器翻译系统而言,存在多大程度的翻译“意外”现象。下面首先对语言模型的概念作介绍。
(一)语言模型的概念
语言处理中描述各种语言知识的形式化的方法或理论,称为语言模型。语言模型是一种集数学、语言学和计算机于一体的描述自然语言的模型。
常见的语言模型有:语法体系模型和统计语言模型。语法(grammar)体系是描述语言的一种模型,由一系列的语言规则组成,比如形容词放在修饰词的前面而不是后面。还有一种在计算机中描述语言的模型称为统计模型(statistical model),是基于词或者词性序列构建的,常用的就是前面多次提到的n-gram语言模型。
关于两种语言模型的争论从20世纪50年代就一直不断,grammar一方的代表是乔姆斯基(Noam Chomsky),1969年一段表明Chomsky观点的有名的话是:“It must be recognized that the notion of a 'probability of a sentence' is an entirely useless one, under any interpretation of this term.”。可见,Chomsky认为,用概率描述句子的观点是完全没用的。
统计方法研究语言的代表者是Fred Jelinek。他对语言学家的态度却是:“Every time I fire a linguist, the performance of the speech recognizer goes up”。统计语言处理的主要思想是根据已经观测到的数据来预测未观察到的数据,并不去解释观察到的数据的含义。从观察数据或者经验中学习是统计分析的核心观点。
(二)n-gram语言模型
这里,我们对n-gram概率语言模型作较详细的说明。n-gram语言模型用于计算一个句子(词序列)的概率,还用于预测下一个词的概率。如果只有一个包含V个词的词典,在没有其他知识的情况下,我们只能假定每个词的出现概率是均等的,即1/V。如果给定一定规模的文本,通过统计就会发现,词的出现机会是不同的。比如,在狄更斯的10部小说中共有3,234,061个词,例如下面4个单词的发生频次和概率为:
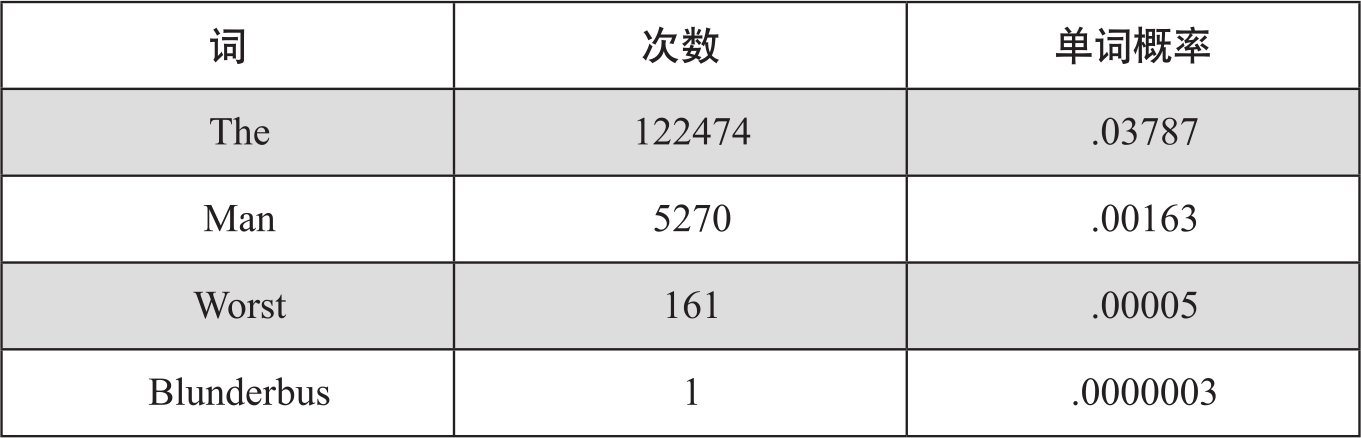
这个概率称为先验概率,反映了词汇本身在语料中出现的机会大小。齐夫定律(Zipf's law)反映的就是英文中词汇使用频率和排名之间大致的关系,词汇使用频率与排名的乘积是个相对稳定的值。
当然词不是独立出现的,跟所在的语境相关,因此需要考虑已经出现的词,比如前面一个词为the,而下一个出现的词出现the的概率就比出现man或者worst的要低。因此要考虑条件概率,这样就得到了n-gram模型的表达式,即式3-20:
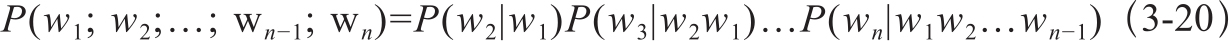
求解这个模型十分复杂。根据马尔科夫假设(Markov assumption),假设第n个词的出现只与前面k个词有关,当k=1就是二元模型(bigram),k=2就是三元模型(trigram)。通过简化使复杂的模型问题得以求解,这样n-gram模型的条件概率就可近似为:
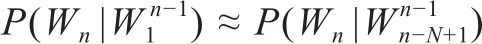
例如bigram模型,一个词串的概率就是
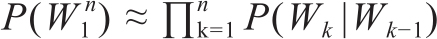
求解后面的条件概率可以用极大似然估计MLE(Maximum Likelihood Estimation),即
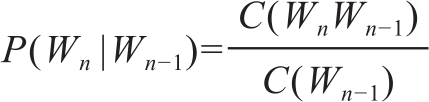
扩展到一般的n-gram计算式就是:
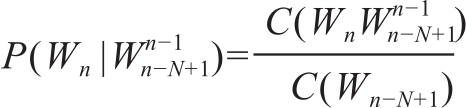
当n=1时,计算P(W1|W0)=P(W1|*S*),也就是句子开头的词的概率。分子上的共现次数通常可以统计这个词出现在一个句子结尾标志后的次数。
(三)语言模型的困惑度
语言模型的困惑度(Perplexities)是和信息论中交叉熵(cross entropy)概念密切相关的一个概念。交叉熵的定义式为:
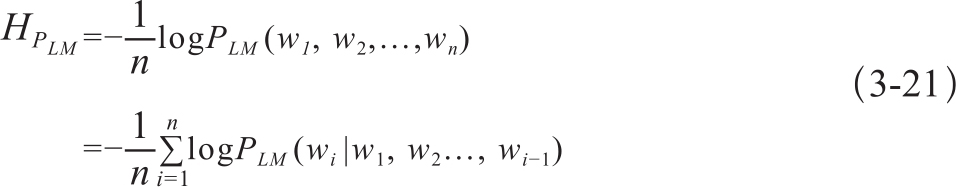
PLM(W1,W2,…,Wn)表示一个语言模型中词汇联合分布概率。语言模型的困惑度PP是将交叉熵作为2的指数的计算结果:

例如:根据上式,可以计算下面句子的3-gram语言模型的困惑度。
I would like to commend the rapporteur on his work.
计算时需要先根据某个语料得到句子中每个单词的概率,并得到基于前面两个词的条件概率,代入公式就可以得到三元文法语言模型的困惑度了。在《统计机器翻译》一书中基于这个句子对比了一元文法、二元文法、三元文法和四元文法的困惑度(宗成庆、张霄军,2012),如表3-17,根据词表可以了解到语言困惑度的基本情况。
表3-17 不同n-gram语言模型的困惑度比较

一个语言模型的困惑度越低,越能够准确预测语言现象,模型也就越好。
常见的除了n-gram语言模型外,还有基于句法分析的语言模型。这种语言模型还不很成熟,但是已经被尝试用于语音识别和机器翻译中。在机器翻译中应用句法分析语言模型,分成两个步骤,首先令解码器输出多个而不是一个翻译结果,然后对这些翻译结果进行句法分析,得到每一个结果句法分析的概率,根据概率值对这些句子重新排序得到最好的翻译结果。在语音识别实验中,这个方法要优于三元语法模型(Charniak,2001)。
(四)n-gram语言模型特征
翻译质量估计中应用的n-gram模型特征主要包括:基于模型的词汇出现的条件概率、语言模型的复杂度等。
但是,n-gram模型是对自然语言的一个简化模型,存在很多问题:首先是语料规模和数据稀疏问题。通常n-gram模型需要大规模语料才能得到比较好的估计值。语料规模不够,就会出现较多的n-gram观察不到而概率值为0,造成数据稀疏问题(data sparseness)。在语料中观察不到的语言序列并不一定是因为该n-gram不存在,只是出现的概率很低。所以,一般可以用平滑smoothing方法来处理零概率的问题。
在句子级的译文质量评估中,QuEst++一共使用了18种基本特征(Specia et al.,2013),具体包括:
· 原文句子的长度
· 译文句子的长度
· 原文平均词长
· 原文句子语言模型的概率
· 译文句子语言模型的概率
· 译文句子的平均形符类符比(type/token ratio)
· 原文句子中单词的平均译文数(IBM-1模型,阈值prob(t|s)>0.02)
· 原文句子中单词的平均译文数(IBM-1模型,阈值prob(t|s)>0.01)
· 原文语料每个单词的倒排词频
· 源语言训练数据中低频词(前四分之一频率类)的比例
· 源语言训练数据中高频词(后四分之一频率类)的比例
· 源语言训练数据中低频二元组bigram(前四分之一频率类)的比例
· 源语言训练数据中高频二元组bigram(后四分之一频率类)的比例
· 源语言训练数据中低频三元组trigram(前四分之一频率类)的比例
· 源语言训练数据中高频三元组trigram(后四分之一频率类)的比例
· 原文句子中出现在训练语料中的单词比例
· 原文句子中标点符号数目
· 译文句子中标点符号数目
在上面众多特征中,根据对质量估计的显著性排序,依次是:
· 源语言和译入语语言模型的困惑度和对数概率(log probability)
· 原文和译文句子长度
· 原文单词平均译词数目(基于IBM-1模型,增加阈值)
· 译文与原文单词数目之比
· 译文中数字的比例
· 在机器翻译原文训练语料中不同单词的比例
这些特征有的包含在18种基本特征中,有的并不包含在内。特征的最初选择由人完成,在模型训练中可以进一步采取特征选择的方法,让有意义的特征进入模型训练过程中。