3.4.2 质量排序算法
排序法(Ranking)适用于对一组译文进行评价,根据质量高低将译文排序。质量排序方式近年来比评分方式更普遍地使用到机器翻译的人工评测工作中。自2010年起,质量排序已被定为WMT的官方人工评测方法,不再采取对翻译系统直接打分的评价方法。
在WMT的人工评测中,由于一个语种往往有多个翻译系统的结果,在利用Mturk平台进行排序评测时,每个评估者被随机分配给5个系统翻译,要求将这5个机器译文的质量进行排序,也就是给出质量名次1-5,允许出现相同的名次。这样一个翻译系统的结果就被不同的人多次和其他不同的4个系统翻译结果进行了比较。不把所有翻译系统的结果一次性交给评估者的原因很简单,就是人工区分大量译文质量的难度更大。根据最新的WMT16的评测报告(Bojar et al.,2016),由于众包平台上有很多Turkers,一个翻译系统被排序的次数多达上万次,至少也有近千次。
最终一个翻译系统的得分取决于该系统优于与其他系统的频次(不含名次相同的比较次数),除以和该系统参与的评测次数(不含名次相同的比较次数),作为该系统的质量排名得分,这就是基于胜出的排序方式(win-based ranking),并用符号检验(sign test)验证排序结果是否存在真正的差异。下面通过一个例子解释该排序方式:
翻译系统A是一个参评系统,包含A系统结果的评测组共有120个,也就是A和组内其他4个系统共比较了480次,其中A胜出的次数有200次,而在480次比较中有80次是名次相同的,那么最终A系统的排名分为:
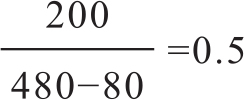
这个值也可以理解为:和其他翻译系统两两比较中,A系统有50%的概率胜出。需要注意的是,计算式中分子部分是A系统和其他系统两两比较时排名胜出的次数,不包括排名相同的情况。因为,质量相似的情况如果也计分的话,相当于对应用类似技术构建的翻译系统也进行奖励,无法真正区分那些好的翻译系统。该方法最终被WMT采纳。
当然,还有其他排名的方式,如多个参赛系统的评测结果有可能出现轮回的情况,比如三个系统A、B、C的排序统计结果情况可能为:
Count(A>B)=20;Count(B>A)=0
Count(B>C)=40;Count(C>B)=20
Count(C>A)=60;Count(A>C)=20
为此有人对三个系统到底哪个更好存在疑问。针对两两比较的结果,计算多系统的质量排名方法,有一种称为最大可能性的排名方式(most probable ranking)。假设三个系统两两比较的统计结果如上所述,单独两个系统A、B相比的排序结果容易根据上面基于胜出的排序方式得出来,比如p(A>B)的计算式如下:
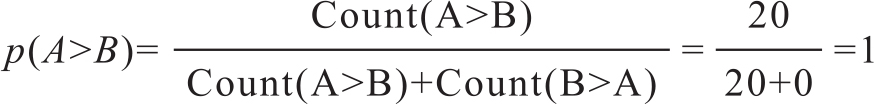
三个系统的排序结果就可以按照如下计算:
p(A>B>C)=p(A>B)p(B>C)P(A>C)
质量排序评测过程中,有的给予参考答案,有的不给参考答案。有没有参考译文对评测结果的内部一致性和外部一致性都是有影响的。从WMT12之后,人工排序时并不给出参考答案。这样做的理由是,评价人员会自觉不自觉地和参考答案对比,将和参考译文相似的译法排在前面,这样不利于其他采取不同译法的译文的质量评价(Callison-Burch et al.,2012)。
人工排序评价结果的一致性用Kappa系数K来计算。根据文献,近年的WMT句子翻译质量排序评测中,K值一般位于0.4-0.6之间,内部一致性高于外部一致性,如表3-19和表3-20。一致性仅仅位于中等水平,人工排序中也还有很多问题要解决(Bojar et al.,2016)。
表3-19 机器翻译质量的人工排序外部一致性K值变化
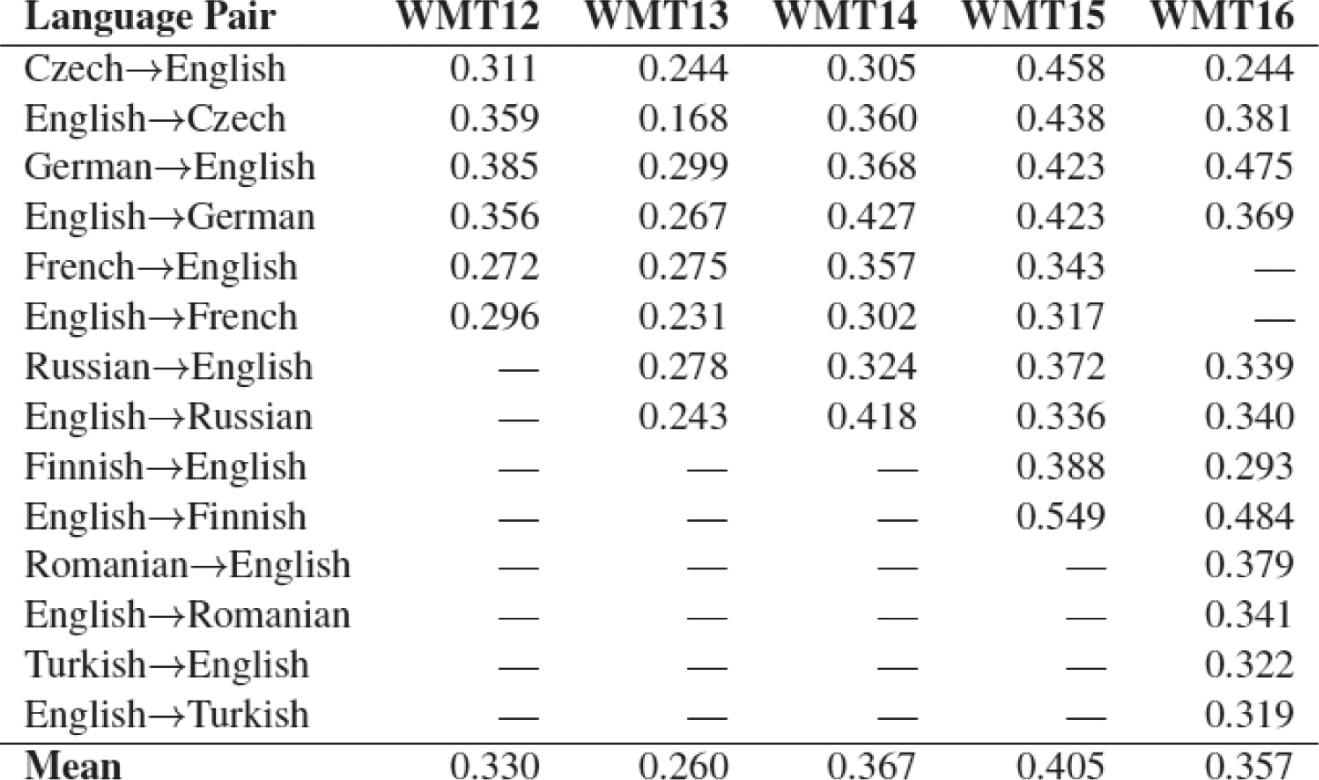
表3-20 机器翻译质量的人工排序内部一致性K值变化
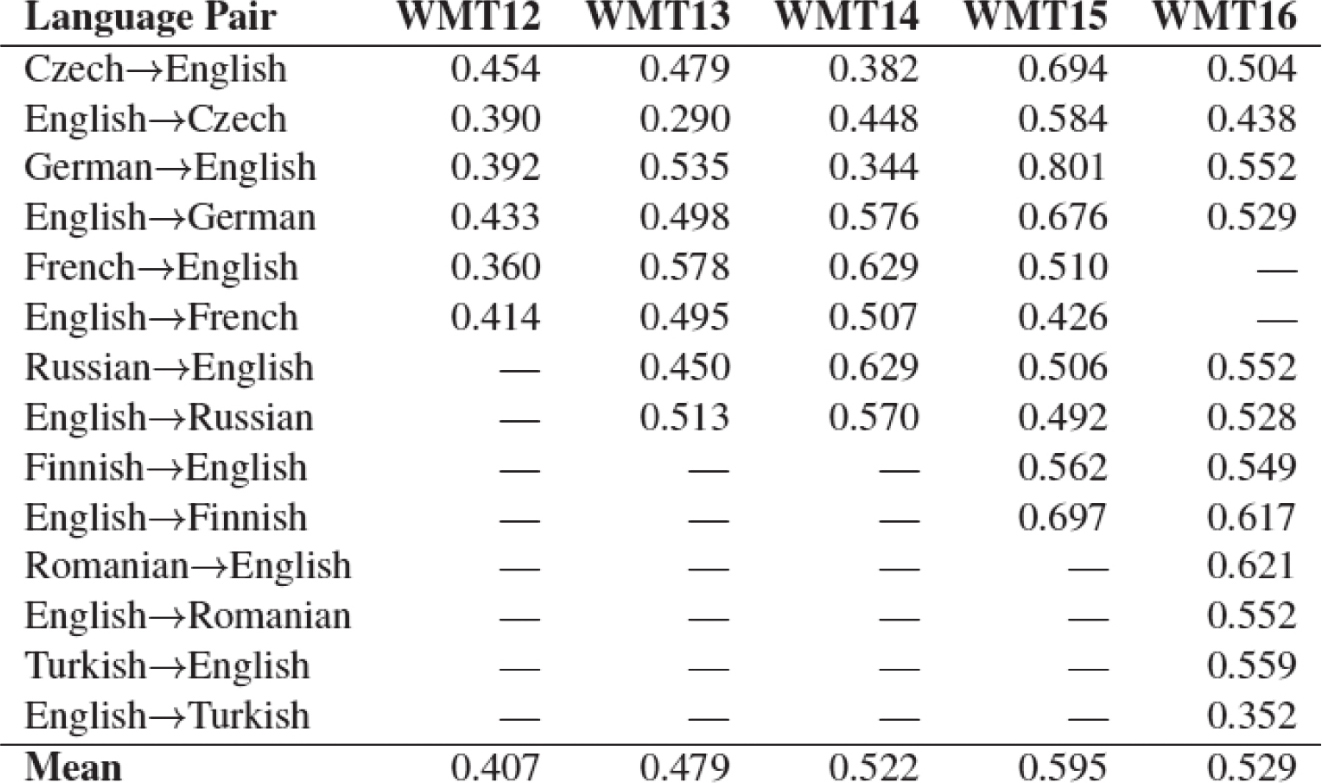
WMT14-16年的评测由研究人员完成,之前几年是研究人员和众包混合评测。随着各类措施的推进,人工评测的一致性近几年有所提高。