4.2.3 直译/默认翻译构念下的译者实时认知加工研究
4.2.3.1 直译/默认翻译的内涵和衡量标准
直译是一个与自动化有关的构念。Ivir(1981)首先提出了“直译默认假设”,而在早期的规定性研究和教学研究中,直译被认为是在不同的翻译环境中可以被接受的翻译策略之一(参见Newmark 1988;Vinay & Darbelnet 1995:33-34)。Halverson(2015)概述了这一构念在翻译研究中的演变,并指出,“直译”的应用经历了基于语言系统关系描述的阶段以及基于文本分析和语料库方法的探讨阶段,如今又在翻译过程研究中复活。两个关键的实证研究范式——基于过程和产品的范式正在相互融合,形成“直译/默认翻译”构念5。
目前认知翻译学中使用的直译构念通常是基于Tirkkonen-Condit(2005:408)的描述:直译看起来好像是一种默认的转换过程,直到监控发出产品中存在问题的警告时,这一过程才会中断,而打断直译的监控功能通过触发有意识的决策来解决问题;直译的运作痕迹在专家翻译过程和产品中较少,不像在新手和非专家的翻译过程和产品中那样频繁可见。因此,默认直译也是自动化加工的一种表现。
在翻译过程研究范式的一系列研究中,Schäeffer(2013),Schäeffer & Carl(2013,2014)以及Schäeffer et al.(2016)发展了一种被称为“理想直译”的理论框架,并基于Tirkkonen-Condit关于直译的描述,对直译概念做了可操作化处理,从而可以使用翻译过程数据进行量化和分析。Schäeffer et al.(2016:189)提出了直译的三个衡量标准:(1)源文本和目标文本中的词序相同;(2)源文本和目标文本词项一一对应;(3)每个源文本中的词语在给定的上下文中只有一种可能的翻译形式。基于可操作化标准,可以对最终翻译产品进行分析,测量直译性,然后针对过程数据中的一系列变量(击键记录和眼动跟踪记录)验证直译测量结果,从而发现翻译的直译性与过程数据中证实的激活模式之间的关系(转引自Halverson 2017:202-204)。
4.2.3.2 直译/默认翻译构念与横向水平加工/纵向垂直加工假设
与直译构念直接相关的是横向水平加工和纵向垂直加工假设。在翻译的水平加工假设中,源语话语的理解以跨语言结构启动的方式对译文产出产生影响;而在垂直加工假设中,翻译过程中的理解和产出阶段是彼此分离的。这对假设涉及双语表征的组织形式及其互动关系,双语心理词库的表征结构研究也对其产生了一定的影响。Kroll & Stewart(1994)在词汇翻译实验中发现了翻译速度的非对称性(L2–L1的“反向翻译”快于L1–L2的“正向翻译”)和翻译路径的非对称性(L1–L2的正向翻译涉及不同的概念因素,说明正向翻译需通过概念的调节,而反向翻译不涉及概念,仅仅在词名层上进行转换),得出了下图所示的模型:
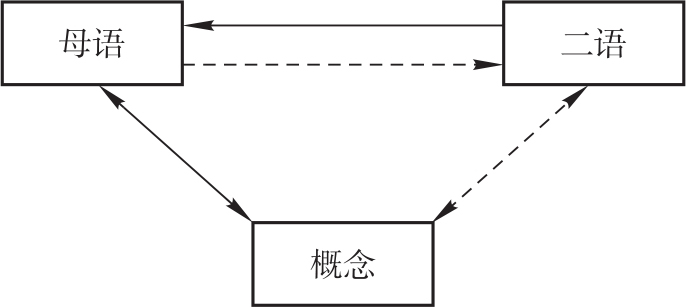
图4.1 非对称双语表征模型(Hierarchical Bilingual Model)(Kroll & Stewart 1994)
该模型中,水平加工和垂直加工与翻译的方向性有关。近二十年来,围绕双语互动激活、竞争和抑制机制的问题,心理语言学界展开了激烈论辩,刘绍龙、王柳琪(2010)基于上述非对称模型,融合抑制机制和决策系统,建立了新的词语翻译的非对称性表征模型,如图4.2所示:
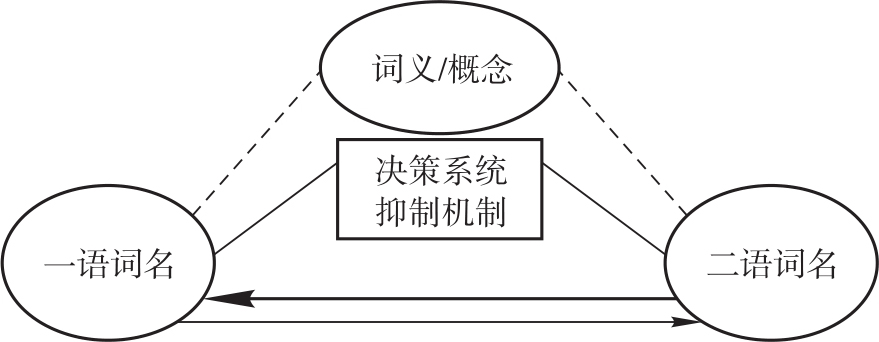
图4.2 词语翻译非对称性表征模型6(刘绍龙、王柳琪 2010)
刘绍龙、王柳琪认为,该模型体现了基于双语转换认知理论的双语词汇习得效应、双语词汇翻译转换效应以及与其密切相关的认知决策系统和激活抑制机制。基于此模型,他们认为,鉴于二语词名与词义/概念的差异性习得效应或连接特征,二语习得者或译者在(词汇)翻译过程中也会出现翻译方向、翻译速度、翻译质量等的非对称转换效应。我们可以看到,在此模型中,水平加工和垂直加工同时存在,而且对监控作了进一步的具体化。Muñoz Martin(2017)指出,“双语互动激活+模型”或“BIA+模型”(van Heuven & Dijkstra 2010)可能有助于解释一对一和一对多直译的结果。针对翻译认知,目前我们需要解决的关键问题是,现有双语心理词典或双语表征研究主要涉及词汇层面上的启动效应,但是翻译过程研究中也存在其他层面上的启动效应假设7,例如跨语言结构启动,同一语系中句法结构相似语言之间的启动,句法结构差距大的语言之间的启动等。
一般的翻译理论假设认为,译者以源语言(即初始语)来理解话语的含义(即消息),在语言之间转换,然后产生目标语言中具有相应含义的话语。然而,目前的理论争议在于,翻译在多大程度上是“垂直的”,即理解和生产是分开的,或者说是“水平的”,即源语言的语法和词汇属性会影响翻译的方式(见Ruiz et al. 2008)。在心理语言学领域,垂直假设假定,翻译者在不受目标语言影响的情况下理解原文,继而进行语言转换,最后在不受源语影响的情况下产出译文。如果这个假设是正确的,那么源语言的语法和词汇属性只有在语义相关这个意义上才能影响目标语言。也就是说,当替代语法形式选项具有相同含义时,译者就不应该在语言之间重复句法形式。相反,横向水平假设认为,源语的特征可以影响翻译,或是因为目标语言在译者理解源语的过程中已经被激活,或是因为源语在目标语句产生期间保持激活,因此横向水平假设预测译者会跨语言重复句法和语言形式的其他方面。
尽管一些翻译理论认为,水平过程中译者需要使用经大量培训才能掌握的专业策略(Paradis 1994,2004;Seleskovitch 1962,1976),但大多数证据支持未经训练的双语者也会使用水平过程。例如,Barik(1971:209)将业余翻译描述为“非常典型的直译”,在许多情况下几乎是字对字的“言语转换”而不是翻译,而专业译者的翻译更符合目标语言的用语习惯。同样,Lörscher(2005)发现,二语学习者相比专业译员更倾向于跨语重复句法。最后,van Hell & de Groot(2008)指出,等值词与形式重叠词(“同源”,例如荷兰语和英语中的lip)的翻译速度比非同源词快,即使它们出现在相同句子语境中也是如此。这些发现表明,水平过程是自动发生的,如果要避免在不合适的情况下使用水平过程,则需要进行专业培训。
语料库分析也表明专业翻译人员使用水平加工。例如,Eskola(2004)对目标语为芬兰语的书面翻译进行了基于语料库的研究。结果显示,某些芬兰语特有的构式在英语或俄语为源语的翻译文本中出现的频率,比在用芬兰语直接写成的文本中的出现频率要低得多。这表明,翻译会以牺牲芬兰语特有的构式为代价,使用芬兰语和俄语或英语之间相似的构式8。另外,心理语言学实验表明,与常规阅读不同,译者阅读翻译文本时会受到源语和目标语言之间的词汇重合和句法一致性的影响(Macizo & Bajo 2006;Ruiz et al. 2008)。Shreve & Lacruz(2017)认为,在翻译中,源文本对目标文本的生成产生的影响更大,也更持久,而由源文本构建整合的情境模式是目标文本生成的唯一模板,这种情况在新手译员的翻译中较为常见,他们的翻译受到源语语言形式的显著影响。水平加工也发生在忠实(逐字翻译)或其他方面的翻译情境(如文献研究)要求语言形式一致性优先于情景模式一致性的情况下。当然,尽管我们目前的研究大多关注非专业人员的翻译,但需要注意的是,专家译者的翻译中也会出现水平加工。
至于翻译水平加工以什么样的认知机制为基础,Potter & Lombardi(1990)提出了一种可能性,即句子翻译类似于句子的回忆(sentence recall)。人们并不是通过保留表层的表征回忆句子;相反,他们通达句子的意义,然后将这个意义作为再生形式的基础。这就意味着人们可能会改变与意义不符的句子的任何方面。Potter & Lombardi(1990)也提出,人们也倾向于在回忆中使用理解时启动的词汇。
Maier et al. (2016)通过视察双语人士翻译产品的句法方面来考察他们是否倾向于重复语法形式和意义。他们把重点放在没有经过特殊培训的(英语和德语)双语人士的加速翻译上,最大限度地减少翻译显性训练的影响9,从而提供关于翻译的自动过程的最清晰证据。实验证明,当被要求翻译话语时,人们可能只确保他们的翻译与原文具有相同的含义,但是他们也可以跨语言保持句子的形式。参与者几乎总是准确地重复句子,从而保留语法结构。在两项实验中,Maier等人通过实验1发现人们倾向于跨语言重复语法形式;实验2则增加了英语中没有语法等同形式的条件,在此情况下参与者倾向于坚持借用主题角色的顺序。他们认为,启动发生在从理解到生产的过程中,发生在句子回忆的条件下。它出现在语言之间(类似于语言之内的启动),而且目标语在启动不久之后就被加工,语言之间有意义重复(翻译对等增效)的情况下,表现都非常强烈,且经常是快速发生(如同声和交替传译)的。垂直翻译假设(Seleskovitch 1976)不假定任何句法迁移,但可能不足以说明译者保留句法的现象。实验数据支持水平翻译假设:(未经培训的)译者根据他们对源语言句子的理解产生目标语言句子,同时受到多语言层面启动的强烈影响。
4.2.3.3 直译/默认翻译构念与翻译过程递归模型
Schäeffer & Carl(2013)提出了一个翻译过程的递归模型(recursive model),包括激活共享双语表征的早期启动过程,以及随后更有意识的、基本上单语的垂直监督过程。共享句法表征根据双语者共享句法表征假说(Hartsuiker et al. 2004)来确定,而共享语义表征根据分布特征模型(distributed feature model,简称DFM)(de Groot 1992)确定。以此为基础,Schäeffer & Carl(2013:174)认为,“翻译过程早期阶段就会通达共享表征”,并且早期阶段“没有有意识地控制源语和目标语在认知上如何对应”(2013:173)。早期的水平启动构成了一种默认的翻译方式,随后在监控模型(monitor model,参见Tirkkonen-Condit 2005)之下,译者“根据启动的表征重新生成[源文本]”(Schäeffer & Carl 2013:175)。早期阶段的横向默认翻译加工被纵向加工打断,在源语和目标语之间循环进行的自动默认过程的输出成果由纵向加工过程处理,并随着翻译生产的语境量增加而监控一致性(Schäeffer & Carl 2013:186)。因此,垂直监控过程通过扭转源文本的再生过程打断原本自动化的默认翻译生产,由此在词汇和句法层面引入翻译变体。翻译中较大的词汇和句法变化将导致较长的注视和生产时间。
为了评估上述理论模型,Schäeffer et al. (2016:189)将源文本与目标文本的句法相似性和翻译实现的词汇变化,设定为直译/默认翻译假设可定量化的标尺。这个假设的基本内容是:源语和目标语语义和/或句法表征的共享程度对早期的自动默认翻译过程和有意识的晚期监控过程都有影响。Schäeffer等人基于实验证据指出:词汇翻译熵和句法扭曲对首次注视时间和总阅读时间都有显著的正面影响;第一次注视的持续时间(第一次阅读时在一个单词上花费的时间)可以被看作相对自动化的加工的体现,而总阅读时间(一个单词的所有注视时间的总和)则代表后期更有意识的加工过程。值得注意的是,Schäeffer等人的这项研究可以预测眼动变化,例如,在一定程度上可预测第一次注视时间,但在翻译过程中对眼动有影响的潜在的大量变量是未知的。直译/默认翻译的构念是多方法研究的基础,上述研究的一系列模型构建和假设检验活动中依次使用的产品数据和过程数据,是TPR-DB(Carl,Schäeffer & Bangalore 2016)多语言实验数据的一部分。
直译默认假设与已有的多个翻译过程理论模型和假说有关。Schäeffer & Carl(2013)和Schäeffer et al. (2016)的上述研究以双语表征研究为基础,包括分布式表征模型(例如de Groot 2011:133-134)及其扩展模型(Finkbeiner et al. 2004)。这些研究不断尝试将理论基础从直译/默认翻译概念扩大到更广泛的双语表征概念(转引自Halverson 2017:204)。研究“默认翻译”与认知语义表征模型的相关性,可以帮助我们解释译成语言与非译成语言之间的差异。Jakobsen(2014)指出,Ivir(1981)提出的直译默认假设与Tirkkonen-Condit(2005)提出的监控模型以及Toury(1995)提出的干扰定律密切相关,也可能涉及引力假说(gravitational pull hypothesis)(Schäeffer & Carl 2014)。
翻译学也可以从邻近学科正在开展的研究中受益,并且有可能作出其独特贡献。根据Tirkkonen-Condit(2005)监控模型的基本假设,译者的第一个自动化的冲动行为是在目标语言中寻找与源文本中单词形式相似或相同的单词,直到监控介入并停止这个默认过程。神经语言学家(de Bruin et al. 2014)已经通过脑电图测量和fMRI扫描发现我们的大脑似乎在抑制(首先出现)和监控(似乎是一种更为反射性的操作)之间有明显区别。那么,我们的假设是否应将这种区别考虑在内?上文提及的刘绍龙、王柳琪(2010)提出的非对称性表征模型中,监控被具体化为抑制和决策。根据神经科学家正在探索的镜像神经元理论,Pickering & Garrod(2013)提出了大脑“模拟器”概念:“模拟器”在语言理解和产出过程中都很活跃,在理解过程中模拟产出,反之亦然。但是,这个理论和想法没有充分探索双语翻译者的语言处理方式的影响。尽管我们关于默认直译或干扰定律的一般想法可能没有错,但是为了让翻译学假设更有说服力,且在翻译学领域之外作出贡献,我们还需要不断地将自己的理论和假设与邻近学科正在进行的研究结果相对照。这也是认知翻译学“认知承诺”的体现。
Shreve & Lacruz(2017)指出,虽然翻译强调译者必须理解文本的意义,对转换的初始定义也强调了意义,但是,在许多(即使不是大多数)翻译实例中,在源文本和目标文本之间保持语言形式一定程度上的一致也很重要。平衡意义转换和语言形式一致性的双重目标可能会对翻译过程中原文的言辞再现产生重要影响。事实上,译者对于源语与目标语言之间的一致性的期待可能会影响语言形式信息在言辞表达中得到保留的程度,或者影响通过重读来恢复工作记忆中的语言形式信息的频率,也可能影响保留何种语言形式信息。这似乎是比较实验研究的一个成熟领域,例如,可以测量不同的参与者(例如译者和非译者,新手和专家之间)在给予不同的任务期望时对语言形式信息的回忆。