对验证度之定义的进一步评注
在本节中我们表述验证度C(h,e,b)应当满足的一些进一步条件、要求或需求。(见《逻辑》中的“预设条件”列表,第400页及下页。)正是这些条件以及它们是否一致的问题在起初阶段让我们得到了C(a,b),而后得到C(a,b,c)或我在上文第31节中写成的C(h,e,b)。[23]
(1)最主要的要求是,我们这个概念应当能给出一个假说或理论已经得到检验的程度。几乎所有其他要求(除了那些约定性要求之外)都来自这个核心要求。
(2)理论能被检验的程度越高、越严格,那么它能被验证的程度就越高。因此我们有下述要求:可检验性和可验证性应当是同增同降的——例如它们可以是同比例的。这将使得可验证性与(绝对)逻辑概率成反比;见《逻辑》第34、35和83节。(对于“可验证性”,我指的是被考察的假说在理论上能获得的最高验证度。)
(3)在便利性方面我们可以作一个最简单的约定,即比例因子等于1;换言之,可验证性等于可检验性和经验内容。
(4)重言式——分析句——是不可能被经验检验的。我们可以用下述要求来表述这一点(这个要求来自于前面一个):无论证据为何,重言式的验证度都应当为零,因此其可验证性程度也为零。
(5)自我矛盾的假说当然有着最丰富的内容;因此它也具有最高的可检验性——但仅仅在所有检验都可被视为反驳这个意义上而言。为了处理这个问题,我们既可以将自我矛盾的假说排除掉,也可以作出下述要求:无论证据为何,自我矛盾的假说其验证度值永远都应最小,这也就表明了一种反驳。
(6)考虑到(3)和(4),上述所言的最小值不可能为零,因此我们需要用一个负数来表明自我矛盾的假说这样的不利结果。最简单的约定就是使用-1来刻划在检验中反驳自身的那种假说的验证度。
(7)在上文第(3)点中我们约定比例因子等于1,这一点是非常可取的,因为最具可检验性的假说其验证度的最大值能达到+1。因此在验证度中我们得到了一个对称的边界-1和+1,而0意味着没有验证,这在重言式的例子中已有说明。
(8)现在引入符号“C(a,b)”表示b对a验证度,同时用“Ct(a)”表示a的经验内容或可检验度,那么我们有
Ct(a)=1-p(a)
而我们可以将至今为止所表述的要求表示成
要注意这里的b并不用来表示“背景知识”,稍后我们将用“e”来表示这个意思。
(9)将a的否定写成“ā”,我们就可以说ā反驳了a,因此C(a,ā)=-1。类似地,如果我们将a和b的合取写成“ab”,那么至少当b是一致的时候C(aā,b)=-1,因为aā是一个矛盾陈述。此外,如果证据本身就蕴涵陈述a——例如某一单称假说,那么a就完全被验证。因此一致的a能获得的最大验证度就将是C(a,a)=C(a,ab),也就是说,C(a,a)将等于上文提到过的a的可验证性,并因此而等于a的内容Ct(a)。如果将上面这些都统一到我们的公式之中,并同时只接受一致的证据b的话,我们就有
这决定了C(a,b)的极限。而这里的约定性成份仅仅是下述两个假定:(a)a能获得的最大验证度C(a,a)(因此也是其可验证性)等于其内容Ct(a),而不是仅仅与之成正比;(b)最小验证度(即被反驳的假说的验证度)是最可检验的陈述所能获得的最大验证度的反数;这就意味着它等于-1。
(10)考虑到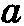
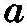 (“非(a和非a)”)是重言式,因此对于所有b我们都有
(“非(a和非a)”)是重言式,因此对于所有b我们都有
(11)在确定了极限和零值之后,现在我们提出下述要求:每一次假说通过新的、真正的检验,假说的验证度应随之而增加,检验越是严格,增加的程度就越大。
假设我们知道b是被设计出来以反驳a的真正尝试,也即b是a的一个真正的检验——那么我们可以依据b的(绝对)非概然性来度量检验b的严格程度。例如,导致海王星发现的亚当斯和勒威耶的预测就是对牛顿理论的绝妙验证,因为能在他俩的计算结果所指定的狭小天空区域中以纯粹意外的方式发现一颗从未有人观察过的行星,这是极端非概然的。另一个令人吃惊的例子是爱因斯坦的日蚀预测,这个预测涉及到了太阳正面大圆[disc]背后出现的恒星之间的角距离。(他的预测指出,这个距离比夜间星空观测所获得的距离要大。)这个预测效应是此前任何人[24]都没有想到过的,而且依据早期理论来看也是极端非概然的。(爱因斯坦的广义相对论两次预测到了实际数据与夜空观测数据的偏差,而牛顿理论无法得出这些结果。)
这些例子都表明我们应当在很大程度上将急剧增长的验证度力量,归功于那些最终被证明是成功的大胆预测的高度非概然性。因此在这些例子中,我们不大可能认为这种预测的成功是因为巧合或偶然:预测的非概然性度量了检验的严格性。在反方向上我们也能应用这个论证:占星术士或算卦者常能取得的那些含糊而有限度的成功,只具有非常少的验证力量,因为随着绝对概率值的增高,它们的精确度就降低了(对照《逻辑》第37节)。这类成功只能是源于巧合(正如我的《逻辑》第83节中论述的)。我的这个论证当然还能解释检验的多样性为何能得出较好的结果,这是因为描述了许多检验的陈述(特别是如果这些检验彼此独立的话)比那种仅仅描述其中某些检验的陈述要更非概然。(因此复合检验较之构成此复合检验的各个检验而言,更非概然,因而也更严格。)我们可以用下述规则来总结这些观点:
(ⅳ) 假设b是a的一个真正的检验,那么C(a,b)随Ct(b)而增长,也就是说,随内容或b的绝对逻辑非概然性而增长;或换言之,随检验b的严格性而增长。
(12)在我们的理论中,上面这个规则或要求在许多方面都是极为重要的。理由之一就是,它不仅对验证度适用,也对概率适用。如果假说a的绝对逻辑概率不为零,同时a能推出或预测出证据b,那么相对于证据b的a的逻辑概率也将随b的绝对非概然性的增长而增长。我们可以将在给定b的前提下a的相对概率记为
p(a,b)
而将a的绝对概率记为
(在这里我们可以将p(a)定义为p(a,a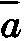 ),也即在不给定任何证据——或只给定重言式——的前提下a的相对概率。)现在我们就能得出对应于(ⅳ)的概率计算规则(这是贝斯定理的一种形式)如下:(ⅳ)p只要p(a)≠0而且可以从a预测b,那么p(a,b)随p(
),也即在不给定任何证据——或只给定重言式——的前提下a的相对概率。)现在我们就能得出对应于(ⅳ)的概率计算规则(这是贝斯定理的一种形式)如下:(ⅳ)p只要p(a)≠0而且可以从a预测b,那么p(a,b)随p(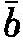 )的增长而增长,也就是说,随非b的绝对概率的增长而增长,而后者也等同于b或b的内容Ct(b)的逻辑非概然性。
)的增长而增长,也就是说,随非b的绝对概率的增长而增长,而后者也等同于b或b的内容Ct(b)的逻辑非概然性。
可以看出这个规则(ⅳ)p精确对应于(ⅳ);而这可能暗示着验证度有可能在根本上是概率——也即它有可能满足概率计算或非常类似这样的计算规则。[25]换言之,(ⅳ)和(ⅳ)p之间的类似关联着我们的两个问题的第一个——验证是否为概率。(对照第30节。)
(13)但这个类似也产生了第二个问题——这里所阐述的要求是否一致。因为我们可以认为(ⅳ)表明了验证即使不是概率,也必定非常类似于概率。但我们的要求(2)——更明确的是(4)——和(ⅲ)一样,都和将验证诠释为概率的说法不相容。因为(4)和(ⅲ)赋予所有重言式的验证度以零值——但重言式却有着最高的概率值1。
因此正是在这里,我们的两个子问题(对照第30节)开始真正显露出重要性。(https://www.daowen.com)
(14)很容易就能表明,我们的要求(2)与验证是概率的观点相矛盾;但要求(2)又是直接从下述根本观念中来的:验证度完全是关于检验的严格性报告。(参见《逻辑》第79节前面的导言。)因此可以表明,(2)及其结论是我们不能放弃的;无论(ⅳ)和(ⅳ)p之间的类似性如何,单凭这一点我们也仍然迫切感到需要证明我们的要求是一致的。
让我们假定可以从陈述a中推出陈述b,但反之不然,同时0≠p(a)<p(b)≠1。在此情形中,存在一个陈述c使得a等价于合取bc,并且0≠p(c)≠1。
因为b的内容仅仅是a的内容的一部分,所以我们有Ct(a) >Ct(b),因此a的可验证性将大于b的可验证性。根据上文(8),这也可以写成C(a,a)>C(b,b)=C(b,bc),或者由于a=bc,我们有
C(abc)>C(bbc).
这个结果可以表述如下
(ⅴ) 如果可以从a推出b,但反之不然,同时0≠p(a)<p(b)≠1,那么存在某一陈述d(例如d可以是合取bc[26],也即a本身)使得
C(a,d)>C(b,d)
这个规则适用于验证度。但对应于概率这个规则是假的。不仅如此,适用于概率的恰是此规则的否定。因此我们有下述规则,它也是概率计算中的一个定理:
(ⅴ)p 如果可以从a推出b,但反之不然,同时0≠p(a)<p(b)≠1,那么对于所有陈述d我们都有
p(a,d)≤p(b,d)
正是(ⅴ)和(ⅴ)p之间的冲突体现了验证度和概率之间的冲突。但(ⅴ)直接来自于我们的根本要求“验证度是关于检验的严格性报告”,以及“可检验性等于可验证性”。(如果我们转而采用“成正比”甚或仅仅以“随……增加”来代替“等于”,那么情况依然不变。)
(15)这里描述的问题情境是下述最低要求的形式结果:验证度是关于检验及其严格性的报告。而(ⅴ)正是从理论上阐释了第27节(1)中对麦克斯韦和菲涅耳的理论所做的直观解释;我们可以令a为麦克斯韦理论,b为菲涅耳理论,而d为针对麦克斯韦理论的电磁学部分的某一检验(例如赫兹实验),或是一个这类检验和一个同时适用于两个理论的检验(例如双折射实验或斐索[Fizeau]实验)的合取。
(16)我们至今讨论的所有条件,除了(3)和(6)提到的条件之外,都是从我们的下述根本原则中得来的:验证度是关于某一理论已然经受的检验的严格性报告。但现在我们要加入一个新概念。
令a是某一假说,而b是另一个由a演绎出来的较弱假说。(我们可以再次令a是麦克斯韦理论,而b是菲涅耳理论。)现在假定我们已经用检验x(菲索实验或双折射实验)检验了b,但没有检验a中超出b的那些部分。在此情形中,即使a的可验证性较大,我们也仍然有C(a,x)<C(b,x)。因为a包含了另一些迄今未被检验的部分,它们有可能在下一次检验中就被反驳。但只要这些部分也能成功地通过足够严格的x(例如实际中它们就能通过赫兹实验),那么我们就有C(a,x)>C(b,x)。
我们可以从其他角度来考虑这个例子。例如我们可以说,如果x良好地验证了b,同时我们又给b增加了全新的部分c,而这部分内容是无法被x检验的,那么所得的结果a=bc被x检验的良好程度就小于b被x检验的程度,因此前者被x验证的良好程度也小于b被x验证的程度;但另一方面,前者的验证在下述条件下将超出b的验证:能对c——即a超出b的部分——作出一些严格的检验。我们可以将这些表示为下述要求:
如果b对x的解释程度至少等同于a=bc对x的解释程度,那么C(a,x)<C(b,x)。这里我们可以用“b使x成为概然”来替换“b对x所作出的解释”。因此我们有下面的表述形式:
(ⅵ) 如果可以从a推出b;如果0≤p(a)<p(b)<1;又如果p(x,b)≥p(x,a),那么
显然上述要求和(ⅲ)一样,都表明验证度类似于概率。因为下述类似的公式正是从概率计算中得来:
(ⅵ)p 如果可以从a推出b;如果0≤p(a)<p(b)<1;又如果p(x,b)≥p(x,a),那么
从这个新要求来看,我们的(第30节中的)两个问题变得愈加迫切。
这些要求都是我们要加以考虑的。一开始我找到了一个C(a,b)的定义能满足所有这些要求,此定义借助了相对于b的a的解释力的一个高度直观的定义。(见上一节注1。)后来我又找到了另一个更简单的定义,如下所述。(见第31节定义D。)
(ⅶ) 令a是一个一致的[27]假说,而b描述了我们反驳a的所有尝试的结果,因而p(b)≠0。那么我们有
借助唯一的假定“p满足概率计算”,可以看到我们的所有要求都得到了满足;这个定义是一致的,因此这些要求组成的要求集也是一致的;同时C(a,b)和p(a,b)不一样。因为C(a,b)不像p(a,b)那样满足概率计算规则。
因此我们的两个问题都解决了。同时我认为我们的定义(ⅶ)不仅有改进的余地,而且这种改进也是我们所需要的。
首先我们可以推广我们的定义,方法是引入第三个变量c,它表示我们的背景知识。[28](这在第31节中表示为“b”。)这样一来我们就得到:
(ⅷ) 令a是一个(一致的)[29]假说,b描述了我们反驳a的所有尝试结果,而c是我们的(一致的)[30]背景知识,其中包含着未经检验的理论和初始条件。那么我们有
这精确对应于第31节的定义D,在那一节中我们是用稍微不同的论证得到此定义的。
对于这两个定义(ⅶ)和(ⅷ),我要补充一些技术性细节。它们的基础是p(b,a)——R.A.菲舍尔称之为a对b的似然——而非p(a,b)。这一点非常重要,因为在这种情况下即便p(a)=0它们也仍然保有完全的意义;在《逻辑》第80和81节中我指出,如果a是全称理论,那么一般情况下我们就要假定p(a)=0。[31]这是因为根据通常的观点,在某一无穷论域中(对时间或空间而言都是无穷的)全称理论都是单称陈述的无穷产物,因而也都是“无穷非概然的”,更精确地说,都具有零概率值。处理这个局面对我们的理论来说并不困难,因为事实上我已对通常的概率计算作了推广,使得哪怕是p(y)=0时p(x,y)都能有意义。(参见《逻辑》附录*ⅳ。)这样一来,在(ⅶ)和(ⅷ)定义项中,即使a(和c)都是零概率的定律,“p(b,a)”或“p(b,ac)”以及“p(b,c)”这些表达式也都是有意义的。如果在(ⅶ)的定义项中我们用“p(a,b)”来代替“p(b,a)”的话,那么对于任何全称定律a我们都会得到C(a,b)=0/0;因为在此情形中p(a,b)-p(a)将等于零,而p(a,b)+p(a)也将等于零。[32]认识到这点极为重要,而且通过引入“背景知识”c当然能够将其推广,并扩展到(ⅷ)。
我要作出的第二个改进是这样的。我们应当可以更明确地表达一下这个非正式的要求或条件:b必须包含证伪a的真正尝试。正如第31节所讲的,我们可以通过下述要求来部分地形式化它:从我们的背景知识来看,我们的经验检验陈述应当是非期望的或非概然的;也就是说,在给定背景知识的前提下,它们的概率应当(远远)小于½。
在我看来,我们无法避免定义中的一个直观因素,它等同于下述条件:“C(a,b)”中的“b”描述着真正的检验结果。因为我们的意图是让C(a,b)来表示理论的可接受性之类的东西,也即对理论的有用的、可行的和令人信服的评估。换言之,我们要处理的不是一个未经诠释的形式表述,而是一个已经诠释的形式表述;而在这里面非正式的或直观的因素仅仅起到了一种警告作用:“如果你打算将C(a,b)或C(a,b,c)诠释为理论a的验证度(或可接受度),那么你必须确保b描述了真正的检验结果。”[33]总而言之,我想指出的是以下两点。第一,我们的验证度概念必须要(这也是自动地)彻底考虑到证据的权重[weight of evidence],而正是这一点给概率理论带来了极大麻烦。[34]第二,我们的定义是一个令人满意的结果,而且是相当好的结果,这不仅反映在麦克斯韦和菲涅耳的例子中,也反映在爱因斯坦和牛顿的例子中。它甚至能允许我们充分表达日蚀观测结果的略微可疑的性质,同时还能表述这些结果更有利于爱因斯坦理论而非牛顿理论。理由是这样的:如果a1是牛顿理论,a2是爱因斯坦理论,而b是日蚀测量数据,那么我们肯定能得到
这是因为b超出牛顿预测的程度比它超出爱因斯坦预测的程度更大。从这一点我们马上就能知道b对爱因斯坦理论的验证程度比它对牛顿理论的验证程度要高——这也和常识以及人们的普遍观点相符合。
而能得出这样的结果,并不是因为我们的理论有什么特别奥妙之处,而是因为一个简单的事实——我们的定义能满足我们的要求。它非常直接地评估了假说已经经受的检验的严格性,以及假说经受检验的良好程度——或是假说未能通过检验的糟糕程度。
我想再次重申,我一直认为,如果说我的验证度定义能对科学作出什么贡献的话,那也就是它能适用于理论的评估或统计而已。(对照《逻辑》附录*ⅸ。)另一方面,我不相信除了在下述意义之外,它还能对方法论或哲学作出什么肯定性贡献:它将帮助我们(或者说我希望它能帮助我们)厘清由归纳偏见所带来的巨大混乱局面,正是因为这种偏见,人们才会认为科学的目的就在于(概率计算意义上的)高概率,而不是在于丰富的内容和严格的检验。