风险分析的主要方法
(一)风险解析法
风险解析法,也称风险结构分解法,是风险识别的主要方法之一,它是将一个复杂系统分解为若干子系统进行分析的常用方法,通过对子系统的分析进而把握整个系统的特征。例如,我们可以将市场风险解析成如图11-4所示。
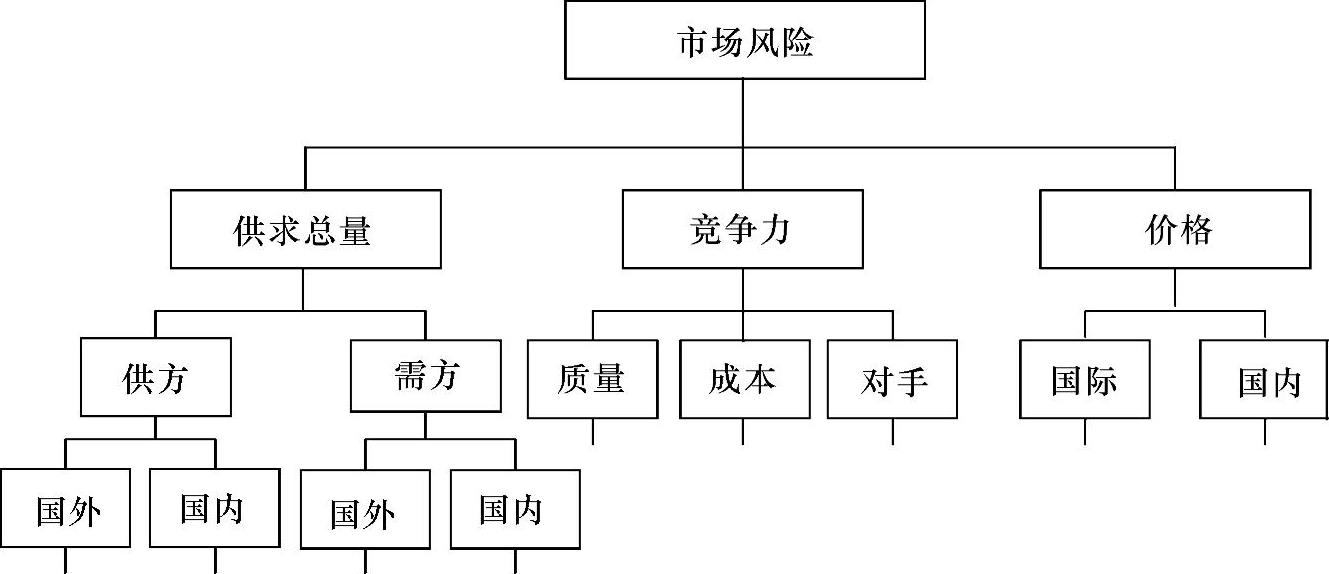
图11-4 市场风险解析图
(二)专家调查法
专家调查法是基于专家的知识、经验和直觉,通过发函、开会或其他形式向专家进行调查,将多位专家的经验集中起来形成分析结论,从而发现项目潜在风险,对项目风险因素及其风险大小进行评定的一种方法,它适用于风险分析的全过程。
采用专家调查法时,所聘请的专家应熟悉该行业和所评估的风险因素,并能做到客观公正。为减少主观性,专家人数一般应在10~20位。
专家调查法有很多,如头脑风暴法、德尔菲法、风险识别调查表、风险对照检查表和风险评价表等,前两者在第四部分第1章进行了有关介绍,这里只介绍后三种方法。
1.风险识别调查表
该表主要定性描述风险的来源与类型、风险特征、对项目目标的影响等。
2.风险对照检查表
该表是一种规范化的定性风险分析工具,具有系统、全面、简单、快捷、高效等优点。容易集中专家的智慧和意见,不容易遗漏主要风险;能启发和开拓风险分析人员的思路。
对照检查表的设计和确定需要大量类似项目的数据,而新项目或完全不同环境下的项目应用此法则偏差较大。国际上许多项目管理组织如美国项目管理学会、欧洲国际项目管理协会等都制定了规范的风险清单,大大提高了风险识别的工作效率。
3.风险评价表
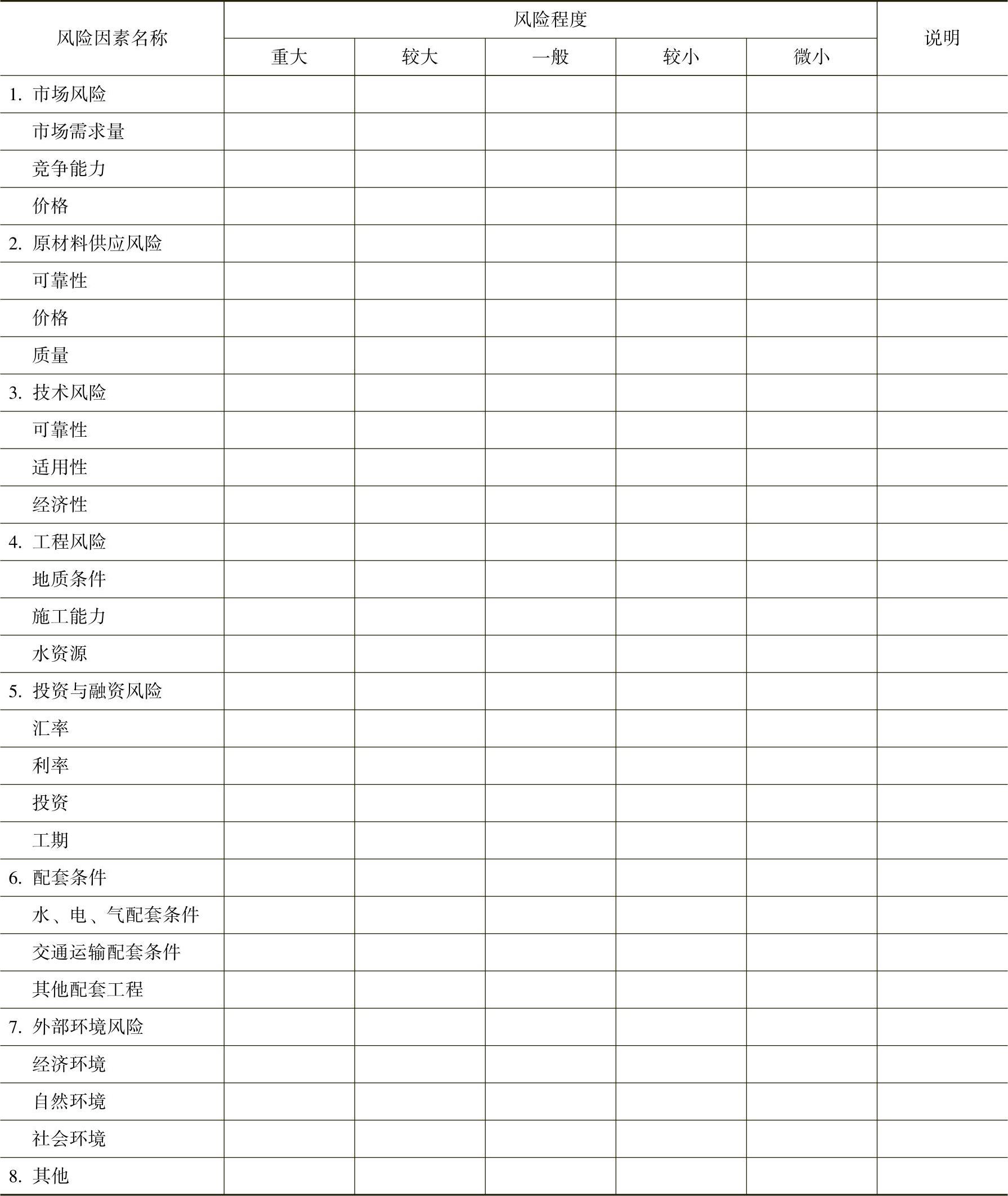
风险评价表是通过专家凭借经验独立地对各类风险因素的风险程度进行评价,最后将各位专家的意见归集起来。风险评价表通常的格式见表11-4,表中风险种类应随行业和项目特点而异,其层次可视情况细分,同时重在说明,说明中应对程度判定的理由进行描述,并尽可能明确最悲观情况及其发生的可能性。
表11-4 风险评价表示例
(三)风险概率估计
风险概率估计,包括客观概率估计和主观概率估计。在项目评价中,风险概率估计较常用正态分布、三角形分布、贝塔分布等概率分布形式,由项目评价人员或专家估计。
1.客观概率估计
客观概率是实际发生的概率,并不取决于人的主观意志,可以根据历史统计数据或是大量的试验来推定,有两种方法:一是将一个事件分解为若干子事件,通过计算子事件的概率来获得主要事件的概率;另一方法是通过足够多的试验,统计出事件的概率。
应用客观概率对项目风险进行的估计称为客观估计,它利用同一事件的历史数据,或是类似事件的数据资料,计算出客观概率。该方法只能用于完全可重复事件,因而并不适用于大部分现实事件,其最大缺点是需要足够的信息,但通常是做不到的。
2.主观概率估计
主观概率是基于个人经验、预感或直觉而估算出来的概率,是一种个人的主观判断。当有效统计数据不足或是不可能进行试验时,主观概率是唯一选择。基于经验、知识或类似事件比较的专家推断概率可看做是一种主观估计(可认为是专家调查法在风险分析中的应用)。主观概率的专家估计的具体步骤如下:
1)根据需要调查问题的性质组成专家组。专家组成员由熟悉该风险因素的现状和发展趋势的专家、有经验的工作人员组成。
2)查某一变量可能出现的状态数和各种状态出现的概率,或可能的状态范围和变量在状态范围内的概率,由每个专家独立使用书面形式反映出来。
3)整理专家组成员的意见,计算专家意见的期望值和意见分歧情况,反馈给专家组。
4)专家组讨论并分析意见分歧的原因。由专家组成员重复进行背靠背的独立估计,直至专家意见分歧程度满足要求值为止。这个循环过程最多经历三次,否则会引起专家的厌烦而不利于获得真实意见。
3.风险概率分布
(1)离散型概率分布 当输入变量可能值是有限个数,称这种随机变量为离散型随机变量。如产品市场销售量可能存在低、中、高三种状态,即可认为是离散型随机变量。
(2)连续型概率分布 当输入变量的取值充满一个区间,无法按一定次序一一列举出来时,称这种随机变量为连续型随机变量。如市场需求量在某一数量范围内,存在无限多个可能,这时即可认为是连续型随机变量,它的概率分布用概率密度和分布函数表示,常用的连续概率分布有:
1)正态分布。正态分布是一种最常用的概率分布,适用于描述一般经济变量的概率分布,如销售量、售价、产品成本等。其特点是密度函数以均值为中心对称分布,如图11-5所示。其均值为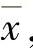 ,方差为σ2,用N(
,方差为σ2,用N(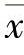 ,σ)表示。当
,σ)表示。当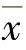 =0,σ=1时,称为标准正态分布,用N(0,1)表示。
=0,σ=1时,称为标准正态分布,用N(0,1)表示。
2)三角形分布。其特点是密度数是由最悲观值、最可能值和最乐观值构成的对称的或不对称的三角形,如图11-6所示。适用于描述工期、投资等不对称分布的输入变量,也可用于描述产量、成本等对称分布的输入变量。
3)β分布。其特点是密度函数为在最大值两边的不对称分布,如图11-7所示,适用于描述工期等不对称分布的变量。
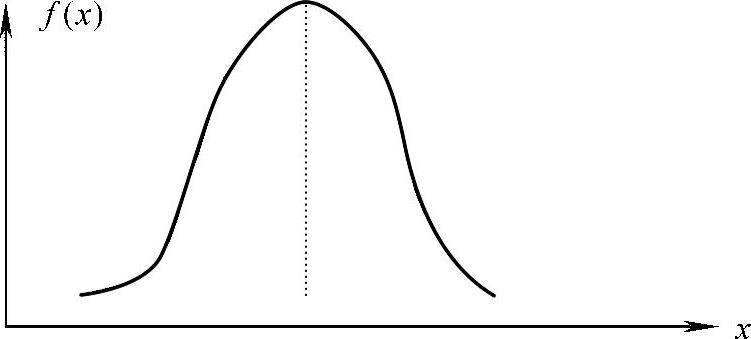
图11-5 正态分布概率密度图
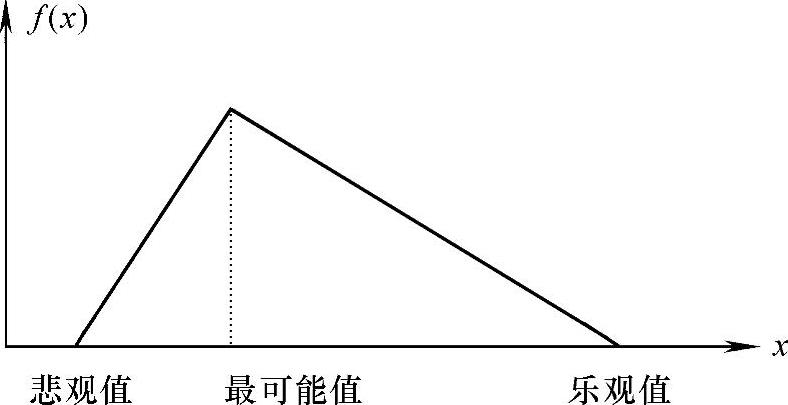
图11-6 三角形分布概率密度图
4)经验分布。其密度函数并不适合于某些标准的概率函数,可根据统计资料及主观经验估计形成非标准概率分布,它适合于项目评价中的所有各种变量。
图11-7 β分布概率密度图
(3)风险概率分析指标 描述风险概率分布的指标主要有期望值、方差、标准差、离散系数等。
1)期望值 是风险变量的加权平均值。对于离散型风险变量,期望值为
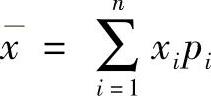
其中 n——风险变量的状态数;
xi——风险变量的第i种状态下变量的值;
pi——风险变量的第i种状态出现的概率。对于等概率的离散随机变量,其期望值为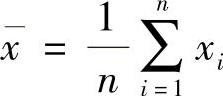 。
。
2)方差和标准差 都是描述风险变量偏离期望值程度的绝对指标。对于离散变量,方差S2为
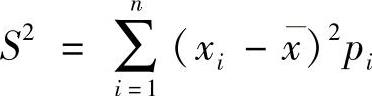
方差的平方根为标准差,计为S。
对于等概率的离散随机变量,方差为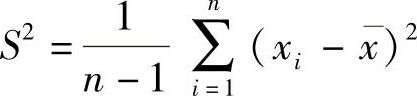 ,
,
当n足够大(通常n大于30)时,可以近似为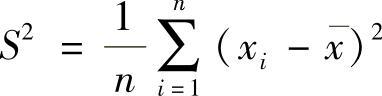 。
。
3)离散系数 是描述风险变量偏离期望值的离散程度的相对指标,计为β: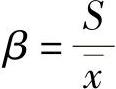
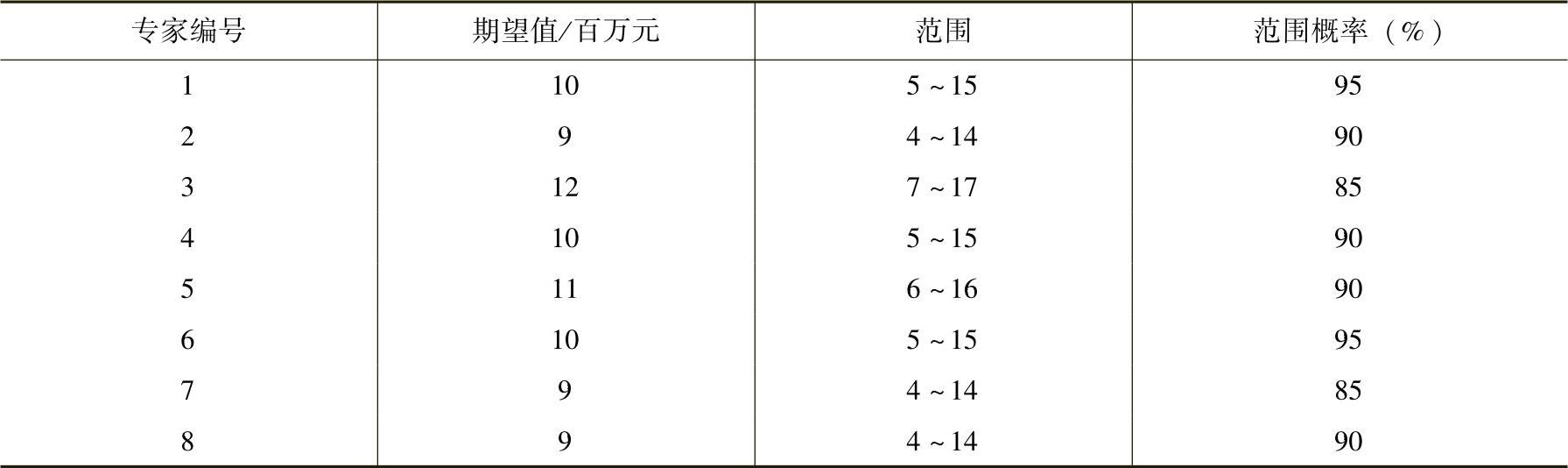
【例11-2】 专家估计理想状态下某产品的年利润服从正态分布,8位专家对利润额可能出现的状态范围及概率进行估计,调查结果见表11-5。
【问题】 (1)计算专家估计值的期望值及期望值的方差、标准差和离散系数。
(2)计算利润额的正态分布指标。
【解答】 (1)首先计算专家估计值的期望值和期望值的方差、标准差和离散系数。
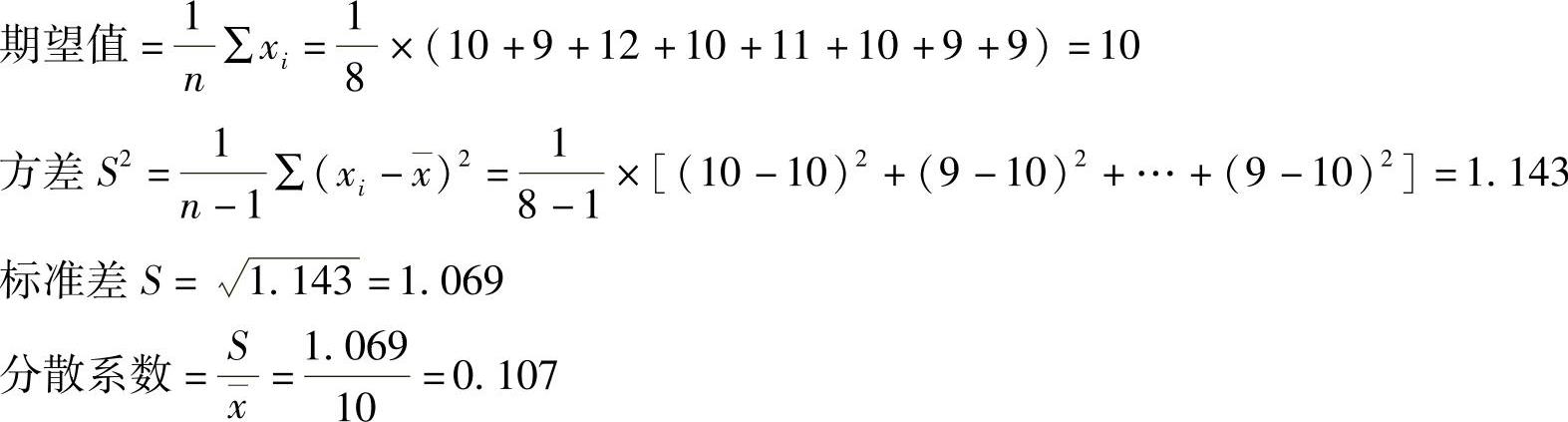
表11-5 专家估计调查意见表
(2)其次,计算各专家估计的正态分布的标准差σ。
以第1位专家估计值为例,认为利润额在5~15百万元范围内的概率为95%,即在该范围之外的概率为5%。如图11-8所示,利润额小于5百万元的概率为2.5%,大于15百万元的概率为2.5%,也即是利润额大于5百万元的累计概率为0.975。
任一正态分布的概率计算都可转换为标准正态分布来计算,公式为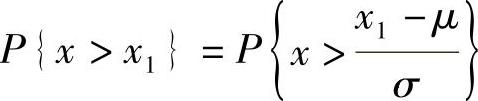 ,其中μ为期望值,σ为标准差,P表示概率。
,其中μ为期望值,σ为标准差,P表示概率。
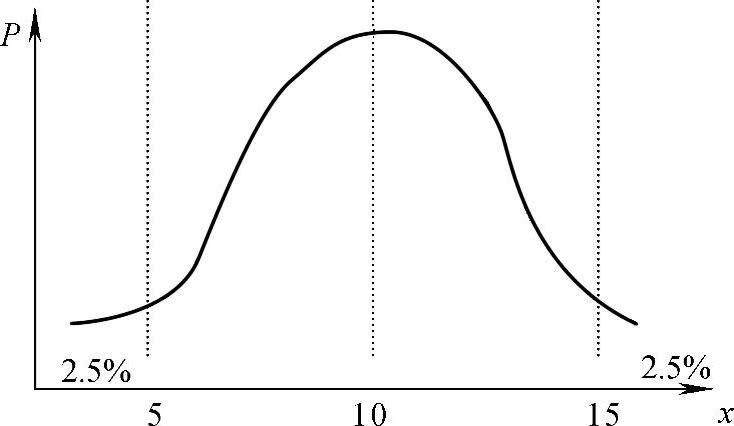
图11-8 正态分布概率估计图
通过查标准正态分布函数表,对应0.975的x值为1.96,则: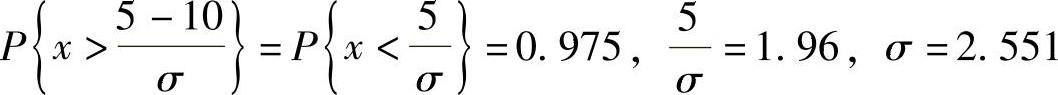 。
。
依此类推,可计算8位专家对该项目利润额的期望值与标准差的估计值,见表11-6。
表11-6 专家估计分析表

从表11-6可计算各专家估计的正态分布的标准差的平均值为3.026。
(3)因此,产品价格的概率分布服从期望值为10、标准差为3.026的正态分布。
(四)概率树分析
概率树分析是假定风险变量之间是相互独立的,在构造概率树的基础上,分析判断每个风险变量的各种状态取值,分别计算每种组合状态下的评价指标值及相应的概率,得到评价指标的概率分布,并统计出评价指标值低于或高于基准值的累计概率,同时计算评价指标值的期望值、方差、标准差和离散系数。还可以绘制以评价指标为横轴,累计概率为纵轴的累计概率曲线。
概率树分析的计算方法一般只使用于服从离散分布的输入与输出变量(这里的输入变量就是指风险变量)。计算步骤如下:
1)通过敏感性分析,确定风险变量;判断风险变量可能发生的状态。
设风险变量有A、B、C、…N,变量之间相互独立;各风险变量可能发生的状态有:
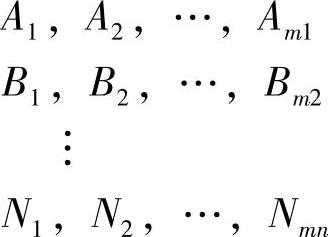
2)确定每种状态可能发生的概率,概率之和必须等于1;列出相应的联合概率。
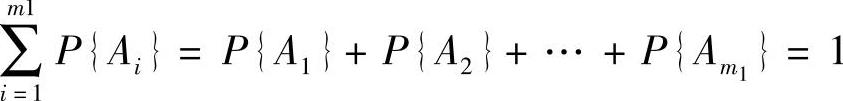

各状态组合的联合概率为:P{A1}×P{B1}×…×P{N1},P{A2}×P{B2}×…×P{N2},…,P{Am1}×P{Bm2}×…×P{Nmn},共有这种状态组合和相应的联合概率m1×m2×…×mn个。
3)评价指标(通常选择净现值或内部收益率)从小到大排序,构造概率树,列出相应的联合概率和累计概率,并绘制评价指标为横轴、累计概率为纵轴的累计概率曲线;计算评价指标的期望值、方差、标准差和离散系数。
4)可利用累计概率表求出:
P{NPV(ic)≥0}=1-P{NPV(ic)<0}或P{IRR≥ic}=1-P{IRR<ic}
注意:当输入变量和每个变量可取的状态数多于3个时,这时状态组合数过多,一般不适合用概率树计算法;若各个风险变量之间不是独立的而是存在相互关联关系,也不适合用这种方法。
【例11-3】 某项目有4个主要风险变量:固定资产投资、年经营成本、年销售收入和项目寿命,数据及其概率分布见表11-7。贴现率取10%(假定当年建成当年达产)。
表11-7 主要风险变量数据及其概率分布表

(续)

【问题】(1)计算该项目净现值的期望值。
(2)计算净现值≥0的累计概率。
【解答】(1)计算净现值的期望值
1)列出各参数不同取值的所有组合,并计算每种组合下方案的净现值及其相应的组合概率。
2)根据每组组合下的净现值及其相应的组合概率,计算项目净现值的期望值。
计算步骤及其结果可以用树形图的形式加以表示,如图11-9所示。
3)以第一事件为例,计算如下:
组合概率P1=1×1×0.3×0.2=0.06
净现值X1=-80000-12000(P/A,10%,18)+20000(P/A,10%,18)=-14388.8万元
净现值加权值=X1×P1=-863.328万元
其他数值计算同理,填入图11-9中。
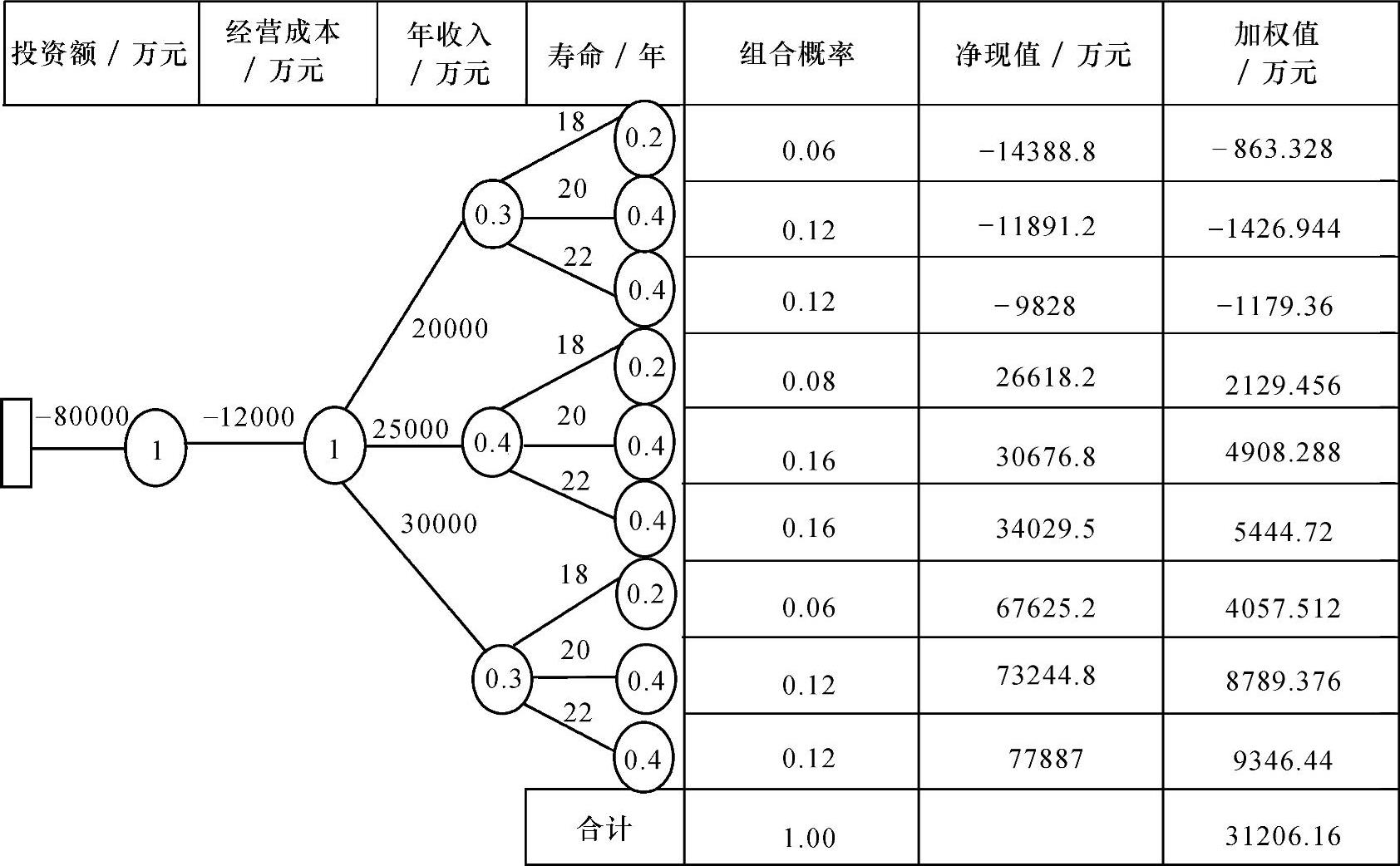
图11-9 概率分析树形图
4)根据图表中所列Xj与Pj数据值,根据公式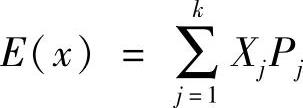 ,可得该项目净现值的期望值为31206.16万元。
,可得该项目净现值的期望值为31206.16万元。
(2)净现值≥0的概率=(1-0.3)×100%=70%
【解题思路】本题考查概率树的构建以及评价指标的计算,要熟悉概率树计算方法的分析过程和步骤,逐步进行计算。
(五)蒙特卡洛模拟
这种方法的原理是用随机抽样的方法抽取一组输入变量的数值,并根据这组输入变量的数值计算项目评价指标,如内部收益率、净现值等,通过多次抽样可获得评价指标的概率分布及累计概率分布、期望值、方差、标准差,计算项目由可行转变为不可行的概率,从而估计项目投资所承担的风险。
1.应用条件
当输入的随机变量个数多于3个,每个输入变量可能出现3个以上以至无限多种状态时(如连续随机变量)。
2.蒙特卡洛模拟的程序
1)确定风险分析所采用的评价指标。
2)确定对项目评价指标有重要影响的输入变量。
3)经调查确定输入变量的概率分布。
4)为各输入变量独立抽取随机数。
5)由抽得的随机数转化为各输入变量的抽样值。
6)根据抽得的各输入随机变量的抽样值组成一组项目评价基础数据。
7)根据抽样值组成的基础数据计算出评价指标值。
8)重复第4)步到第7)步,直至预定模拟次数。
9)整理模拟结果计算评价指标的期望值、方差、标准差和概率分布,绘制累计概率图。
10)计算项目由可行转变为不可行的概率。
3.应用蒙特卡洛模拟法时应注意的问题
1)应用此方法时,假设输入变量之间是相互独立的,在风险分析中会遇到输入变量的分解程度问题。
如果变量分解得越细,输入变量个数也就越多,模拟结果的可靠性也就越高;而变量分解程度低,变量个数少,模拟可靠性降低,但能较快获得模拟结果。
如果输入变量本来是相关的,而模拟中视为独立地进行抽样,就可能导致错误的结论。为避免此问题,可采用以下办法处理:①限制输入变量的分解程度;②限制不确定变量个数;③进一步搜集有关信息,确定变量之间的相关性,建立函数关系。
2)根据不确定变量的个数和变量的分解程度确定模拟次数。
(六)风险综合评价法
风险综合评价有许多方法,这里介绍一种最常用、最简单的分析方法。通过调查专家的意见,获得风险因素的权重和发生概率,进而获得项目的整体风险程度。其步骤主要包括:
1)建立风险调查表。在风险识别完成后,建立投资项目主要风险清单,将该投资项目可能遇到的所有重要风险全部列入表中。
2)判断风险权重。利用专家经验,对这些风险因素的重要性,及风险对项目的影响大小进行评价,计算各风险因素的权重。
3)确定每个风险发生概率。可以采用1~5标度,分别表示可能性很小、较小、中等、较大、很大,代表5种程度。
4)计算每个风险因素的等级。将每个风险的权重与发生可能性相乘,所得分值即为每个风险因素的等级。
5)最后将风险调查表中全部风险因素的等级相加,得出整个项目的综合风险等级。分值越高,项目的整体风险越大。